Como explicar modelos de previsão de séries temporais econômicas utilizando métodos de Machine Learning? Neste exercício, demonstraremos alguns métodos úteis para avaliar os parâmetros dos preditores em tais modelos. Para isso, utilizaremos o framework da biblioteca Skforecast em Python.
Aprenda a coletar, processar e analisar dados na formação de Do Zero à Análise de Dados Econômicos e Financeiros com Python.
Quer aprender a como criar modelos de série econômicas brasileiras usando Machine Learning e IA Generativa? Veja nosso curso IA para previsão Macroeconômica usando Python.
Introdução
No último exercício, mostramos como o framework da biblioteca Skforecast auxilia na previsão de séries econômicas, oferecendo um suporte abrangente para a modelagem de séries temporais. Realizamos a previsão da taxa de desemprego dos EUA para um período de um ano, utilizando diferentes modelos.
O foco foi na previsão, portanto, tínhamos interesse em obter apenas os valores futuros contínuos da taxa de desemprego. Entretanto, como podemos interpretar a relação entre a variável dependente e os preditores?
Essa interpretabilidade de algortimos de Machine Learning, usualmente conhecido como explainability, refere-se à capacidade de entender, interpretar e explicar as decisões ou previsões feitas por modelos de aprendizado de máquina de uma maneira compreensível para humanos. Ela visa esclarecer como um modelo chega a um resultado ou decisão particular.
Devido à natureza complexa de muitos modelos modernos de aprendizado de máquina, como os métodos de ensemble, eles frequentemente funcionam como caixas-pretas, dificultando a compreensão do motivo pelo qual uma previsão específica foi feita. As técnicas de explainability têm como objetivo desmistificar esses modelos, fornecendo compreensão sobre seu funcionamento interno e ajudando a melhorar a transparência.
Melhorar a explicabilidade do modelo não só ajuda a entender o comportamento do modelo, mas também a identificar vieses, melhorar o desempenho do modelo e permitir a gestores e outros públicos compreendam os modelos.
A biblitoeca skforecast é compatível com os métodos de interpretação: Shap values, Partial Dependency Plots e Model-specific methods.
Feature Importance
Feature importance é uma técnica usada em aprendizado de máquina para determinar a relevância ou importância de cada característica (ou variável) na previsão de um modelo. Em outras palavras, ela mede quanto cada característica contribui para o resultado do modelo.
A importância das características pode ser utilizada para diversos fins, como identificar as características mais relevantes para uma determinada previsão, entender o comportamento de um modelo e selecionar o melhor conjunto de características para uma determinada tarefa. Também pode ajudar a identificar potenciais vieses ou erros nos dados usados para treinar o modelo. É importante notar que a importância das características não é uma medida definitiva de causalidade. Só porque uma característica é identificada como importante não significa necessariamente que ela causou o resultado. Outros fatores, como variáveis de confusão, também podem estar em jogo.
O método usado para calcular a importância das características pode variar dependendo do tipo de modelo de aprendizado de máquina sendo utilizado. Diferentes modelos de aprendizado de máquina podem ter diferentes suposições e características que afetam o cálculo da importância das características. Por exemplo, modelos baseados em árvores de decisão, como Random Forest e Gradient Boosting, tipicamente usam métodos de diminuição média de impureza ou importância das características por permutação para calcular a importância das características. Modelos de regressão linear tipicamente usam coeficientes ou coeficientes padronizados para determinar a importância de uma característica. A magnitude do coeficiente reflete a força e a direção da relação entre a característica e a variável alvo.
