Previsão de séries econômicas com Python: um exemplo prático com VECM e desemprego
Existem inúmeras formas de prever uma série econômica. E isso pode deixar qualquer iniciante confuso. As perguntas aparecem logo de cara: quais variáveis usar? Qual o melhor modelo? Econométrico? Estatístico? Machine Learning? Como medir a acurácia das previsões?
Neste post, não vamos apresentar um tutorial completo. Para isso, temos nossos cursos de Modelagem e Previsão com Python e Previsão Macroeconômica usando Python e IA, onde cobrimos tudo em profundidade. Aqui, nosso objetivo é simples: mostrar como estruturar uma previsão econômica usando Python e um modelo econométrico, o VECM (Modelos de Correção de Erro Vetorial), aplicado à taxa de desemprego no Brasil.
Para obter o código e o tutorial deste exercício faça parte do Clube AM e receba toda semana os códigos em R/Python, vídeos, tutoriais e suporte completo para dúvidas.
Etapas da modelagem da Previsão
Começamos com uma escolha pré-definida de variáveis explicativas. Em seguida, fazemos a visualização dos dados, estimamos o modelo, avaliamos os resíduos (autocorrelação e normalidade) e validamos se a especificação está adequada. Depois, realizamos a previsão dentro da amostra e, por fim, a previsão fora da amostra.
