[et_pb_section admin_label="section"][et_pb_row admin_label="row"][et_pb_column type="4_4"][et_pb_text admin_label="Texto" background_layout="light" text_orientation="justified" text_font="Verdana||||" text_font_size="18" use_border_color="off" border_color="#ffffff" border_style="solid"]
Nos últimos dias houve intensa discussão sobre aplicativos de transporte no país, dado o trâmite do PLC 28/2017 no Congresso Nacional, que procura regulamentar a atividade. Inspirados por essa controvérsia, na edição 37 do Clube do Código procuramos entender se existe uma relação de causalidade entre procuras pela Uber e a taxa de desemprego. A hipótese implícita nesse estudo é a de que o aumento recente do desemprego teve influência no número de motoristas cadastrados na Uber e em outros aplicativos de transporte. Nesse post, resumimos os resultados encontrados.
Antes de mais nada, precisamos coletar as variáveis que vamos utilizar no processo de modelagem. Por sorte, todos os dados estão disponíveis via pacotes do R. O código abaixo, então, ilustra o processo de importação dos dados.
### Carregar pacotes
library(gtrendsR)
library(ggplot2)
library(xts)
library(sidrar)
library(forecast)
library(vars)
library(aod)
library(gridExtra)
library(stargazer)
####### Importar dados
desemprego = ts(get_sidra(api='/t/6381/n1/all/v/4099/p/all/d/v4099%201')$Valor,
start=c(2012,03), freq=12)
trends = gtrends('uber', geo='BR')
gtrends = data.frame(time=trends$interest_over_time$date,
empregos=trends$interest_over_time$hits)
gtrends$time = as.Date(gtrends$time, format='%d/%m/%Y')
gtrends = xts(gtrends$empregos, order.by=gtrends$time)
gtrends = ts(apply.monthly(gtrends, FUN=mean), start=c(2012,10), freq=12)
data = ts.intersect(desemprego, gtrends)
colnames(data) = c('desemprego', 'uber')
De posse dos dados, procedemos uma visualização gráfica dos mesmos.

E abaixo um gráfico de correlação entre as séries.
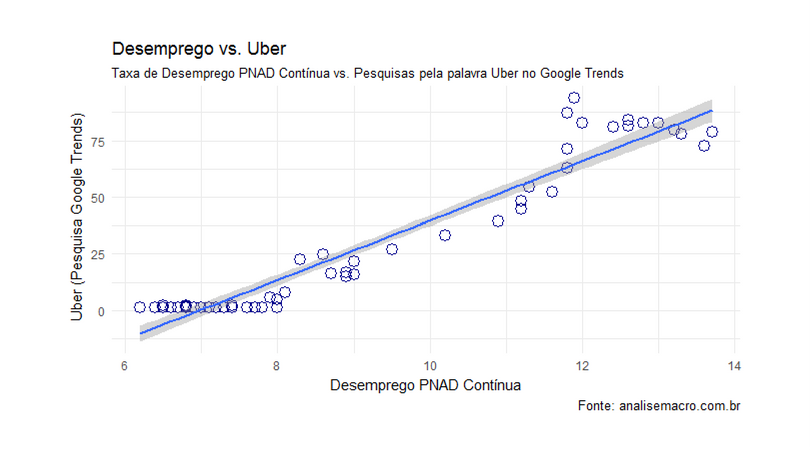
Dados os resultados obtidos no teste de raiz unitária, vamos considerar que ambas as séries são não estacionárias. Isso dito, vamos aplicar o procedimento de Toda-Yamamoto. Abaixo, determinamos a ordem de defasem do VAR com base em critérios de informação.
[/et_pb_text][/et_pb_column][/et_pb_row][et_pb_row admin_label="Linha"][et_pb_column type="4_4"][et_pb_image admin_label="Imagem" src="https://analisemacro.com.br/wp-content/uploads/2017/11/cursosaplicados.png" show_in_lightbox="off" url="https://analisemacro.com.br/cursos-de-r/" url_new_window="off" use_overlay="off" animation="left" sticky="off" align="center" force_fullwidth="off" always_center_on_mobile="on" use_border_color="off" border_color="#ffffff" border_style="solid"]
[/et_pb_image][/et_pb_column][/et_pb_row][et_pb_row admin_label="row"][et_pb_column type="4_4"][et_pb_text admin_label="Texto" background_layout="light" text_orientation="justified" text_font="Verdana||||" text_font_size="18" use_border_color="off" border_color="#ffffff" border_style="solid"]
### Selecionar Defasagem def = VARselect(data,lag.max=12,type="both") def$selection
Escolhemos  e começamos a montar o VAR com o código a seguir. Uma vez feito isso, checamos se o mesmo é resistente ao teste de correlação serial e se há estabilidade no mesmo.
e começamos a montar o VAR com o código a seguir. Uma vez feito isso, checamos se o mesmo é resistente ao teste de correlação serial e se há estabilidade no mesmo.
### VAR(2) var2 = VAR(data, p=2, type='both') serial.test(var2) ### VAR(3) var3 = VAR(data, p=3, type='both') serial.test(var3) ### VAR(4) var4 = VAR(data, p=4, type='both') serial.test(var4) ### VAR(5) var5 = VAR(data, p=5, type='both') serial.test(var5)
Dados os resultados, podemos prosseguir para o Teste de Wald, conforme o código abaixo, lembrando de fazer o ajuste para um VAR(m+p).
