Neste exercício, mostramos como identificar um choque dos preços administrados sobre os preços livres utilizando um Vetor Autoregressivo e Função de Impulso Resposta. Realizamos a coleta, tratamento, visualização e criação do modelo usando o Python.
Introdução
Alguns economistas brasileiros costumam fazer uso do termo inflação de custos (em contradição à inflação de demanda) para justificar o fato de que não faria sentido utilizar um instrumento que atua sobre a demanda, os juros, para conter um choque de oferta.
Mostramos nesse exercício que na ocorrência de um choque nos chamados preços administrados, seria um equívoco o Banco Central não reagir aos efeitos secundários do mesmo, isto é, efeitos sobre outros preços. A leniência com choques de oferta tem como efeito o desvio da inflação efetiva em relação à meta e consequente elevação das expectativas dos agentes privados, arranhando assim a credibilidade da autoridade monetária.
Preços livres vs. preços administrados
Para ilustrar o argumento, vamos dividir a inflação medida pelo IPCA da forma que segue
![\[\pi_t = \alpha_1 \pi_t^{livres} + \alpha_2 \pi_t^{admin}\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-39f61757c8b22432292d1ed8cde526b0_l3.png "Rendered by QuickLaTeX.com")
isto é, a inflação medida pelo IPCA passa a ser uma combinação linear entre a inflação de preços livres e a inflação de preços administrados (Preços administrados são aqueles estabelecidos por contrato, por órgão público ou agência reguladora e, geralmente, são menos sensíveis às condições de mercado)
