A avaliação do repasse externo é uma ferramenta fundamental para os profissionais que lidam com questões relacionadas à inflação e à política monetária no contexto brasileiro. Neste cenário, mostramos como a linguagem de programação Python facilita todo o processo de coleta, tratamento de dados e estimação do efeito do repasse externo sobre a inflação doméstica.
Existem diversas abordagens metodológicas disponíveis para estimar o repasse externo, que variam desde modelos complexos, como os Modelos de Equilíbrio Geral Dinâmico Estocástico (DSGE), até abordagens mais simples que se baseiam em versões simplificadas das Curvas de Phillips, derivadas de modelos estruturais de menor porte.
O propósito deste exercício é fornecer uma medida do impacto das variáveis externas na inflação doméstica, utilizando um modelo inspirado na forma simplificada da Curva de Phillips do Modelo Semiestrutural de Pequeno Porte do Banco Central do Brasil (BCB).
O modelo fundamental utilizado é o seguinte:
![\[\pi_t^{nucleo} = \sum_{i>0} \beta_{1i} E_t \pi^{total}_{t+i} +\sum_{j>0} \beta_{2j} \pi^{nucleo}_{t-j} +\sum_{k \geq 0} \beta_{3k} \pi^{importada}_{t-k} + \sum_{l>0} \beta_{4l} hiato_{t-l} + \epsilon_t\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-d80d4bd6a45f09c2bb9b7ef902f07e92_l3.png "Rendered by QuickLaTeX.com")
