Nosso objetivo neste exercício será estender a taxa de desemprego fornecida pela Pesquisa de Nacional por Amostra de Domicílios Contínua (PNAD Contínua) através daquela fornecida pela Pesquisa Mensal de Emprego (PME). Serão construídas duas séries: uma normal, outra dessazonalizada. Faremos todo o exercício utilizando o Python.
PNADC e PME
A Taxa de desocupação, na semana de referência, das pessoas de 14 anos ou mais de idade, conhecida como Taxa de Desocupação medida pela PNADc, abrange todo o território nacional e é mensurada como uma taxa de variação em trimestres móveis. A série teve início em 2012.
Já a PME, Pesquisa Mensal de Emprego, foi encerrada em março de 2016, com a divulgação dos resultados referentes ao mês de fevereiro de 2016. Ela abrangia seis Regiões Metropolitanas (Recife, Salvador, Belo Horizonte, Rio de Janeiro, São Paulo e Porto Alegre). Diferente da PNADc não é mensurada em trimestres móveis.
Os alunos do curso de Macroeconometria usando o Python, têm a oportunidade de adquirir um conhecimento abrangente em todas as fases do processo, desde a coleta e a preparação dos dados até a análise, o desenvolvimento de modelos econométricos e a comunicação dos resultados, tudo isso utilizando Python como ferramenta principal.
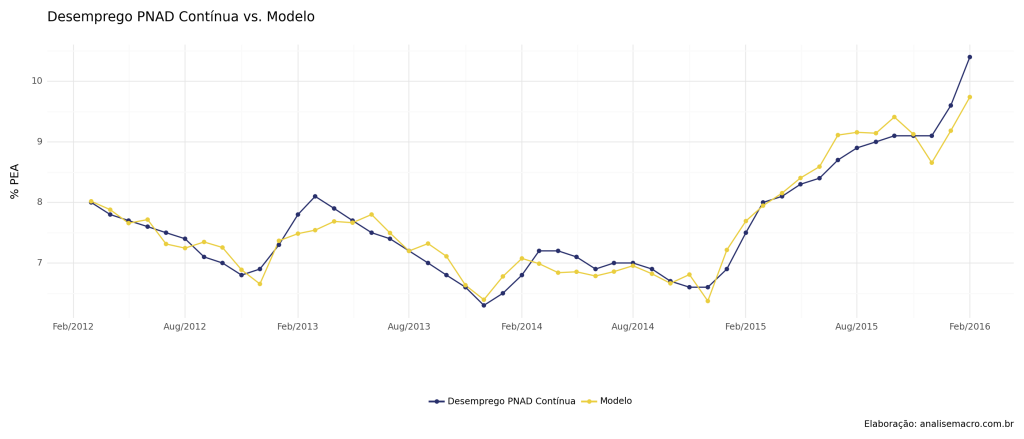
No gráfico abaixo, verificamos a duas séries no período em que foram divulgadas simultaneamente, de 2012 até 2016.
 Temos agora um conjunto de dados com a intersecção das duas séries, começando em março de 2012 e indo até fevereiro de 2016. Plotamos as duas abaixo.
Temos agora um conjunto de dados com a intersecção das duas séries, começando em março de 2012 e indo até fevereiro de 2016. Plotamos as duas abaixo.
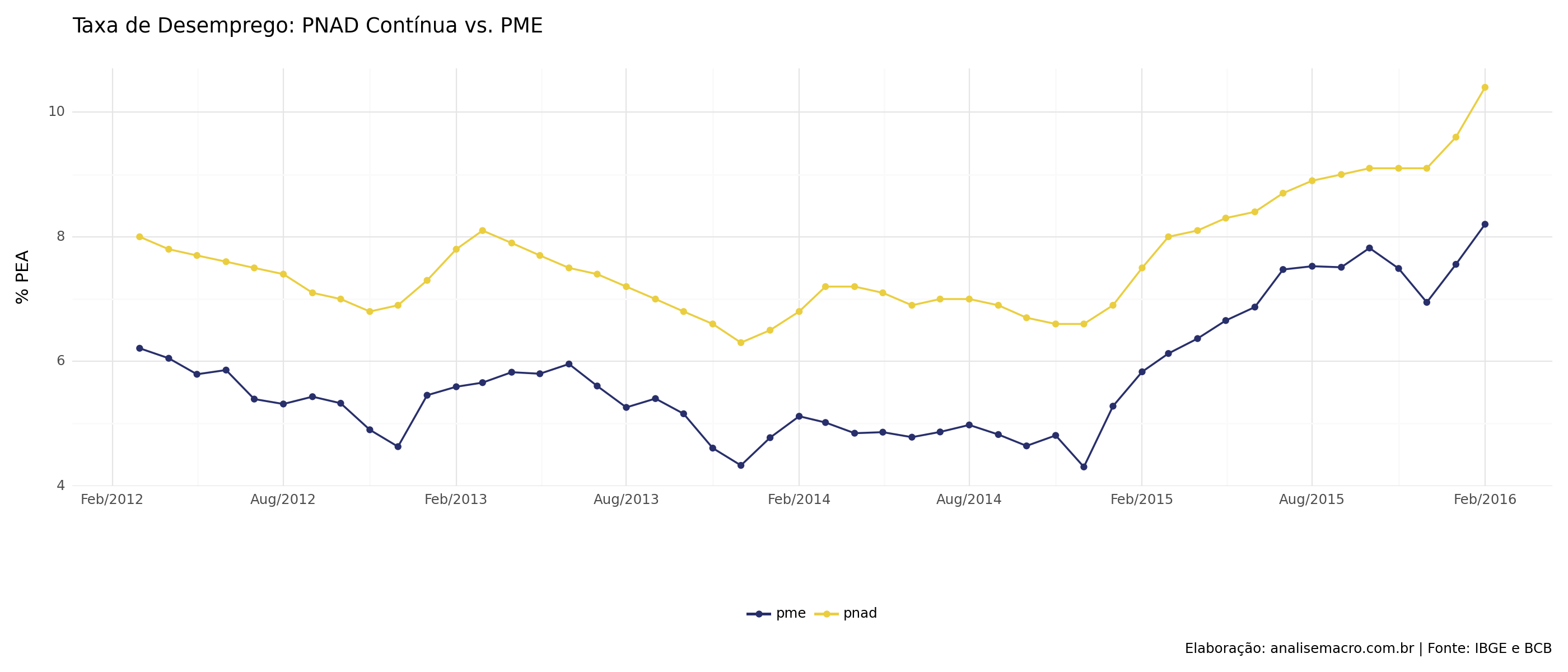
