A IA oferece métodos para compreender e prever variáveis agregadas da economia, como ciclos econômicos, decisões de políticas monetárias e previsões de diferentes indicadores econômicos. Utilizando algoritmos de Machine Learning os economistas podem analisar grandes volumes de dados econômicos para identificar padrões e tendências, fornecendo insights.
O Python torna o processo de análise e modelagem mais acessível e eficiente. Ao aplicar técnicas de IA na Macroeconomia, é possível melhorar nossa compreensão dos fenômenos econômicos e a precisão de nossas previsões, abrindo novas oportunidades para análise e tomada de decisões.
Existem várias abordagens e tipos de IA, cada uma com suas características e aplicações específicas. Uma que apresentou-se útil para a área de economia, especialmente na previsão de modelos, refere-se a IA Aprendizado de Máquina (Machine Learning).
A IA Aprendizado de Máquina (Machine Learning) é uma das áreas mais proeminentes da IA atualmente, o aprendizado de máquina envolve algoritmos que permitem que sistemas computacionais aprendam a partir de dados sem serem explicitamente programados. Existem várias técnicas de aprendizado de máquina, incluindo aprendizado supervisionado, não supervisionado, e por reforço. Não somente para a previsão de dados, o aprendizado de máquina é também é utilizado em uma variedade de aplicações, incluindo reconhecimento de padrões, classificação, recomendação e entre diversas outras possibilidades.
Modelos macroeconômicos tradicionais geralmente possuem uma dependência de suposições simplificadas e relações lineares entre variáveis econômicas. No entanto, a economia é um sistema complexo e interconectado, com uma infinidade de variáveis que influenciam umas às outras de maneiras não-lineares. IA e Machine Learning podem lidar melhor com essa complexidade, permitindo previsões mais precisas e sofisticadas.
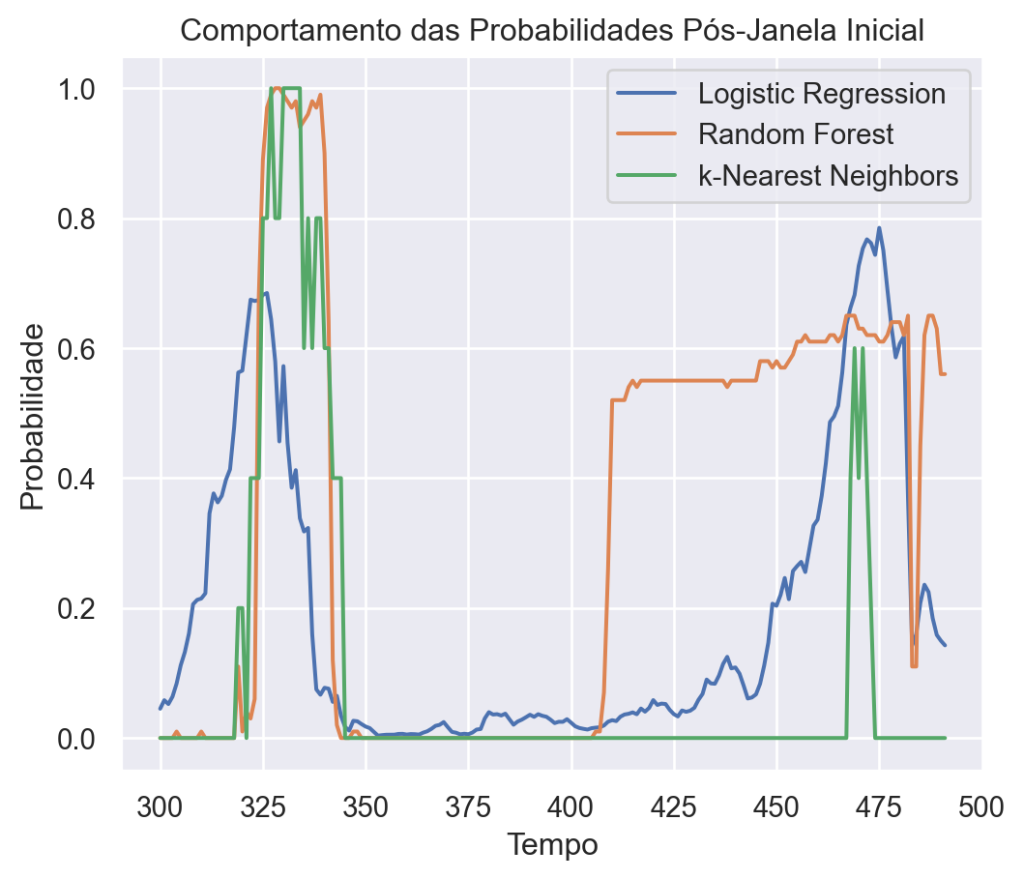
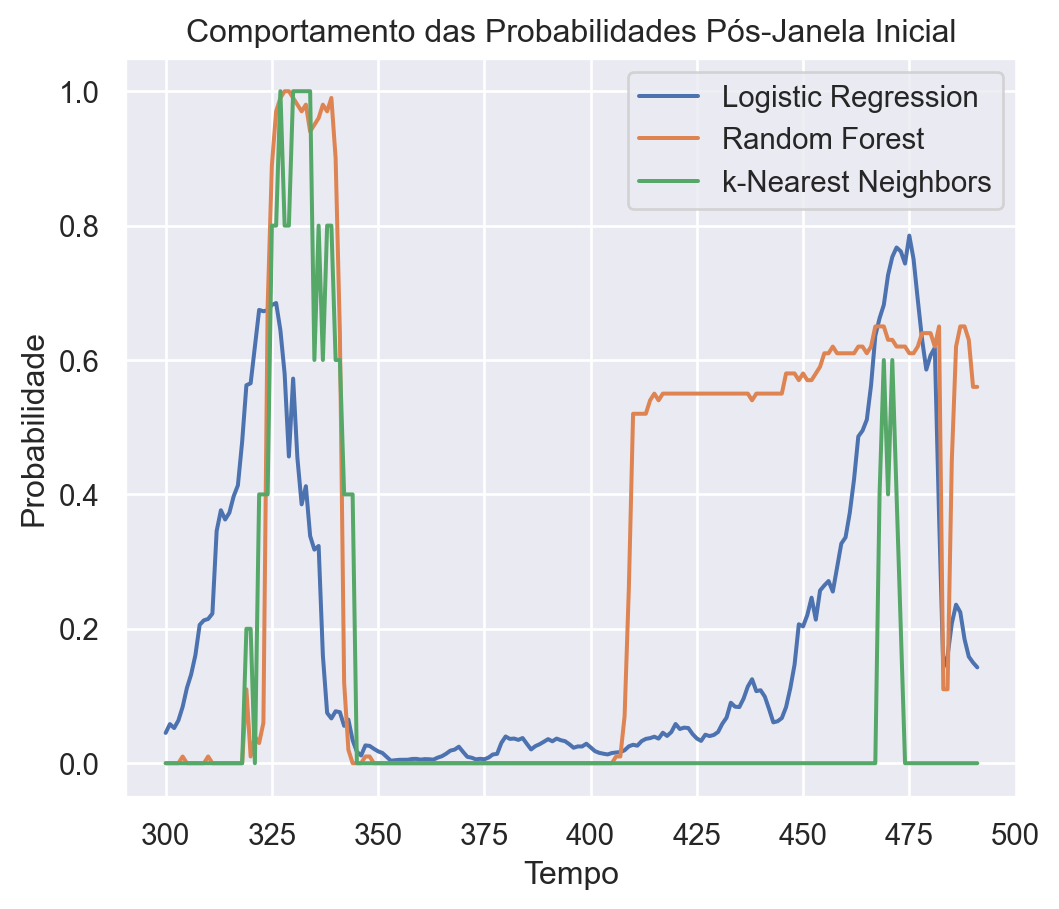
No presente exercício iremos mostrar o uso do IA Aprendizado de Máquina para realizar a previsão da probabilidade de recessão nos EUA, conforme três diferentes modelos de Machine Learning.
Prevendo a probabilidade de recessão
Para mostrar um exemplo do uso de machine learning para previsão de dados macroeconômicos, decidimos criar diferentes modelos para previsão de recessão nos Estados Unidos.
Aqui utilizaremos:
- Random Forest:
- Random Forest é um algoritmo de aprendizado de máquina que opera criando uma “floresta” de árvores de decisão durante o treinamento.
- Cada árvore na floresta é construída de forma independente e aleatória, utilizando amostras aleatórias do conjunto de dados de treinamento e um subconjunto aleatório de características em cada divisão.