Em essência, esse modelo descreve a inflação dos preços, excluindo alimentos e produtos administrados, como uma função linear de fatores como a inflação passada, as expectativas de inflação, a diferença entre a produção atual e a produção potencial, e a influência da inflação importada.
A estimação do modelo é realizada por meio do método Generalized Method of Moments (GMM). As variáveis utilizadas no modelo são:
- Hiato do Produto - BCB
- IC-Br USD (Var. %. Trim.) - BCB
- Expectativa de 12 meses do IPCA Total (a.a%) - BCB
- IPCA EX01 (a.a%) - BCB
Os alunos do curso de Macroeconometria usando o Python, têm a oportunidade de adquirir um conhecimento abrangente em todas as fases do processo, desde a coleta e a preparação dos dados até a análise, o desenvolvimento de modelos econométricos e a comunicação dos resultados, tudo isso utilizando Python como ferramenta principal.
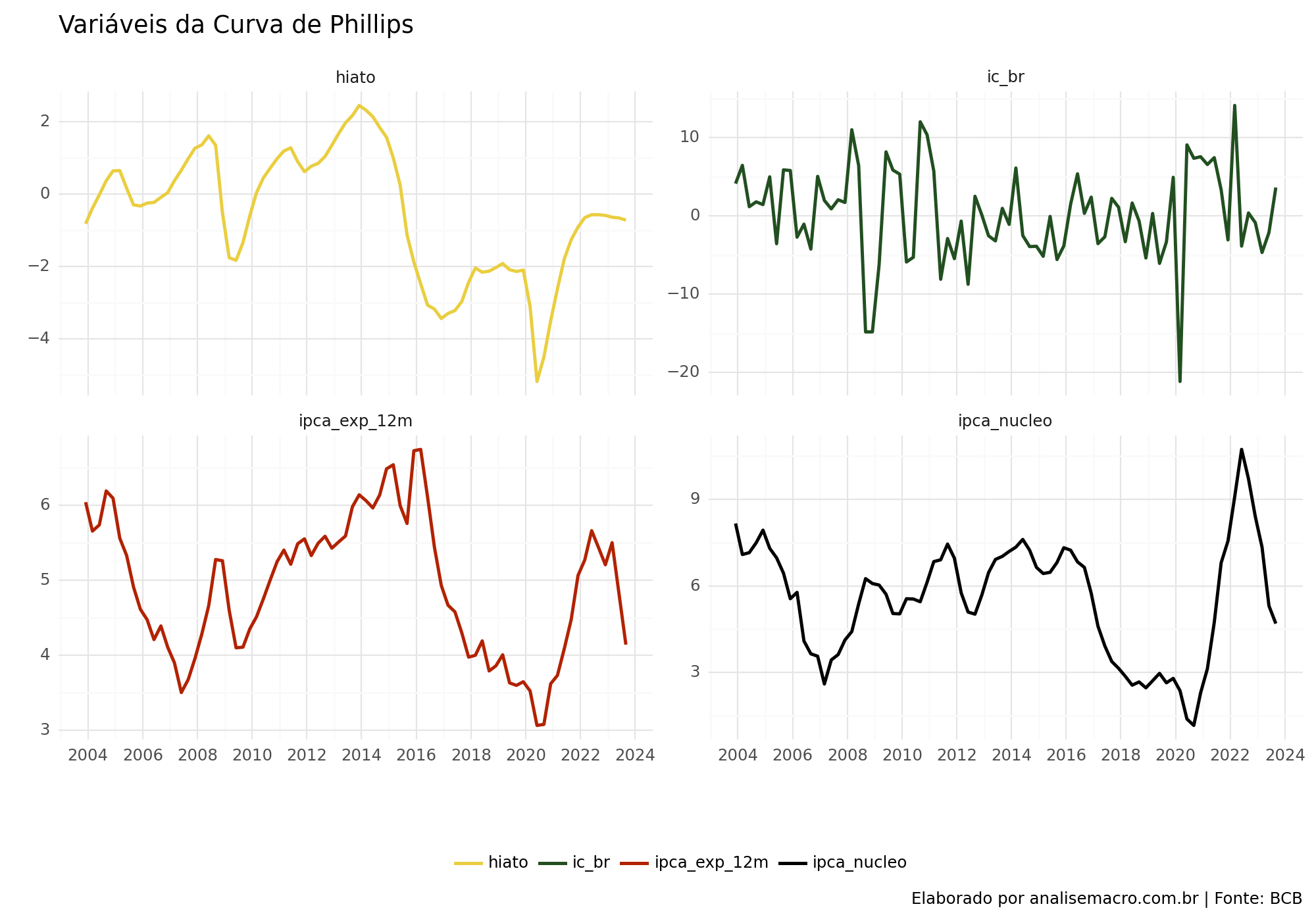
Variáveis
A seguir, apresentamos um gráfico que exibe as variáveis empregadas no modelo.
Sumário do Modelo
O modelo foi desenvolvido com base no Generalized Method of Moments (GMM) com o objetivo de mitigar o problema de endogeneidade. Importante ressaltar que nenhum instrumento foi empregado.