O gráfico nos mostra que a série da PNAD Contínua tem uma média maior do que a da PME, bem como é um pouco mais suave, refletindo o fato de que a mesma é uma média trimestral móvel. Ambas as séries caminham, entretanto, de forma parecida, a despeito da diferença da amostra. Abaixo as estatísticas descritivas das duas séries.
Código
| pnad | pme | |
|---|---|---|
| count | 48.000000 | 48.000000 |
| mean | 7.604167 | 5.730090 |
| std | 0.908578 | 1.010961 |
| min | 6.300000 | 4.304397 |
| 25% | 6.900000 | 4.892217 |
| 50% | 7.400000 | 5.443909 |
| 75% | 8.025000 | 6.147074 |
| max | 10.400000 | 8.201058 |
Exercício: Ampliando a série da PNAD
Uma vez definido o conjunto de dados, passemos ao exercício em si. Como o nosso objetivo é basicamente expandir a taxa de desemprego da PNAD Contínua, vamos então regredir a mesma contra a taxa da PME. O resultado dos valores ajustados da PNADc são demonstrados abaixo, comparando-os com a série original.
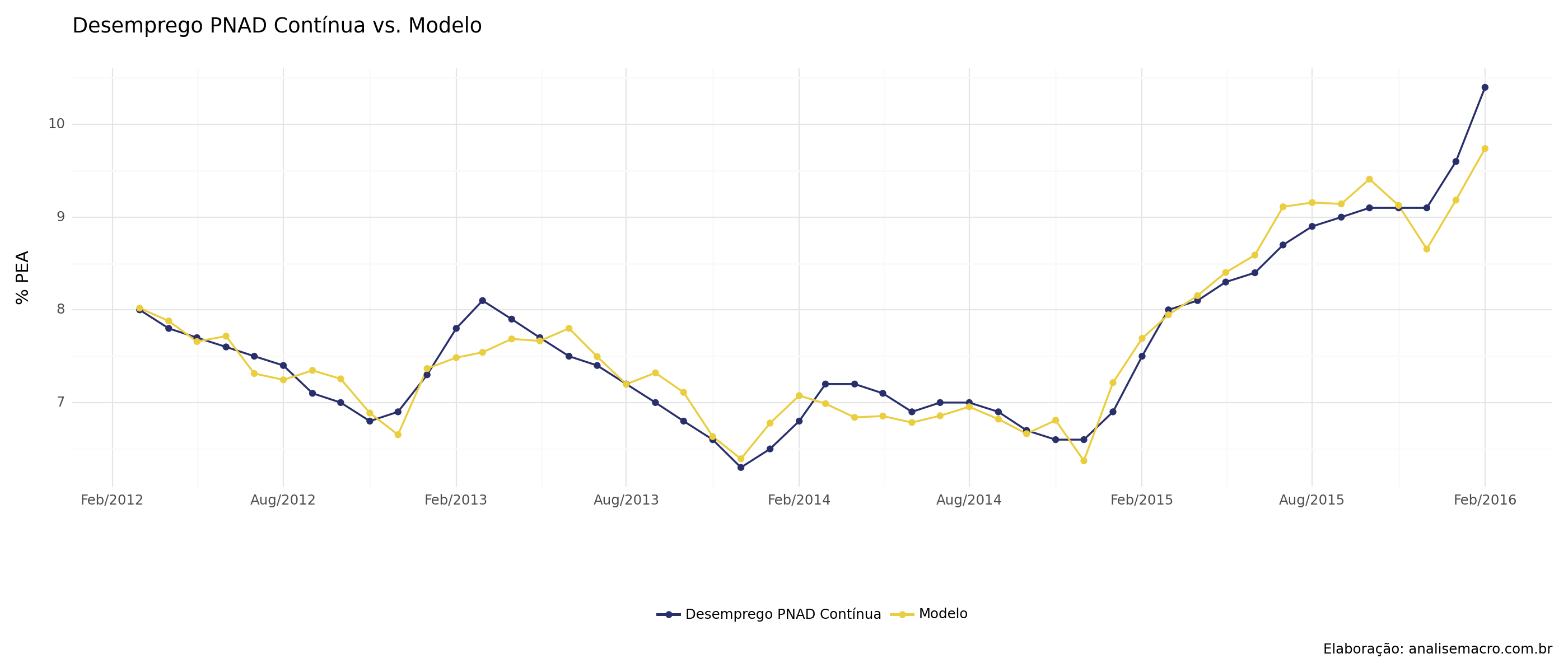
Valores Ampliados da PNADc
De posse dos valores estimados, criamos uma ampliação da PNADc adicionando o intercepto e multiplicando o coeficiente estimado da regressão pelos valores históricos da PME. Isso permite que tenhamos uma ampliação da série da PNADc. Os valores ampliados são visualizados abaixo:
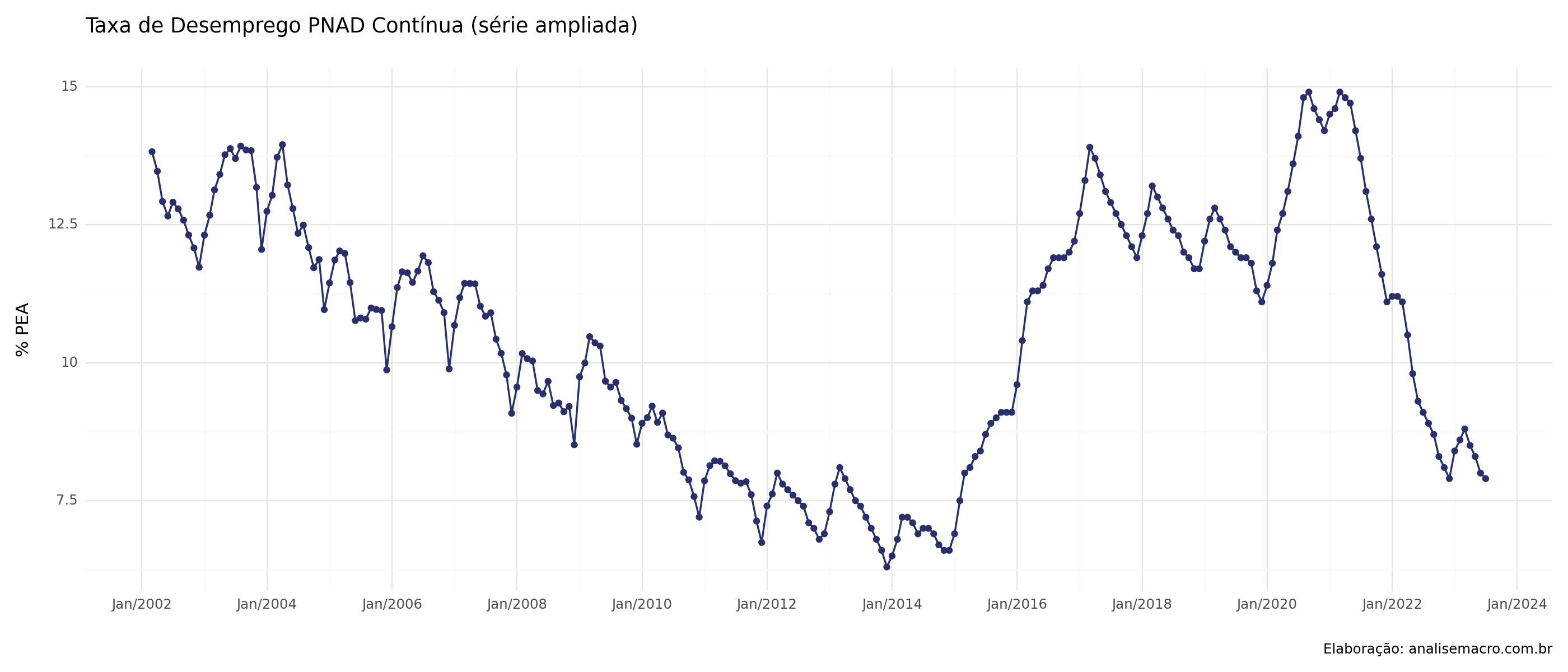
Dessazonalização
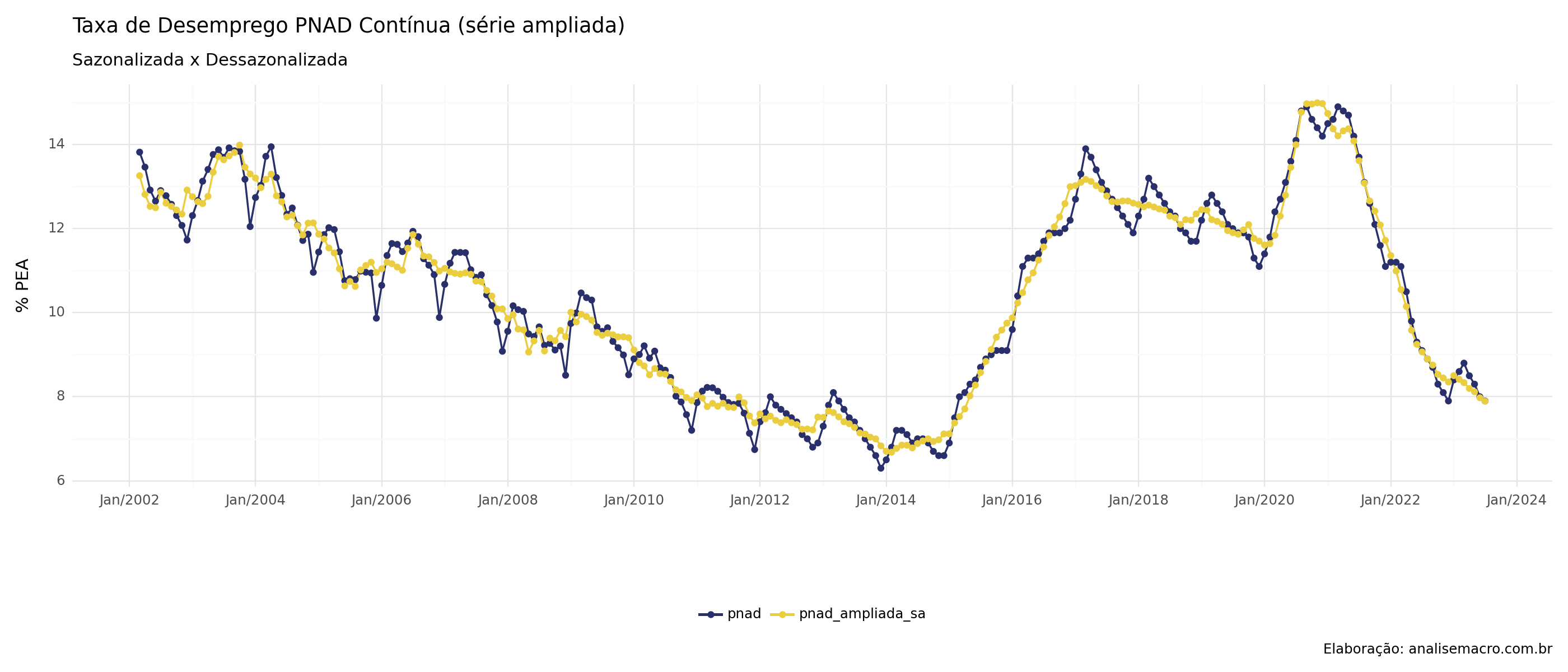
Podemos, agora, dessazonalizar a nossa taxa de desemprego. Usamos o algoritmo x13-arima-seats. Comparamos os novos valores com a série ampliando pelo gráfico abaixo.
Quer aprender mais?
Clique aqui para fazer seu cadastro no Boletim AM e baixar o código que produziu este exercício, além de receber novos exercícios com exemplos reais de análise de dados envolvendo as áreas de Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas diretamente em seu e-mail.

