[et_pb_section admin_label="section"][et_pb_row admin_label="row"][et_pb_column type="1_2"][et_pb_text admin_label="Texto" background_layout="light" text_orientation="justified" text_font="Abel||||" text_font_size="21" use_border_color="off" border_color="#ffffff" border_style="solid"]
O IBGE divulgou hoje os resultados da PNAD Contínua referentes ao trimestre móvel encerrado em junho último. De uma população de pouco mais de 208 milhões de pessoas, quase 13 milhões encontravam-se desocupadas naquele período. Esse número é 3,9% menor do que o registrado no trimestre móvel encerrado em junho do ano passado. Na mesma métrica, a população ocupada aumentou 1,1% e a população economicamente ativa (PEA) teve aumento de 0,5%. Em termos percentuais, o desemprego atingiu 12,4% da PEA. Na sequência do post, coletamos e tratamos dados da PNAD Contínua com códigos de R que são detalhadamente explicados em nosso Curso de Análise de Conjuntura usando o R.
[/et_pb_text][/et_pb_column][et_pb_column type="1_2"][et_pb_image admin_label="Imagem" src="https://analisemacro.com.br/wp-content/uploads/2018/07/post.png" show_in_lightbox="off" url="https://analisemacro.com.br/cursos-de-r/" url_new_window="off" use_overlay="off" animation="off" sticky="off" align="center" force_fullwidth="off" always_center_on_mobile="on" use_border_color="off" border_color="#ffffff" border_style="solid"]
[/et_pb_image][/et_pb_column][/et_pb_row][et_pb_row admin_label="row"][et_pb_column type="4_4"][et_pb_text admin_label="Texto" background_layout="light" text_orientation="justified" text_font="Abel||||" text_font_size="21" use_border_color="off" border_color="#ffffff" border_style="solid"]
Com o uso do R, é possível integrar em um único ambiente a coleta, tratamento e apresentação de dados como os da PNAD Contínua, gerando um produto final como esse aqui sem a necessidade de abrir múltiplos programas ou perder tempo entrando em sites para baixar dados. Tudo é feito via uma plataforma integrada como o RStudio, que possibilita um aumento incrível de produtividade. A começar pela coleta de dados, que hoje já pode ser feita de uma base de dados como o SIDRA com um pacote do R, como no código a seguir.
library(sidrar) ### Coletar dados no SIDRA IBGE data = get_sidra(api='/t/6022/n1/all/v/606/p/all')
Os dados coletados, naturalmente, estão desorganizados, de modo que é preciso tratá-los, transformando-os em uma matriz amigável para que se possa fazer uma exploração dos mesmos via, por exemplo, construção de gráficos. Essa etapa é particularmente importante para quem lida com dados todos os dias, de modo que passamos um tempo considerável do nosso Curso de Análise de Conjuntura usando o R mostrando para os alunos como utilizar o R para essa tarefa. Uma vez que o código esteja pronto, sua tarefa de coleta e tratamento de dados está automatizada, de modo que da próxima vez que você for atualizar os dados, perdera minutos nessa etapa. Isto é, poderá se concentrar na parte de análise e comunicação de resultados, sofisticando de modo bastante interessante suas apresentações.
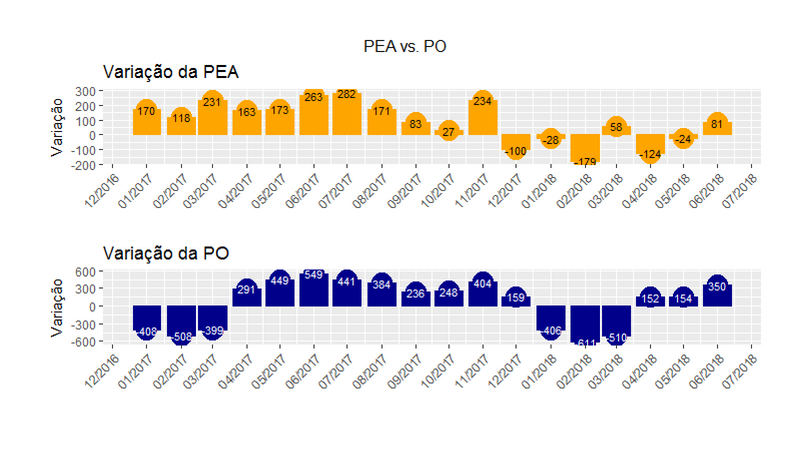
Seus gráficos ficarão bem mais ilustrativos, o que lhe trará maiores insights para desenvolver argumentos econômicos mais sólidos, bem como fomentar a etapa posterior de modelagem e previsão, que pode ser vista nos cursos de Séries Temporais e Construção de Cenários e Previsões. Não perca tempo e venha já para o mundo do R!
[/et_pb_text][et_pb_image admin_label="Imagem" src="https://analisemacro.com.br/wp-content/uploads/2017/11/cursosaplicados.png" show_in_lightbox="off" url="https://analisemacro.com.br/cursos-de-r/" url_new_window="off" use_overlay="off" animation="off" sticky="off" align="center" force_fullwidth="off" always_center_on_mobile="on" use_border_color="off" border_color="#ffffff" border_style="solid"]
[/et_pb_image][/et_pb_column][/et_pb_row][/et_pb_section]