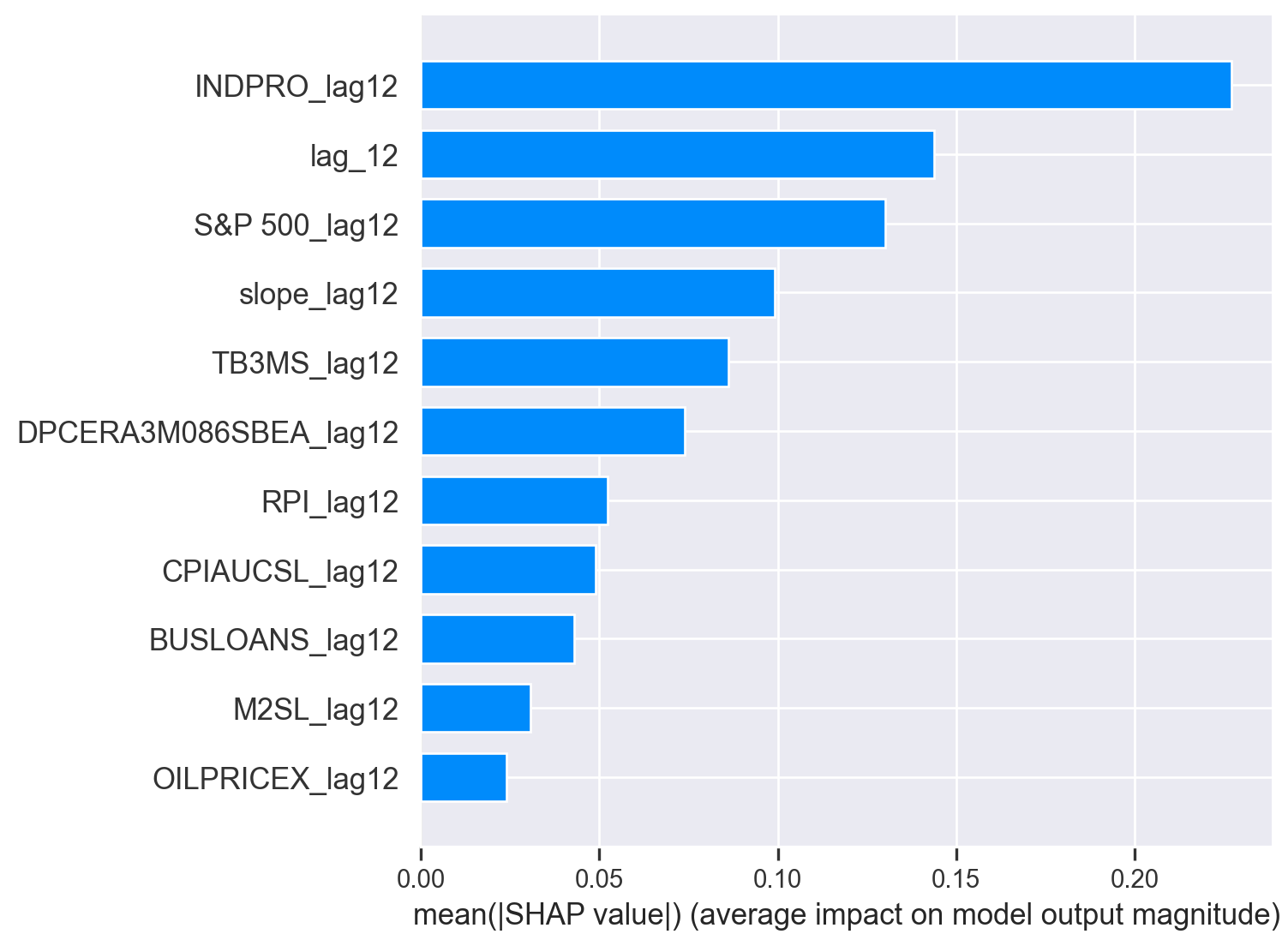
A importância dos preditores incluídos em um modelo de previsão pode ser obtida usando o método get_feature_importances(). Esse método acessa os atributos coef_ e feature_importances_ do regressor interno.
Código
| feature | importance | |
|---|---|---|
| 0 | lag_12 | 0.159808 |
| 3 | INDPRO_lag12 | 0.135341 |
| 5 | S&P 500_lag12 | 0.116653 |
| 10 | slope_lag12 | 0.090311 |
| 1 | TB3MS_lag12 | 0.088330 |
| 2 | RPI_lag12 | 0.086686 |
| 6 | BUSLOANS_lag12 | 0.075207 |
| 4 | DPCERA3M086SBEA_lag12 | 0.073973 |
| 7 | CPIAUCSL_lag12 | 0.064816 |
| 9 | M2SL_lag12 | 0.064740 |
| 8 | OILPRICEX_lag12 | 0.044135 |
Shap Values
Valores SHAP (SHapley Additive exPlanations) são um método popular para explicar modelos de aprendizado de máquina, pois ajudam a entender como variáveis e valores influenciam as previsões de forma visual e quantitativa.