Não temos aqui a intenção de comparar acurácia entre modelos. Nosso foco é mostrar que é possível criar um ambiente de previsão econométrica no Python de forma simples e eficaz.
Quais dados usamos para a previsão da taxa de desemprego?
Para esse exercício, usamos dados mensais de março de 2012 até janeiro de 2025, totalizando 155 observações. As variáveis são:
-
Taxa de desocupação (IBGE/Sidra);
-
Indicador Antecedente de Emprego (IAEmp), com ajuste sazonal (FGV);
-
Indicador de Incerteza da Economia Brasileira (IIE-Br) (FGV);
-
Índice de Atividade Econômica (IBC-Br) com ajuste sazonal (BCB);
-
Taxa de juros Selic acumulada no mês anualizada (BCB).
A coleta foi feita com bibliotecas específicas: sidrapy para a taxa de desocupação, python-bcb para os dados do Banco Central, e os dados da FGV foram baixados manualmente e importados via CSV no Python.
Abaixo a tabela com as primeiras observações dos dados capturados.
Visualizando as séries para previsão
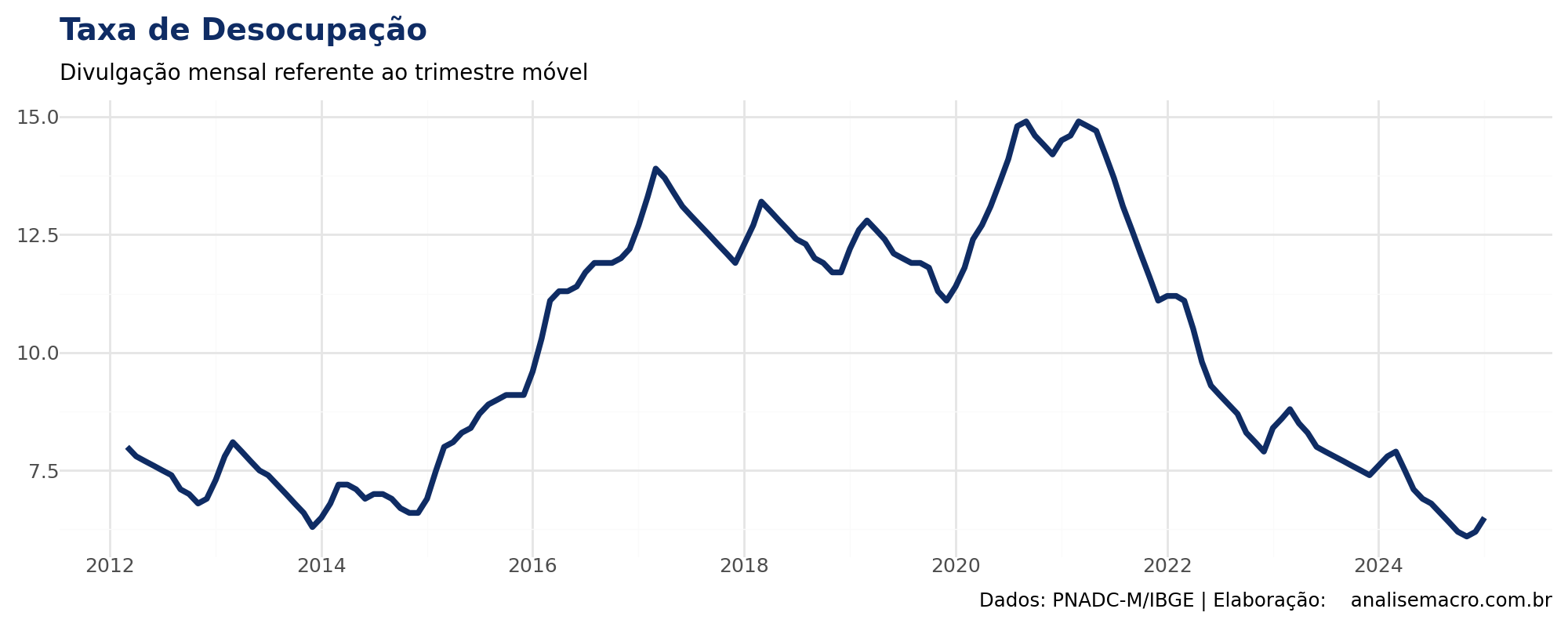
Ao visualizar a taxa de desemprego, é clara a existência de tendência estrutural em alguns períodos, como alta pós-2015 e queda no pós-pandemia. Observa-se também sazonalidade recorrente, um padrão típico de séries mensais.
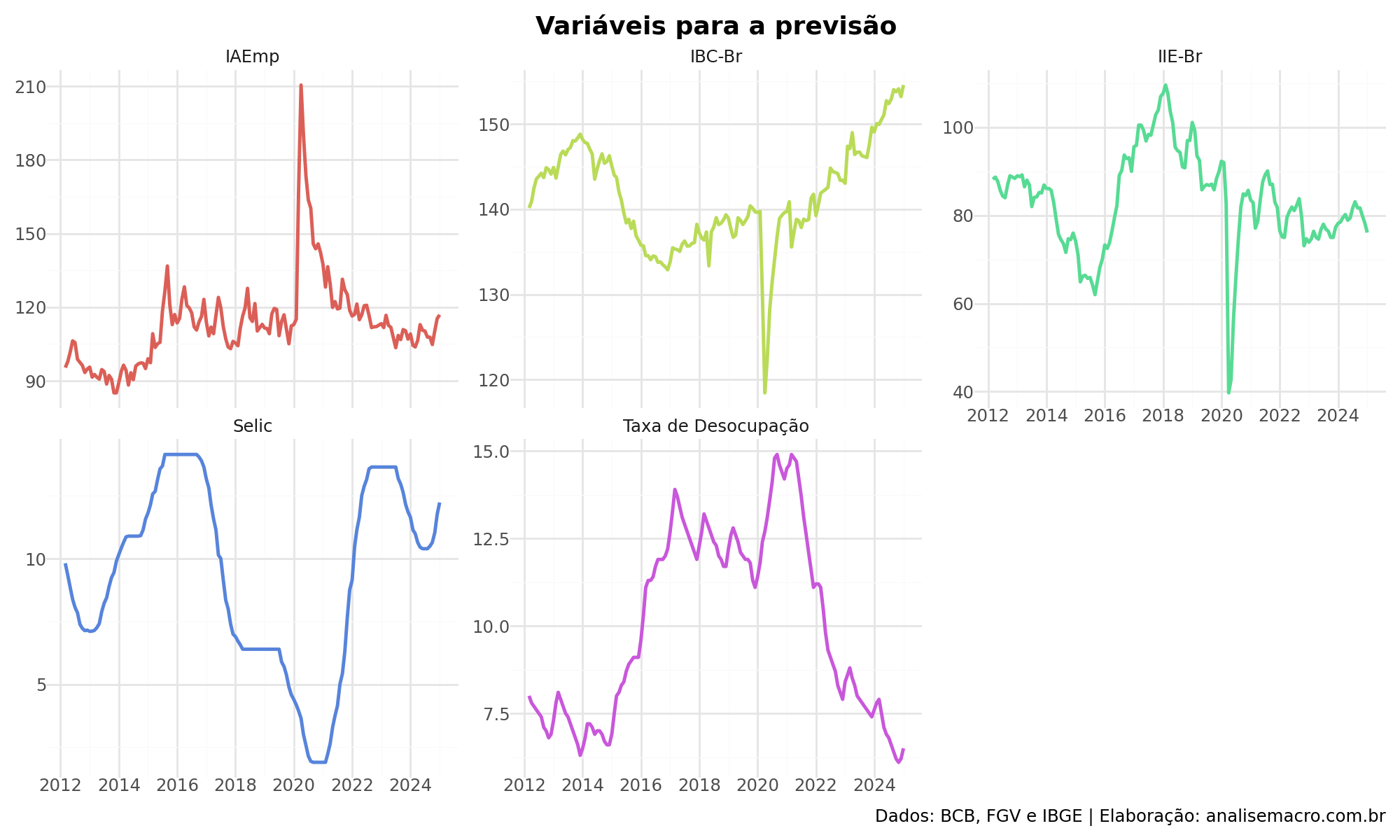
