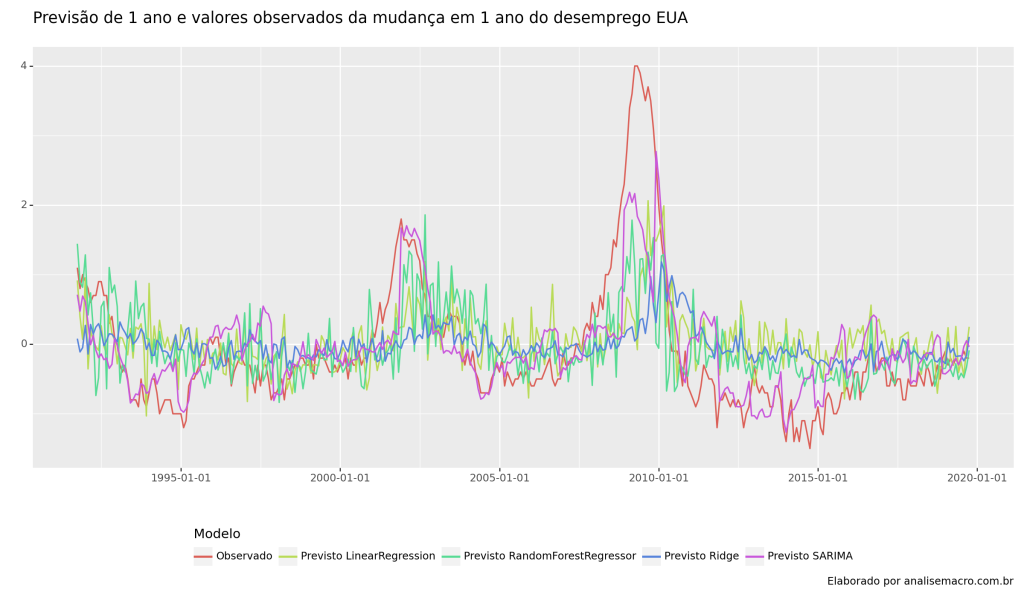
Neste exercício, exploramos como o framework da biblioteca skforecast do Python pode ser extremamente útil para a previsão de séries temporais econômicas, utilizando como exemplo as variações no desemprego dos EUA ao longo de um horizonte de 1 ano.
Introdução
Prever dinâmicas de séries temporais pode ser um desafio, especialmente quando se trata de variáveis macroeconômicas. Isso se deve ao fato de que as relações entre variáveis podem mudar ao longo do tempo, e eventos inesperados, como recessões ou crises financeiras, podem alterar as relações previamente observadas. No entanto, pesquisas demonstraram que métodos de aprendizado de máquina frequentemente superam os modelos econométricos tradicionais na previsão de indicadores como desemprego, inflação e nível de atividade econômica.
Neste estudo, desenvolvemos uma previsão para a variação do desemprego dos EUA em um horizonte de 1 ano, com base no trabalho de Buckmann, Joseph e Robertson (2021). A seguir, apresentamos uma descrição simplificada do método utilizado.
Metodologia
Dados
Utilizou-se o banco de dados macroeconômicos FRED-MD, que abrange uma série de 127 indicadores econômicos dos EUA, com dados disponíveis desde 1959 até 2019 (ano da amostra utilizada, embora existam dados mais recentes disponíveis).
A seguir, apresentamos uma tabela com as variáveis utilizadas:
| Variável | Transformação | Nome no banco de dados FRED-MD | Código | Fórmula |
|---|---|---|---|---|
| Desemprego | Diferenças | UNRATE | 2 | ∆xₜ |
| Título do tesouro de 3 meses | Diferenças | TB3MS | 2 | ∆xₜ |
| Inclinação da curva de juros | Diferenças | – | 2 | ∆xₜ |
| Renda pessoal real | Diferenças logarítmicas | RPI | 5 | ∆log(xₜ) |
| Produção industrial | Diferenças logarítmicas | INDPRO | 5 | ∆log(xₜ) |
| Consumo | Diferenças logarítmicas | DPCERA3M086SBEA | 5 | ∆log(xₜ) |
| S&P 500 | Diferenças logarítmicas | S&P 500 | 5 | ∆log(xₜ) |
| Empréstimos empresariais | Diferenças logarítmicas de segunda ordem | BUSLOANS | 6 | ∆²log(xₜ) |
| IPC | Diferenças logarítmicas de segunda ordem | CPIAUCSL | 6 | ∆²log(xₜ) |
| Preço do petróleo | Diferenças logarítmicas de segunda ordem | OILPRICEx | 6 | ∆²log(xₜ) |
| Dinheiro M2 | Diferenças logarítmicas de segunda ordem | M2SL | 6 | ∆²log(xₜ) |
Cada variável no banco de dados FRED-MD possui um nome e um código específico que indica a transformação necessária para tornar a série estacionária. No exercício, extraímos as séries e aplicamos as transformações necessárias.