Analisando os resultados a seguir, observamos que todos os parâmetros estimados mostraram significância estatística. Quando se trata do IC-BR em USD, que representa o impacto externo na inflação, o coeficiente encontrado foi de 0,0474, o valor mais baixo entre as variáveis, indicando um impacto relativamente menor.
Código
IV-GMM Estimation Summary
==============================================================================
Dep. Variable: ipca_nucleo R-squared: 0.9887
Estimator: IV-GMM Adj. R-squared: 0.9881
No. Observations: 79 F-statistic: 9434.6
Date: Thu, Oct 19 2023 P-value (F-stat) 0.0000
Time: 20:41:44 Distribution: chi2(4)
Cov. Estimator: robust
Parameter Estimates
====================================================================================
Parameter Std. Err. T-stat P-value Lower CI Upper CI
------------------------------------------------------------------------------------
ipca_nucleo_lag1 0.7681 0.0626 12.270 0.0000 0.6454 0.8908
ipca_exp_12m 0.2650 0.0676 3.9208 0.0001 0.1325 0.3975
hiato_lag1 0.1037 0.0331 3.1330 0.0017 0.0388 0.1685
ic_br_lag1 0.0474 0.0129 3.6650 0.0002 0.0220 0.0727
====================================================================================Ajuste do Modelo
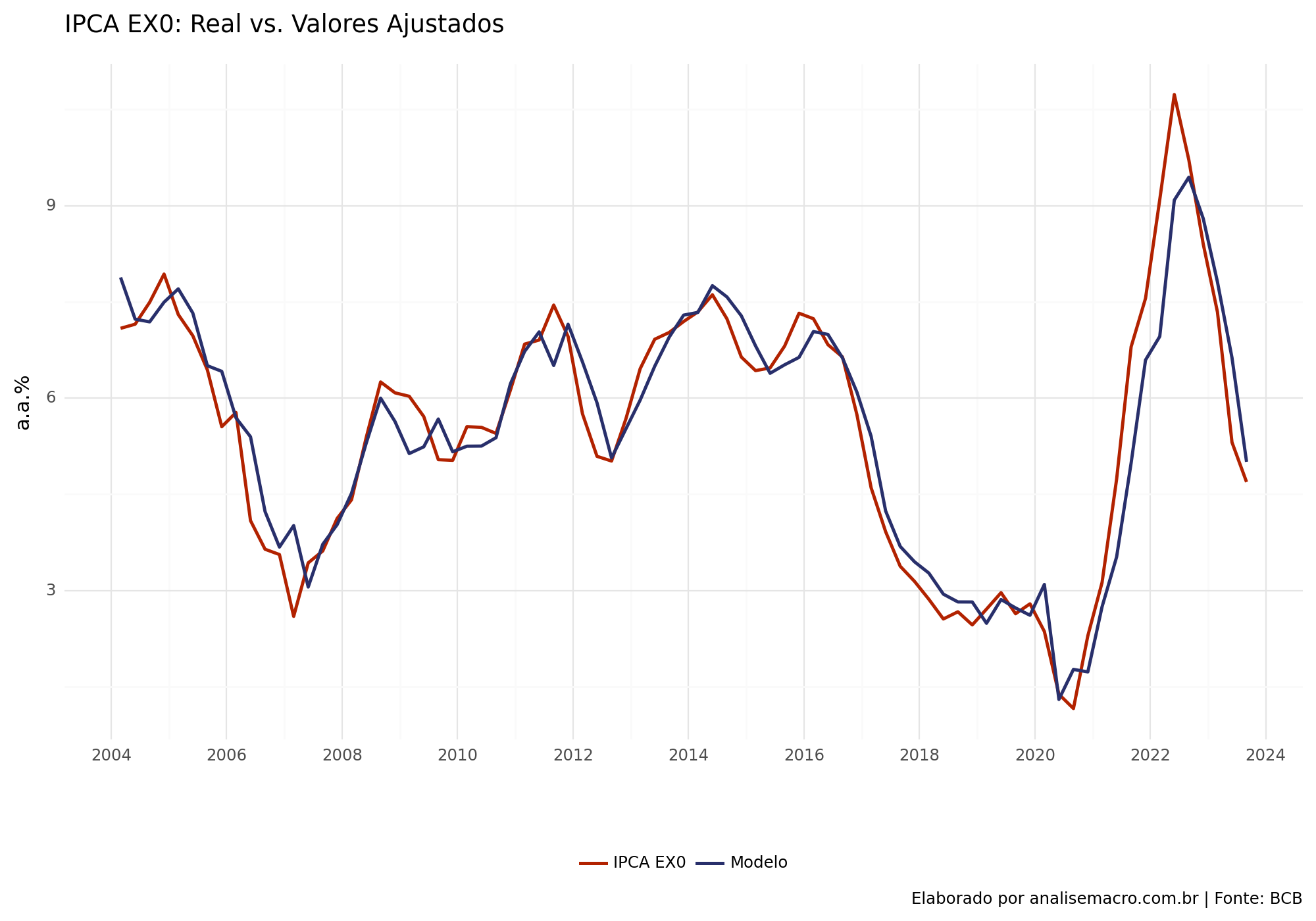
Podemos criar um gráfico para avaliar o ajuste do modelo, comparando-o com os resultados reais do núcleo da inflação. É evidente que alcançamos um ajuste satisfatório.