Código
Código
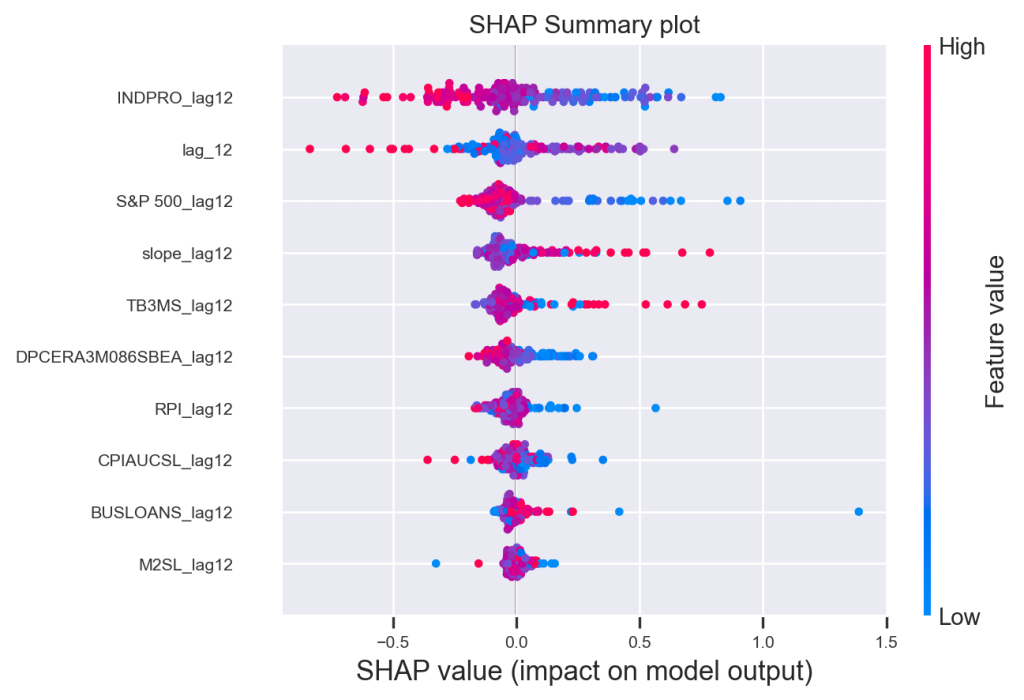
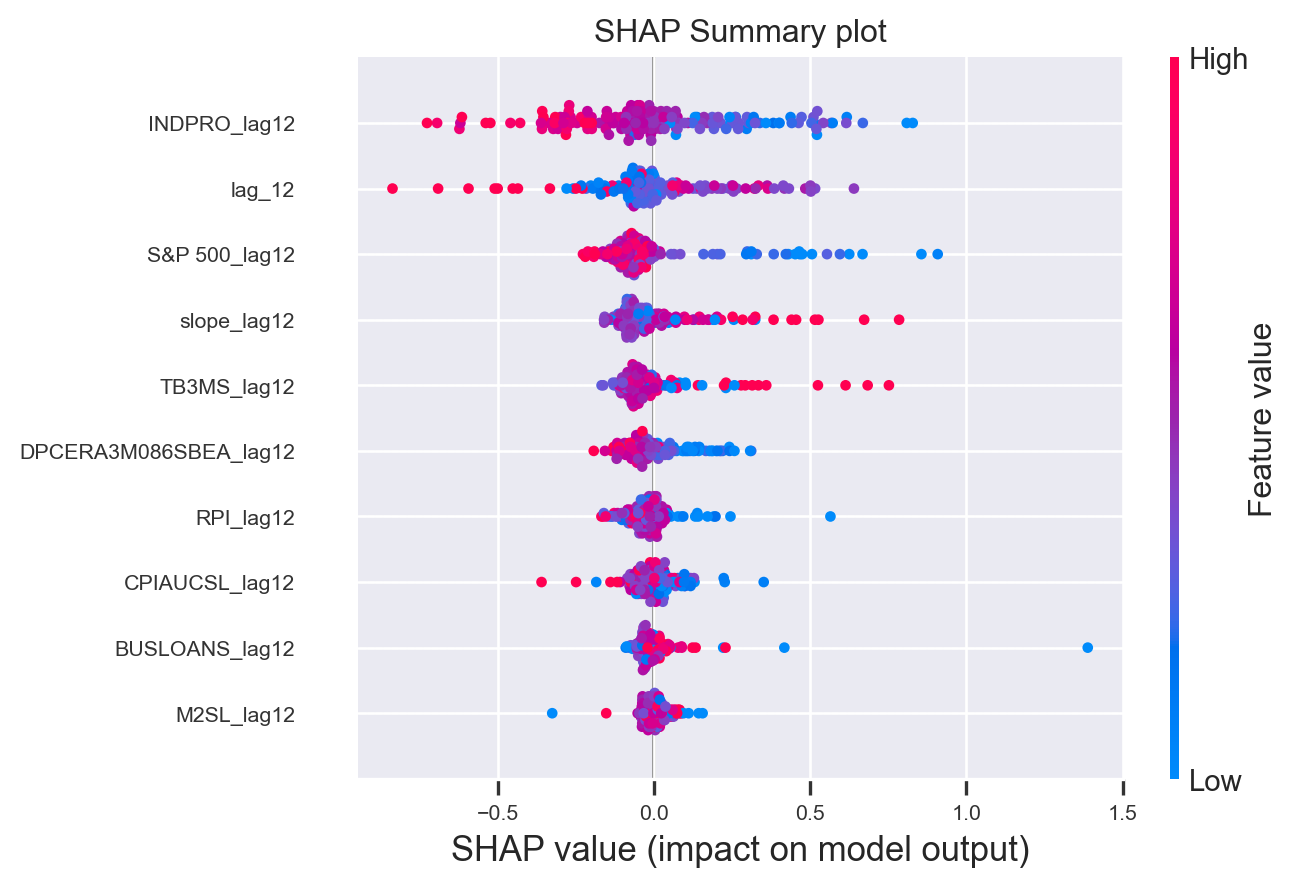
SHAP Summary Plot
O gráfico de resumo SHAP normalmente exibe a importância ou a contribuição de cada característica para o resultado do modelo em vários pontos de dados. Ele mostra quanto cada característica contribui para afastar a previsão do modelo de um valor base (geralmente a previsão média do modelo).
Ao examinar um gráfico de resumo SHAP, é possível obter insights sobre quais características têm o impacto mais significativo nas previsões, se influenciam positiva ou negativamente o resultado e como diferentes valores das características contribuem para previsões específicas.
No caso da nossa previsão em particular, temos a seguinte leitura:
- A importância de cada característica é representada pelas variáveis no eixo y na previsão do modelo.
- A posição de cada ponto ao longo do eixo x indica o impacto daquela característica específica em uma previsão particular. A cor do ponto revela se a característica teve um impacto positivo (vermelho) ou negativo (azul) na previsão.
Análise das variáveis
- INDPRO_lag12: A produção industrial com um lag de 12 meses parece ter um impacto significativo e variável nas previsões. Pontos mais à direita indicam que um aumento na produção industrial do ano anterior está associado a previsões de menor desemprego, e vice-versa.