Um aspecto importante é a escolha da defasagem para cada método de transformação. É possível selecionar diferentes defasagens para cada variável. No nosso caso, utilizamos uma defasagem de 12 meses para o desemprego, pois queremos prever a mudança de um ano para o outro. Para as demais variáveis, optamos por uma defasagem de 3 meses.
Modelos Utilizados
Os seguintes modelos foram empregados para prever as mudanças no desemprego com um ano de antecedência:
- SARIMA
- Regressão Linear
- Regressão Ridge
- Regressão Lasso
- Random Forest
- Support Vector Regression
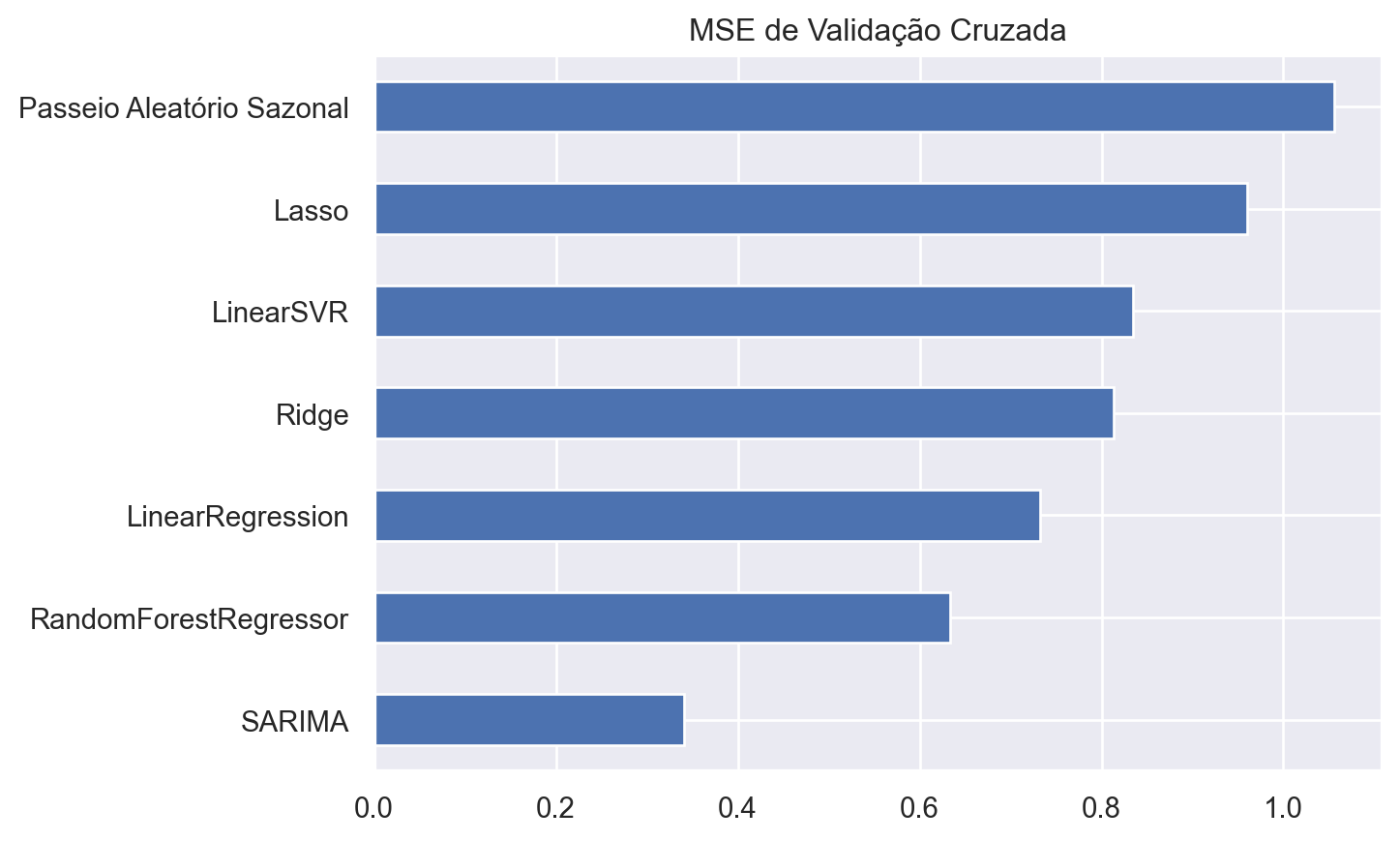
Após transformar as variáveis (conforme detalhado na tabela) e remover os valores ausentes, a primeira observação no conjunto de treinamento é de fevereiro de 1962. Todos os modelos foram avaliados com base em 346 pontos de dados de previsões entre janeiro de 1990 e novembro de 2019, utilizando uma abordagem de validação cruzada com janela expansiva. Os modelos foram recalibrados a cada 12 meses, permitindo que cada modelo realizasse 12 previsões antes de ser atualizado.