As demais variáveis também apresentam comportamento interessante. Por exemplo, o IIE-Br, IAEmp e o IBC-Br acompanham os movimentos da taxa de desemprego durante crises. O primeiro e segundo reflete o humor empresarial e o segundo a atividade econômica geral. Já a taxa Selic atua como freio ou acelerador da economia, influenciando a geração de empregos. O IAEmp funciona como indicador antecedente, ajudando a prever os movimentos futuros do desemprego.
Estimando o modelo VECM no Python
Antes de estimar um VECM é importante saber sobre algumas questões.
Todas as séries são integradas de ordem 1 (I(1)), ou seja, não estacionárias em nível, mas estacionárias em primeira diferença. Isso exige que verifiquemos a cointegração, já que as variáveis podem ter relação de longo prazo. A modelagem via VECM captura essas dinâmicas, sendo ideal para esse tipo de dado. Toda essa análise é verificado no código de criação do exercício.
Estimamos um modelo VECM com rank de cointegração 1 e 1 defasagem. Além disso, adicionamos dummies sazonais para capturar a sazonalidade da taxa de desemprego. O modelo é todo criado a partir dos módulos de séries temporais da biblioteca statsmodels .
Avaliamos os resíduos por meio de gráficos de autocorrelação e histogramas. O diagnóstico mostrou baixa autocorrelação e resíduos bem comportados, indicando boa especificação do modelo.