- S&P 500_lag12: O desempenho do índice S&P 500 também parece influenciar as previsões. Valores mais altos do índice no ano anterior tendem a estar associados a previsões de menor desemprego.
- slope_lag12: Essa variável, provavelmente relacionada à inclinação de alguma curva de juros, apresenta um impacto considerável e variável. A interpretação exata dependeria da natureza específica dessa variável.
- TB3MS_lag12: As taxas de juros de 3 meses com um lag de 12 meses parecem ter um impacto menor e mais concentrado em torno de zero, sugerindo uma influência menos direta nas previsões.
- DPCERA3M086SBEA_lag12, RPI_lag12, CPIAUCSL_lag12: Essas variáveis, relacionadas a consumo pessoal, renda pessoal e índice de preços ao consumidor, respectivamente, apresentam um impacto moderado e variável nas previsões.
- BUSLOANS_lag12, M2SL_lag12, OILPRICEX_lag12: Empréstimos empresariais, oferta monetária e preço do petróleo também parecem ter alguma influência, mas com menor intensidade.

Explain predictions in training data
Um shap.force_plot é um tipo específico de visualização que fornece uma visão interativa e detalhada de como características individuais contribuem para uma determinada previsão feita por um modelo de aprendizado de máquina. É uma ferramenta de interpretação local que ajuda a entender por que um modelo fez uma previsão específica para uma determinada instância.