Abaixo, o código apresenta os procedimentos para coleta, tratamento, análise e previsão da variável dependente, finalizando com a avaliação da performance dos modelos por meio da métrica MSE.
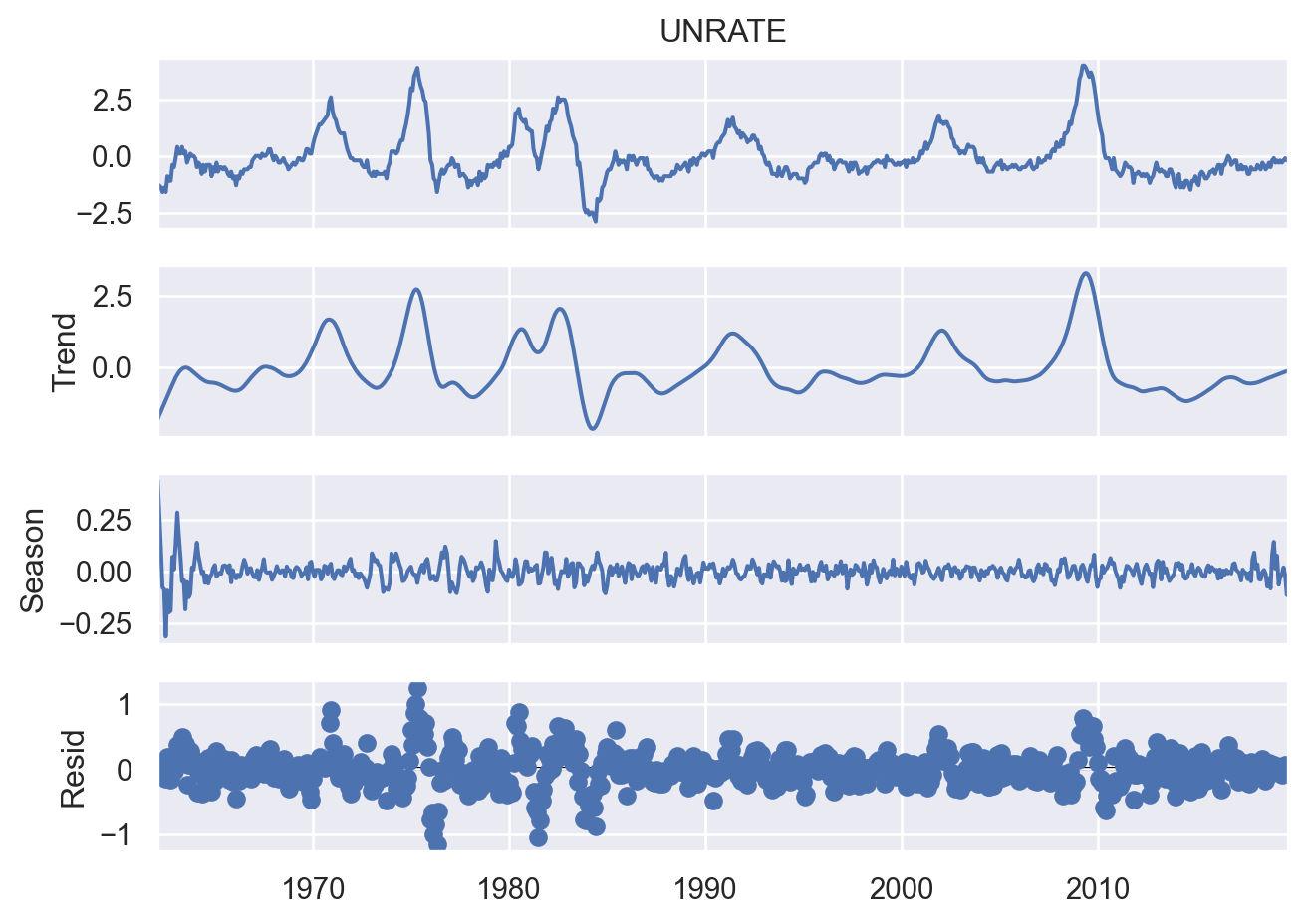
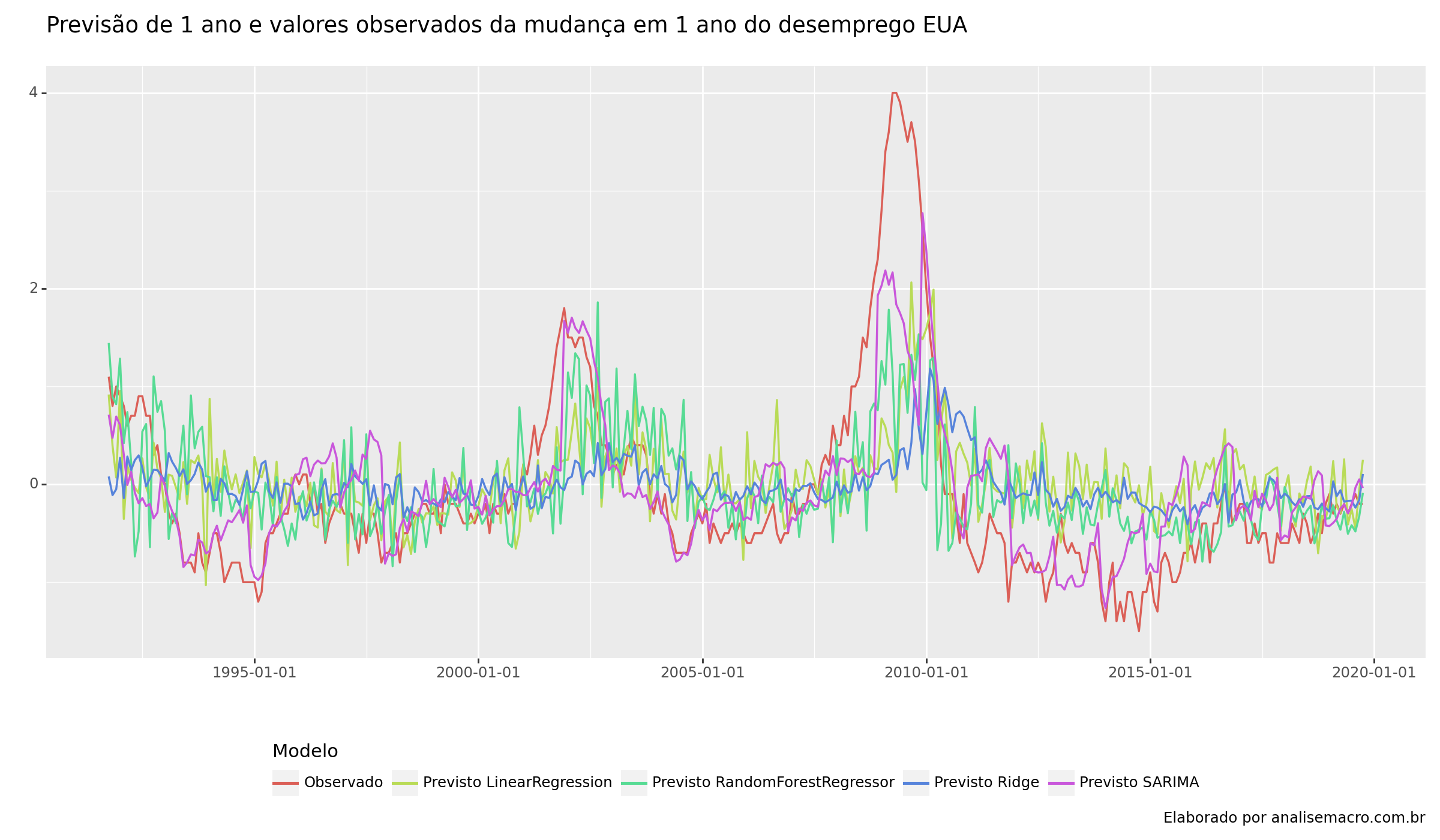
Visualização de dados
Resultados
Referências
Buckmann, M., Joseph, A. e Robertson, H. (2021). Opening the black box: Machine learning interpretability and inference tools with an application to economic forecasting. Data Science for Economics and Finance: Methodologies and Applications(pp. 43-63). Springer International Publishing.
fg-research. An overview of the FRED-MD database. Acesso em: https://fg-research.com/blog/general/posts/fred-md-overview.html#code
McCracken, M. W., & Ng, S. (2016). FRED-MD: A monthly database for macroeconomic research. Journal of Business & Economic Statistics, 34(4), 574-589. doi: 10.1080/07350015.2015.1086655.
Quer aprender mais?
Clique aqui para fazer seu cadastro no Boletim AM e baixar o código que produziu este exercício, além de receber novos exercícios com exemplos reais de análise de dados envolvendo as áreas de Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas diretamente em seu e-mail.