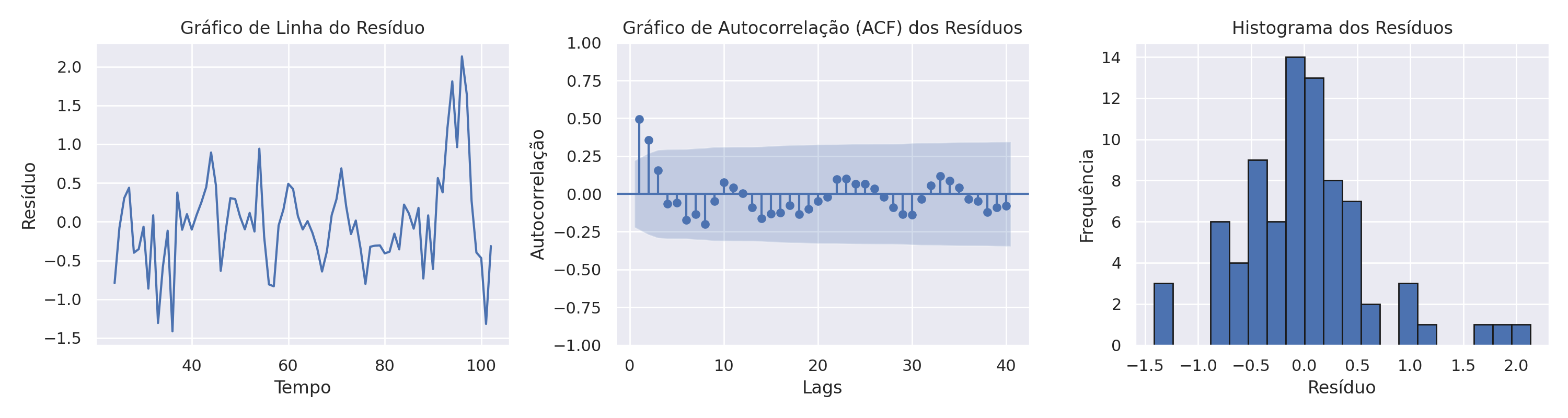
 Análise de Resíduos
Análise de Resíduos
Para avaliar a qualidade do modelo, procedemos com a análise dos resíduos. Recorremos a gráficos de linha, à função de autocorrelação (ACF) e ao histograma, a fim de avaliar a normalidade, a estacionariedade e a presença de autocorrelação nos resíduos. Infelizmente, os resultados não atingiram o nível desejado, no entanto, optamos por continuar com o exercício.
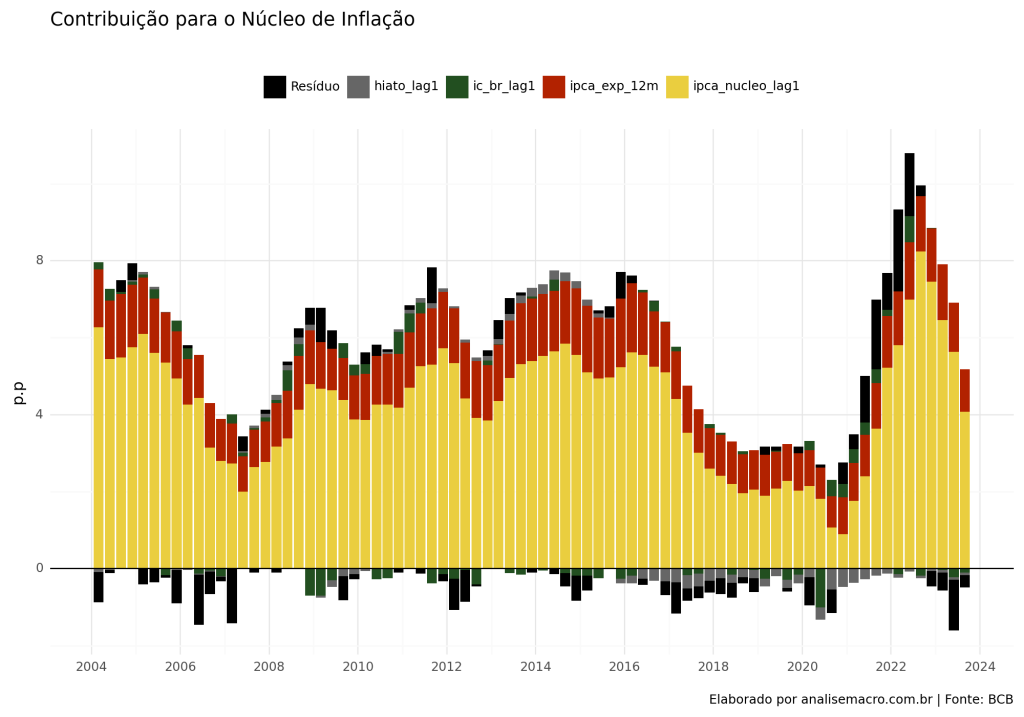
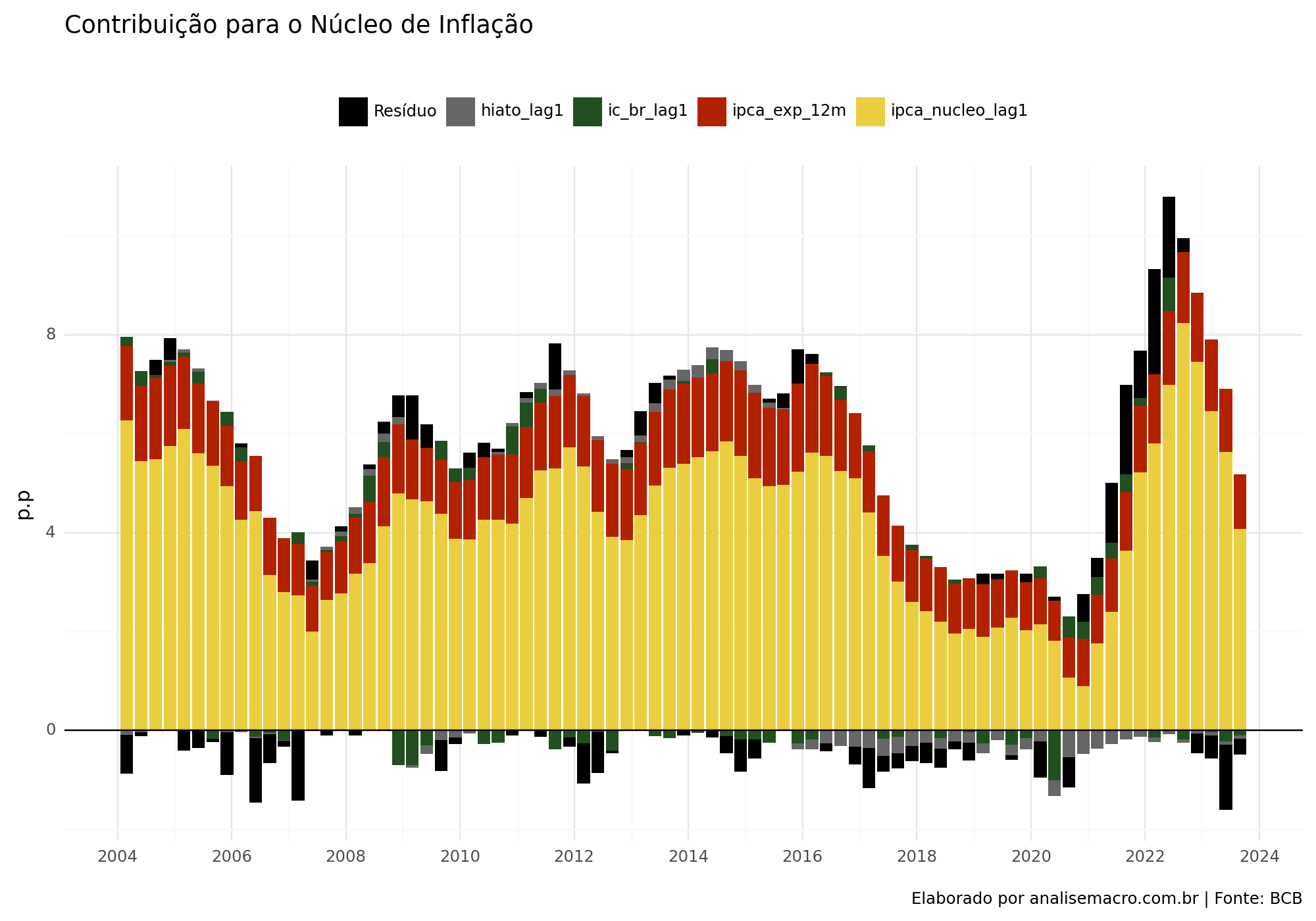
Contribuição para o Núcleo de Inflação
Para avaliar o impacto de cada variável sobre o Núcleo de Inflação, aplicamos os parâmetros estimados, multiplicando-os pelos valores reais do IPCA EX0. No gráfico a seguir, podemos observar que a inércia desempenha um papel significativo na inflação, enquanto o repasse externo, destacado em verde, tem uma contribuição relativamente baixa na maior parte da amostra.
Quer aprender mais?
Clique aqui para fazer seu cadastro no Boletim AM e baixar o código que produziu este exercício, além de receber novos exercícios com exemplos reais de análise de dados envolvendo as áreas de Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas diretamente em seu e-mail.