Visualiza uma única previsão

Visualiza várias previsões
Além da possibilidade de visualização para uma única previsão, podemos realizar a análise para diversas previsões. Abaixo, a contribuição de cada variável a cada ponto no tempo das previsões.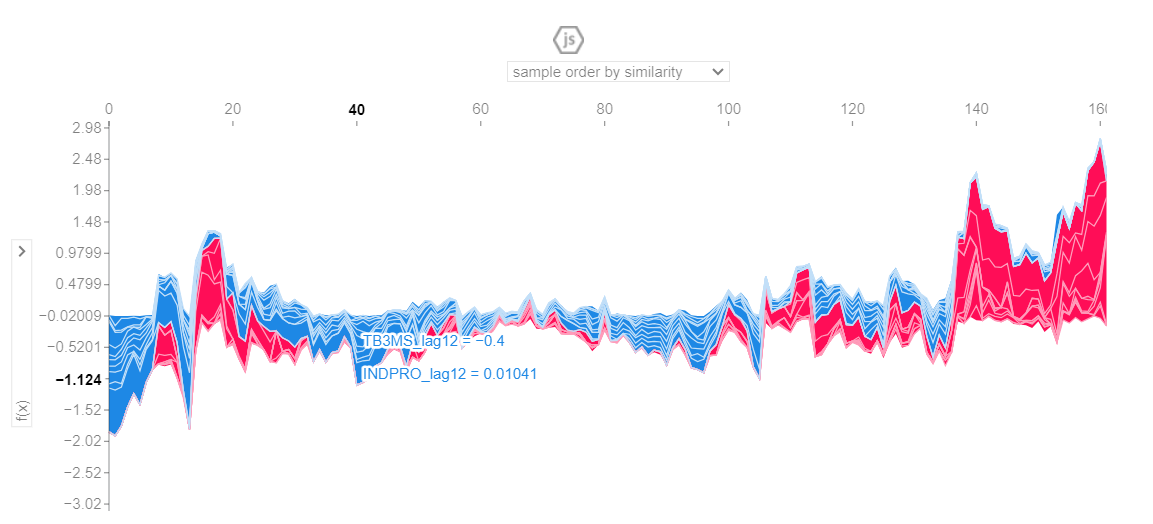
SHAP Dependence Plots
Os gráficos de dependência SHAP são visualizações usadas para entender a relação entre uma feature e o resultado do modelo, mostrando como o valor de uma única feature afeta as previsões feitas pelo modelo enquanto considera interações com outras feature. Esses gráficos são particularmente úteis para examinar como uma determinada característica impacta as previsões do modelo ao longo de sua faixa de valores, considerando as interações com outras variáveis.
No caso o INDPRO_lag12 (Produção Industrial com um lag de 12 meses), influencia as previsões do modelo de desemprego dos EUA. Ele nos permite visualizar a relação entre o valor da variável e o impacto que ela tem no resultado final da previsão.
- Impacto variável: O valor SHAP para slope_lag12 varia significativamente para diferentes valores de INDPRO_lag12. Isso indica que a importância da produção industrial na determinação da inclinação da curva de juros muda dependendo do nível da própria produção industrial.
- Tendência geral: Observamos uma tendência geral de que valores mais altos de INDPRO_lag12 estão associados a valores mais negativos de SHAP para slope_lag12. Isso sugere que, em média, um aumento na produção industrial do ano anterior tende a levar a uma diminuição na inclinação da curva de juros.