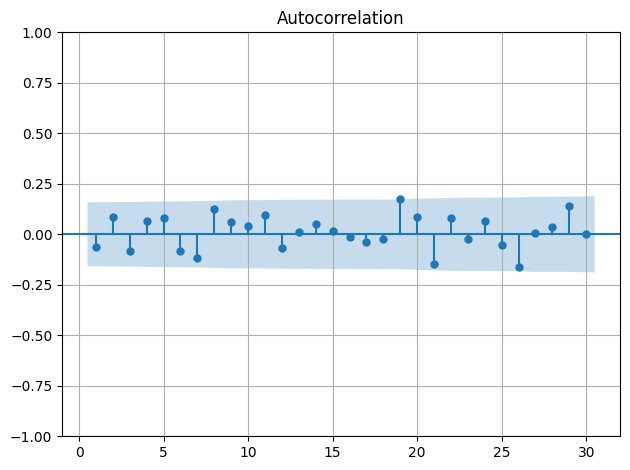
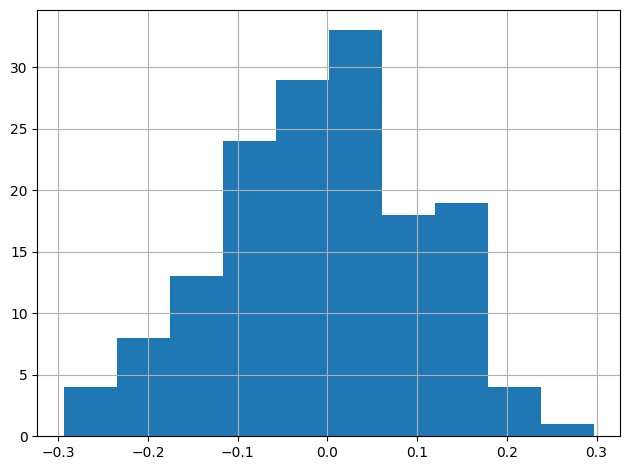
Previsão dentro da amostra
Realizamos a previsão para os últimos 12 meses da série. Isso permite comparar os valores previstos com os valores reais, avaliando a performance do modelo. Os intervalos de confiança ajudam a entender a incerteza das previsões.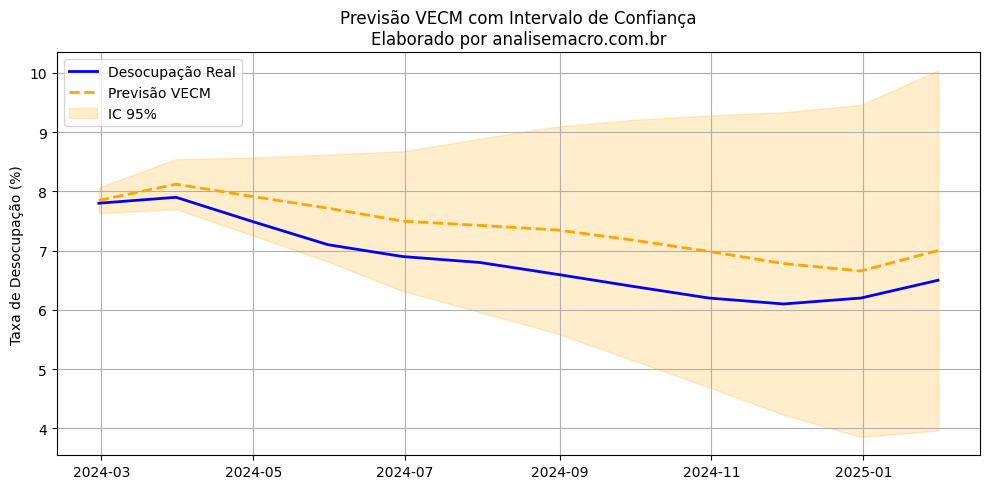
Claro, o ideal seria comparar diferentes modelos e combinações de variáveis. Mas, para fins didáticos, essa estrutura já entrega muito. Quem quiser se aprofundar, pode conferir nossos cursos de previsão.
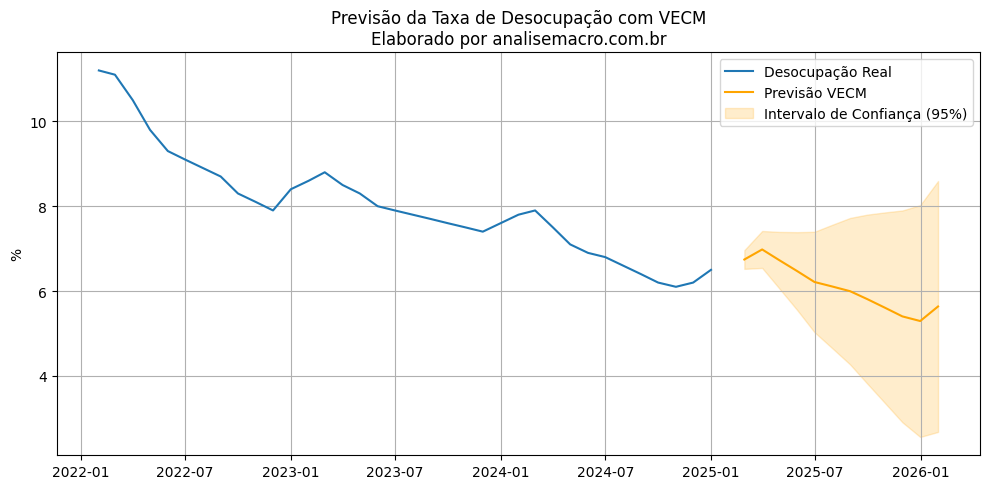
Previsão fora da amostra
Com o modelo validado, projetamos a série de desemprego para os 12 meses seguintes. O resultado aponta uma leve inflexão de curto prazo e possível queda futura. Como esperado, o intervalo de confiança se alarga com o horizonte de previsão, refletindo a incerteza.