Atualmente, são considerados preços administrados, 22 subitens e 1 item do IPCA. Para maiores detalhes sobre esses preços, ver o Texto para Discussão 305 do Banco Central, titulado Preços Administrados: projeção e repasse cambial.
Sabemos, entretanto, que os preços livres e os preços administrados não são independentes, uma vez que muitos dos bens considerados administrados servem de insumo para os bens livres - pense, por exemplo, na energia elétrica. Coletamos, portanto, a inflação mensal geral, dos preços livres e administrados diretamente do Banco Central.
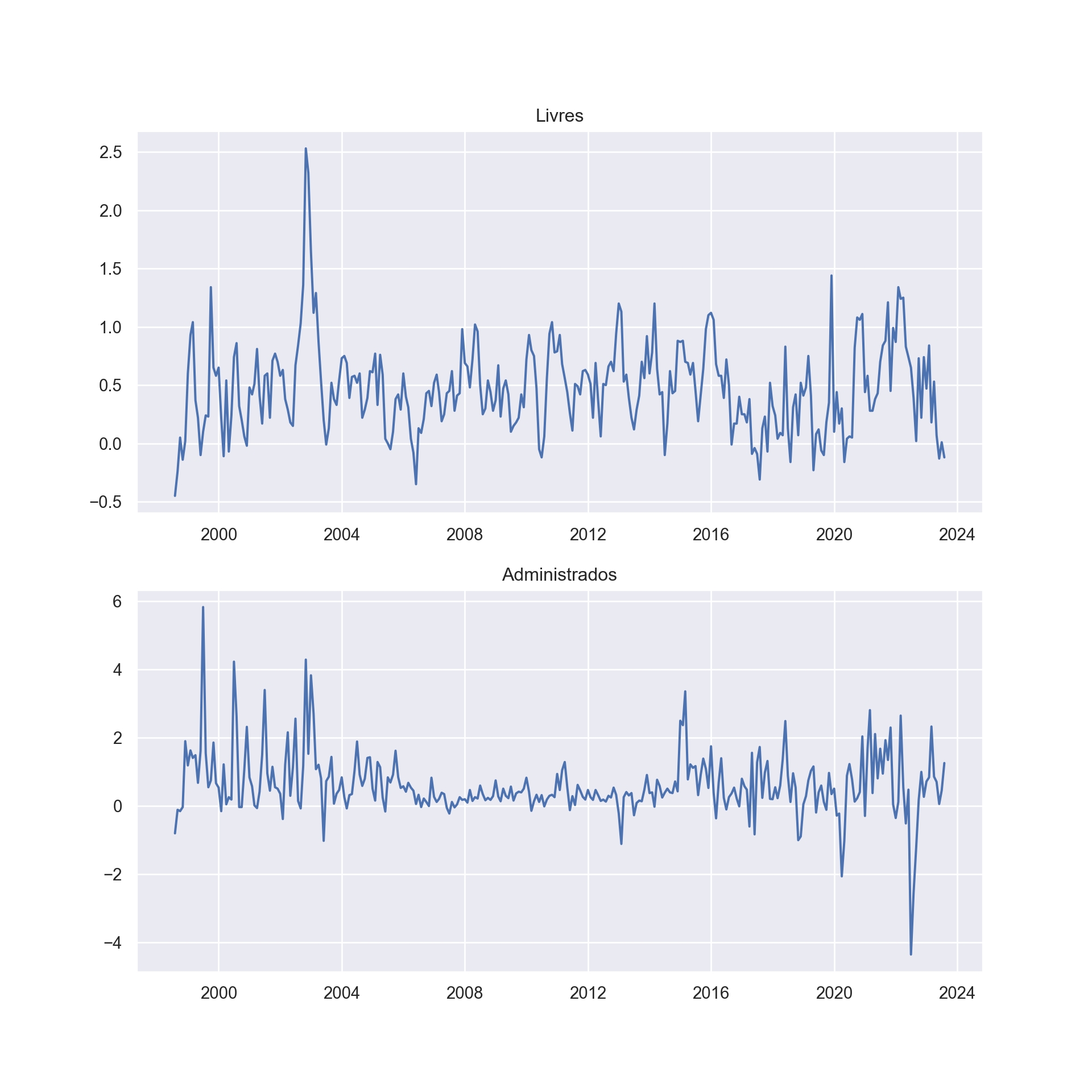
Através de uma regressão linear simples e de um gráfico de dispersão, verificamos a relação entre as duas variáveis, como segue:
Código
| Dep. Variable: | ipca | R-squared (uncentered): | 0.997 |
| Model: | OLS | Adj. R-squared (uncentered): | 0.997 |
| Method: | Least Squares | F-statistic: | 5.324e+04 |
| Date: | Fri, 15 Sep 2023 | Prob (F-statistic): | 0.00 |
| Time: | 17:35:06 | Log-Likelihood: | 587.37 |
| No. Observations: | 301 | AIC: | -1171. |
| Df Residuals: | 299 | BIC: | -1163. |
| Df Model: | 2 | ||
| Covariance Type: | nonrobust |
| coef | std err | t | P>|t| | [0.025 | 0.975] | |
| Livres | 0.7487 | 0.004 | 195.690 | 0.000 | 0.741 | 0.756 |
| Administrados | 0.2471 | 0.002 | 117.000 | 0.000 | 0.243 | 0.251 |
| Omnibus: | 427.098 | Durbin-Watson: | 1.310 |
| Prob(Omnibus): | 0.000 | Jarque-Bera (JB): | 77286.326 |
| Skew: | -6.685 | Prob(JB): | 0.00 |
| Kurtosis: | 80.354 | Cond. No. | 2.37 |
Notes:
[1] R² is computed without centering (uncentered) since the model does not contain a constant.
[2] Standard Errors assume that the covariance matrix of the errors is correctly specified.