É possível, claro, criar a visualização para diferentes features do modelo.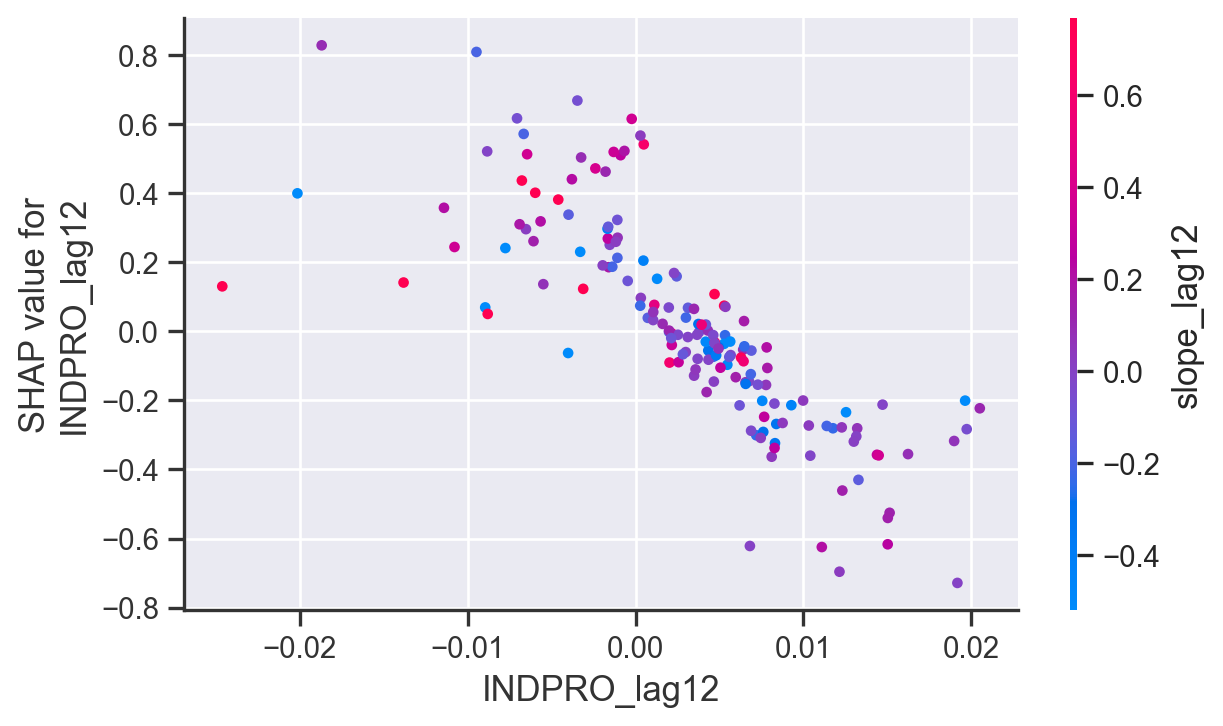
Scikit-learn partial dependence plots
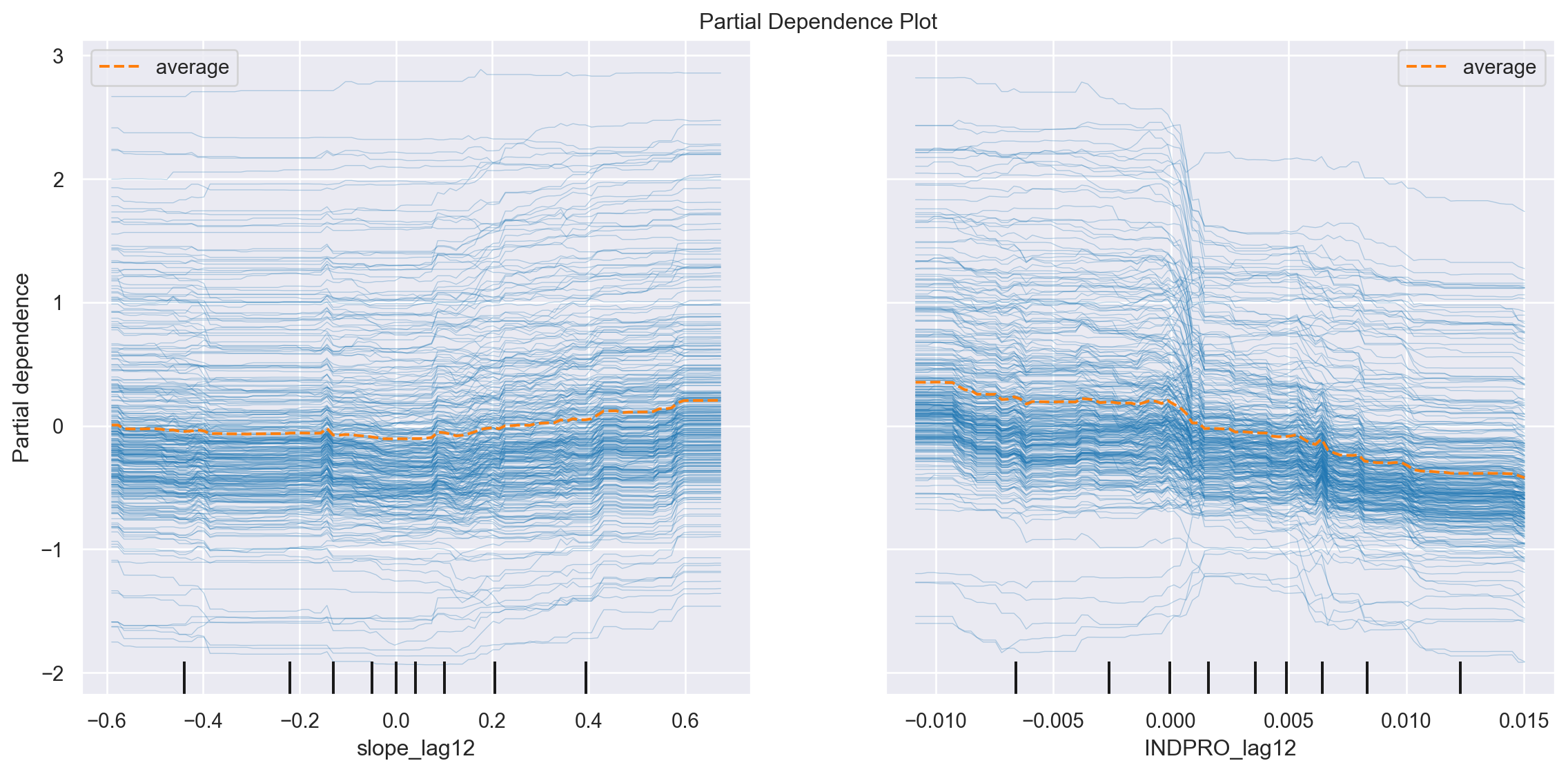
Os gráficos de dependência parcial (PDPs) são uma ferramenta útil para entender a relação entre uma característica e o resultado alvo em um modelo de aprendizado de máquina. No scikit-learn, você pode criar gráficos de dependência parcial usando a função plot_partial_dependence. Essa função visualiza o efeito de uma ou duas características no resultado previsto, enquanto marginaliza o efeito de todas as outras características.
Os gráficos resultantes mostram como as mudanças nas características selecionadas afetam o resultado previsto, mantendo as outras características constantes, em média. Lembre-se de que esses gráficos devem ser interpretados no contexto do seu modelo e dos seus dados. Eles fornecem uma compreensão sobre a relação entre características específicas e as previsões do modelo. Portanto, a análise que temos do modelo ajustado, para as variáveis slope_12m e INDPROD_lag12 é:
- Eixo X: Representa os valores possíveis da variável em análise (slope_lag12 e INDPRO_lag12).
- Eixo Y: Representa o valor médio da previsão do modelo para um determinado valor da variável no eixo X, mantendo todas as outras variáveis constantes.
- Linhas individuais: Cada linha representa uma observação individual do conjunto de dados.
- Linha laranja: Representa a média de todas as previsões para cada valor da variável no eixo X.
- slope_lag12:
- Tendência: A linha laranja (média) apresenta uma tendência levemente crescente, indicando que, em média, um aumento na inclinação da curva de juros com um lag de 12 meses está associado a um leve aumento na previsão do desemprego.