Também prevemos o comportamento futuro das demais variáveis do sistema, o que ajuda a entender como cada componente afeta a taxa de desemprego ao longo do tempo.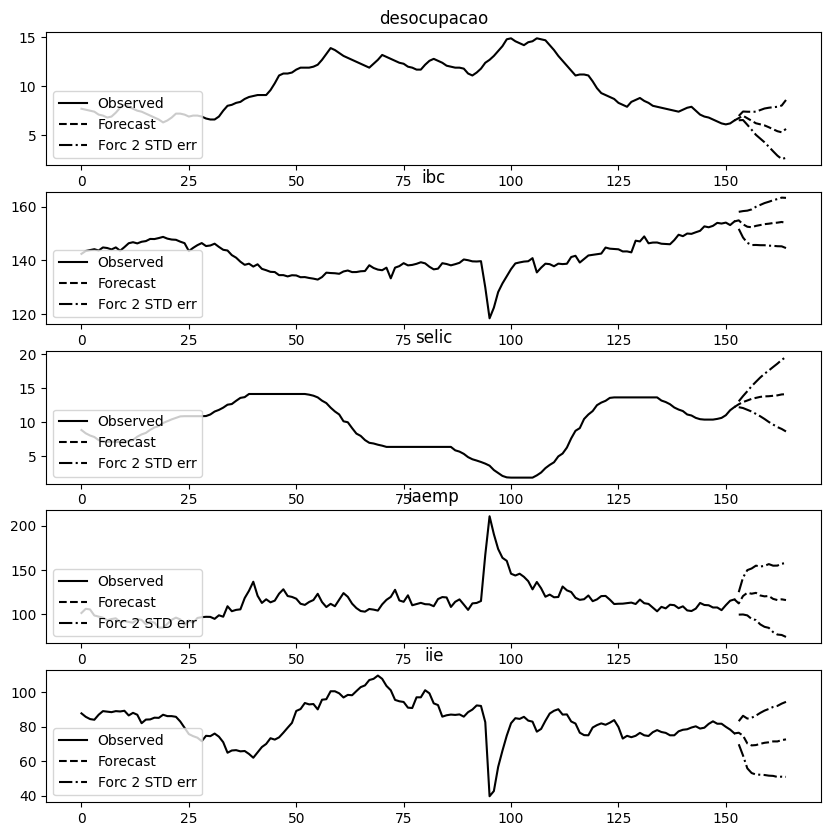
Considerações Finais
Prever séries econômicas pode parecer complexo à primeira vista. Mas com o uso correto das bibliotecas do Python, um bom entendimento dos dados e um modelo adequado como o VECM, é possível montar um pipeline de previsão eficiente, interpretável e aplicável à realidade econômica.
Quer aprender mais?
Conheça nossa Formação do Zero à Análise de Dados Econômicos e Financeiros usando Python e Inteligência Artificial. Aprenda do ZERO a coletar, tratar, construir modelos e apresentar dados econômicos e financeiros com o uso de Python e IA.
Referências
SEABOLD, Skipper; PERKTOLD, Josef. Vector Autoregressions (VAR) and Vector Error Correction Models (VECM). Statsmodels, 2024. Disponível em: https://www.statsmodels.org/stable/vector_ar.html#vector-error-correction-models-vecm. Acesso em: 9 abr. 2025.