Estimando um VAR
Um VAR irá descrever a evolução dinâmica de um determinado número de variáveis de acordo com a história comum entre elas. Para ilustrar, considere um vetor autorregressivo de ordem 1, como
Um VAR irá descrever a evolução dinâmica de um determinado número de variáveis de acordo com a história comum entre elas. Para ilustrar, considere um vetor autorregressivo de ordem 1, como
![\[Y_{t} = \delta_{1} + \theta_{11} Y_{t-1} + \theta_{12} X_{t-1} + \epsilon_{1t} \\ X_{t} = \delta_{2} + \theta_{21} Y_{t-1} + \theta_{22} X_{t-1} + \epsilon_{2t}\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-c5fa5a92ac6713b96941509a12a5df76_l3.png "Rendered by QuickLaTeX.com")
onde  e
e  são ruídos brancos independentes das estórias de
são ruídos brancos independentes das estórias de  e
e  , mas que podem estar correlacionados. Se, por exemplo,
, mas que podem estar correlacionados. Se, por exemplo,  , significa dizer que a estória de ajuda a explicar . O sistema acima, a propósito, pode ser representando da seguinte forma, como faz Tsay (2008) :
, significa dizer que a estória de ajuda a explicar . O sistema acima, a propósito, pode ser representando da seguinte forma, como faz Tsay (2008) :
![\[z_{t} = \phi_{0} + \phi_{1} z_{t-1} + \alpha_{t}\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-90fb7281492fa16367bc9568c66ea444_l3.png "Rendered by QuickLaTeX.com")
Ou, ainda, como
![\[\begin{bmatrix} z_{1t} \\ z_{2t} \end{bmatrix} = \begin{bmatrix} \phi_{10} \\ \phi_{20} \end{bmatrix} + \begin{bmatrix} \phi_{1,11} & \phi_{1,12} \\ \phi_{1,21} & \phi_{1,22} \end{bmatrix} \begin{bmatrix} z_{1, t-1} \\ z_{2, t-1} \end{bmatrix} + \begin{bmatrix} \alpha_{1t} \\ \alpha_{2t} \end{bmatrix}\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-b9b4965d07a0ca17ac30cc9c4a63475e_l3.png "Rendered by QuickLaTeX.com")
Esse sistema de ordem 1, a propósito, pode ser generalizado para qualquer ordem  como
como
![\[z_{t} = \phi_{0} + \sum_{i=1}^{p} \phi_{i} z_{t-i} + \alpha_{t}\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-d8bf85a158f05646ab8f74d6036a13b5_l3.png "Rendered by QuickLaTeX.com")
{#eq-varp}
onde  para
para  é uma vetor
é uma vetor  contendo observações de
contendo observações de  séries temporais,
séries temporais,  é um vetor de interceptos,
é um vetor de interceptos,  é uma matriz
é uma matriz  de coeficientes e
de coeficientes e  é um vetor de erros, independentes e identicamente distribuídos, com média zero e covariância igual a
é um vetor de erros, independentes e identicamente distribuídos, com média zero e covariância igual a  .
.
É conveniente representar @varp com a utilização do operador defasagem  como
como
![\[\phi (L) z_{t} = \phi_{0} + \alpha_{t}\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-6f3c7f7da6632065e71b57387b4c8f78_l3.png "Rendered by QuickLaTeX.com")
Supondo que as séries em destaque sejam estacionárias, podemos estimar um VAR entre elas.
Para isso, devemos primeiro definir a ordem de defasagem. Isso é feito abaixo.
Para isso, devemos primeiro definir a ordem de defasagem. Isso é feito abaixo.