### Teste de Wald var6 = VAR(data, p=6, type='both') ### Wald Test 01: Uber não granger causa Desemprego wald.test(b=coef(var6$varresult[[1]]), Sigma=vcov(var6$varresult[[1]]), Terms=c(2,4,6,8,10)) ### Wald Test 02: Desemprego não granger causa Uber wald.test(b=coef(var6$varresult[[2]]), Sigma=vcov(var6$varresult[[2]]), Terms= c(1,3,5,7,9))
Os resultados do procedimento de Toda-Yamamoto aplicado às séries sugerem que existe evidência de causalidade no sentido do desemprego para a procura pela Uber. Não se rejeita a hipótese no sentido contrário. Os membros do Clube do Código têm acesso a todo o processo de construção das previsões, brevemente descrito nesse post. Para se tornar membro, consulte a página do Clube aqui.
[/et_pb_text][/et_pb_column][/et_pb_row][et_pb_row admin_label="row"][et_pb_column type="1_2"][et_pb_image admin_label="Imagem" src="https://analisemacro.com.br/wp-content/uploads/2016/06/liberte-se.png" show_in_lightbox="off" url="https://analisemacro.com.br/cursos-de-r/" url_new_window="off" use_overlay="off" animation="left" sticky="off" align="center" force_fullwidth="off" always_center_on_mobile="on" use_border_color="off" border_color="#ffffff" border_style="solid"]
[/et_pb_image][et_pb_text admin_label="Texto" background_layout="light" text_orientation="center" use_border_color="off" border_color="#ffffff" border_style="solid"]
Clique na figura para conhecer os nossos Cursos
[/et_pb_text][/et_pb_column][et_pb_column type="1_2"][et_pb_image admin_label="Imagem" src="https://analisemacro.com.br/wp-content/uploads/2016/04/painel.png" show_in_lightbox="off" url="https://analisemacro.com.br/cursos-de-r/cursos-de-econometria/dados-em-painel/" url_new_window="off" use_overlay="off" animation="left" sticky="off" align="center" force_fullwidth="off" always_center_on_mobile="on" use_border_color="off" border_color="#ffffff" border_style="solid"]
[/et_pb_image][et_pb_text admin_label="Texto" background_layout="light" text_orientation="center" use_border_color="off" border_color="#ffffff" border_style="solid"]
Clique na figura para conhecer nosso novo curso de econometria
[/et_pb_text][/et_pb_column][/et_pb_row][et_pb_row admin_label="row"][et_pb_column type="1_3"][et_pb_gallery admin_label="Galeria" gallery_ids="17132,17133,17134" fullwidth="on" show_title_and_caption="off" show_pagination="off" background_layout="light" auto="on" auto_speed="6000" hover_overlay_color="rgba(255,255,255,0.9)" caption_all_caps="off" use_border_color="off" border_color="#ffffff" border_style="solid" saved_tabs="all"]
[/et_pb_gallery][et_pb_gallery admin_label="Galeria" gallery_ids="17136,17137,17138" fullwidth="on" show_title_and_caption="off" show_pagination="off" background_layout="light" auto="on" auto_speed="6000" hover_overlay_color="rgba(255,255,255,0.9)" caption_all_caps="off" use_border_color="off" border_color="#ffffff" border_style="solid" saved_tabs="all"]
[/et_pb_gallery][/et_pb_column][et_pb_column type="2_3"][et_pb_team_member admin_label="Pessoa" saved_tabs="all" name="Vítor Wilher " position="Data Scientist" animation="left" background_layout="light" facebook_url="https://www.facebook.com/vitor.wilher.9" twitter_url="https://twitter.com/vitorwilherbr" linkedin_url="https://www.linkedin.com/in/v%C3%ADtor-wilher-78164024" use_border_color="off" border_color="#ffffff" border_style="solid"]
Vítor Wilher é Bacharel e Mestre em Economia, pela Universidade Federal Fluminense, tendo se especializado na construção de modelos macroeconométricos, política monetária e análise da conjuntura macroeconômica doméstica e internacional. Tem, ademais, especialização em Data Science pela Johns Hopkins University. Sua dissertação de mestrado foi na área de política monetária, titulada "Clareza da Comunicação do Banco Central e Expectativas de Inflação: evidências para o Brasil", defendida perante banca composta pelos professores Gustavo H. B. Franco (PUC-RJ), Gabriel Montes Caldas (UFF), Carlos Enrique Guanziroli (UFF) e Luciano Vereda Oliveira (UFF). Já trabalhou em grandes empresas, nas áreas de telecomunicações, energia elétrica, consultoria financeira e consultoria macroeconômica. É o criador da Análise Macro, startup especializada em treinamento e consultoria em linguagens de programação voltadas para data analysis, sócio da MacroLab Consultoria, empresa especializada em cenários e previsões e fundador do hoje extinto Grupo de Estudos sobre Conjuntura Econômica (GECE-UFF). É também Visiting Professor da Universidade Veiga de Almeida, onde dá aulas nos cursos de MBA da instituição, Conselheiro do Instituto Millenium e um dos grandes entusiastas do uso do R no ensino. Leia os posts de Vítor Wilher aqui. Caso queira, mande um e-mail para ele: vitorwilher@analisemacro.com.br
[/et_pb_team_member][/et_pb_column][/et_pb_row][/et_pb_section]