- Para fazer previsões, as árvores individuais votam em uma classe ou fornecem uma previsão contínua, e a previsão final é determinada pela votação ou pela média das previsões das árvores individuais.
- Random Forest é conhecida por sua eficácia em lidar com uma variedade de problemas de classificação e regressão, e é frequentemente utilizada devido à sua capacidade de reduzir o overfitting e fornecer estimativas de importância das características.
- KNN:
- KNN é um algoritmo de aprendizado de máquina utilizado tanto para classificação quanto para regressão.
- Em KNN, as previsões são feitas com base na proximidade dos pontos de dados de treinamento no espaço de características.
- Para fazer uma previsão para um novo ponto de dados, o algoritmo encontra os k pontos de dados de treinamento mais próximos ao novo ponto (onde k é um número especificado pelo usuário), e a classe ou o valor alvo desses pontos é usado para fazer a previsão.
- KNN é um algoritmo simples de entender e implementar, mas pode ser computacionalmente caro para conjuntos de dados grandes e pode ser sensível à escala e à dimensionalidade.
- Regressão Logística:
- A regressão logística é um algoritmo de aprendizado supervisionado utilizado para problemas de classificação binária.
- Apesar do nome, a regressão logística é usada para prever a probabilidade de que um determinado ponto de dados pertença a uma classe ou categoria específica.
- A regressão logística utiliza uma função logística para modelar a relação entre as características de entrada e a probabilidade de pertencer a uma classe.
- Durante o treinamento, os parâmetros do modelo são ajustados para minimizar a diferença entre as previsões do modelo e os valores reais observados.
Estaremos utilizando as seguintes variáveis:
- Taxa de juros do tesouro americano de curto (3 meses) e longo (10 anos) prazo,
- Empregados (excluindo agrícolas)
- Inflação.
Além disso é incluída uma variável de diferença entre a taxa de longo e a de curto prazo, para determinar o ângulo da curva de juros. Para todas as variáveis explicativas são incluídos os lags de 3,6,9 e 12 meses. Nossa variável de interesse é o indicador de recessão mensal produzido pelo NBER adiantado 12 meses. Ou seja, nosso interesse é prever se vai haver uma recessão nos 12 meses subsequentes.
Quer aprender mais?
Clique aqui para fazer seu cadastro no Boletim AM e baixar o código que produziu este exercício, além de receber novos exercícios com exemplos reais de análise de dados envolvendo as áreas de Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas diretamente em seu e-mail.