- Variabilidade: As linhas individuais apresentam uma grande variabilidade, sugerindo que a relação entre a inclinação da curva de juros e o desemprego pode ser complexa e dependente de outros fatores não capturados neste gráfico.
- INDPRO_lag12:
- Tendência: A linha laranja apresenta uma tendência levemente decrescente, indicando que, em média, um aumento na produção industrial com um lag de 12 meses está associado a uma leve diminuição na previsão do desemprego. Essa relação é consistente com a intuição econômica: um aumento na produção geralmente indica um aquecimento da economia e, consequentemente, uma redução no desemprego.
- Variabilidade: Assim como na variável anterior, as linhas individuais apresentam uma grande variabilidade, sugerindo a existência de outros fatores que influenciam a relação entre a produção industrial e o desemprego.

Referências
Buckmann, M., Joseph, A. e Robertson, H. (2021). Opening the black box: Machine learning interpretability and inference tools with an application to economic forecasting. Data Science for Economics and Finance: Methodologies and Applications(pp. 43-63). Springer International Publishing.
fg-research. An overview of the FRED-MD database. Acesso em: https://fg-research.com/blog/general/posts/fred-md-overview.html#code
McCracken, M. W., & Ng, S. (2016). FRED-MD: A monthly database for macroeconomic research. Journal of Business & Economic Statistics, 34(4), 574-589. doi: 10.1080/07350015.2015.1086655.
Quer aprender mais?
Clique aqui para fazer seu cadastro no Boletim AM e baixar o código que produziu este exercício, além de receber novos exercícios com exemplos reais de análise de dados envolvendo as áreas de Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas diretamente em seu e-mail.