Código
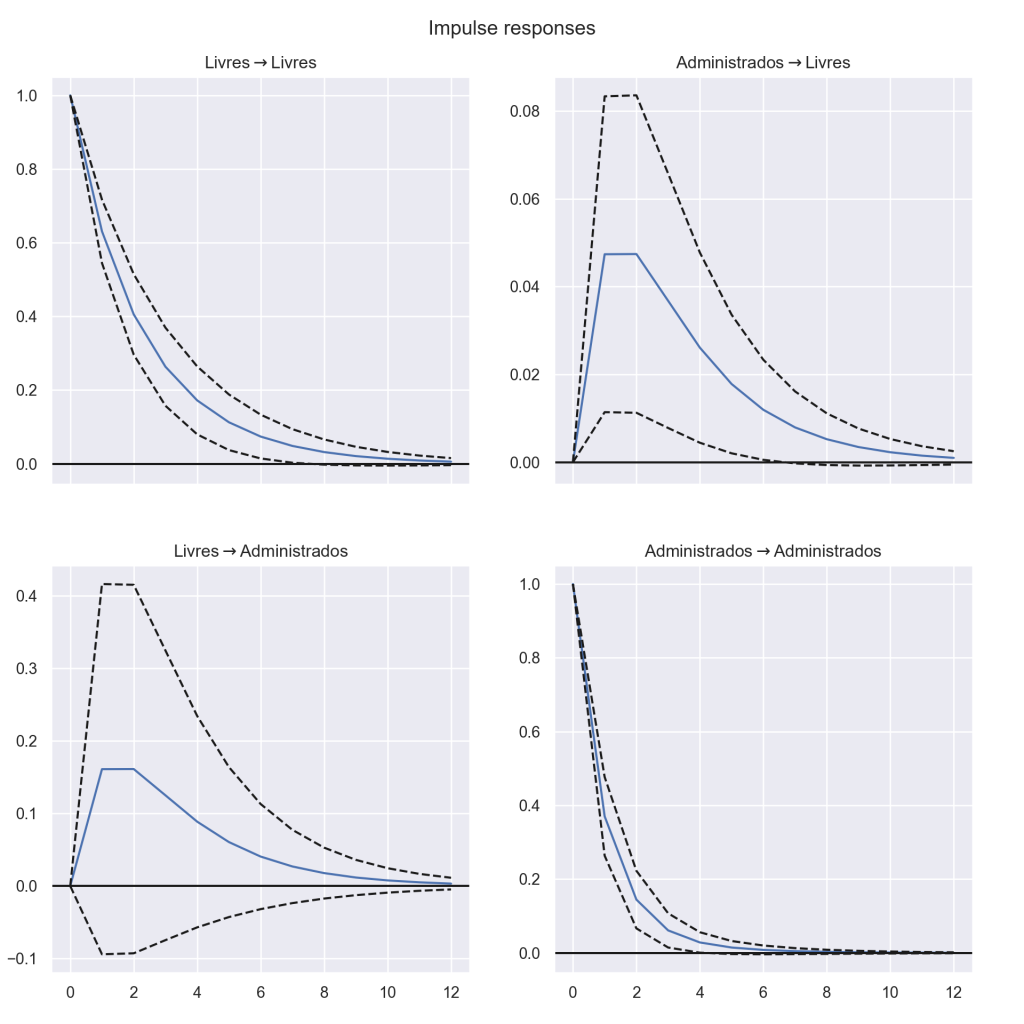
{'aic': 1, 'bic': 1, 'hqic': 1, 'fpe': 1}Pelo resultado, vemos que a melhor seleção será um VAR(1). Após estimar o VAR, verificamos a autocorrelação dos resíduos.Por fim, verificamos o choque das variáveis, conforme uma função impulso resposta. O resultado é visto abaixo:

Pelo gráfico acima, verificamos que há um efeito positivo de um choque do IPCA Administrado sobre o IPCA livres.
Quer aprender mais?
- Cadastre-se gratuitamente aqui no Boletim AM e receba toda terça-feira pela manhã nossa newsletter com um compilado dos nossos exercícios com exemplos reais de análise de dados envolvendo as áreas de Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas;
- Quer ter acesso aos códigos, vídeos e scripts de R/Python desse exercício? Vire membro do Clube AM aqui e tenha acesso à nossa Comunidade de Análise de Dados;
- Quer aprender a programar em R ou Python com Cursos Aplicados e diretos ao ponto em Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas? Veja nossos Cursos aqui.

