[et_pb_section admin_label="section"][et_pb_row admin_label="row"][et_pb_column type="4_4"][et_pb_text admin_label="Texto" background_layout="light" text_orientation="justified" text_font="Verdana||||" text_font_size="18" use_border_color="off" border_color="#ffffff" border_style="solid"]
Há muitas ideias equivocadas (e mesmo estapafúrdias) sendo ventiladas por aí quando o assunto é juro alto no Brasil. Há os que defendem, por exemplo, que o juro alto é consequência única e exclusiva da ganância de banqueiros. Como se os banqueiros brasileiros fossem mais gananciosos do que seus pares no resto do mundo. Há também aqueles que acham que o spread bancário, a diferença entre a taxa de captação de recursos pelos bancos e aquela taxa cobrada em empréstimos, deve ser reduzido na marra, por meio dos bancos públicos. Como se isso não tivesse sido tentado recentemente, com o fracasso já esperado. Essas e outras ideias são apenas exemplos de como o debate econômico no Brasil é contaminado por falta de entendimento da teoria e também da evidência empírica disponível. Nesse post, fazendo uso da relação entre inadimplência e spread bancário, mostro como economistas sérios orientam a construção de políticas eficazes para redução do juro alto no país - Saiba como fazer análises como essa em nossos Cursos Aplicados de R..
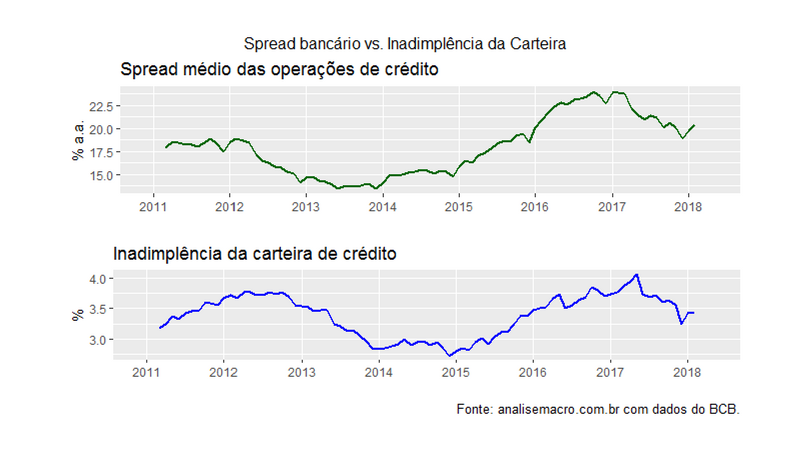
É razoável supor que inadimplência e spread bancário são variáveis que andam juntas ao longo do tempo. Isto é, tanto a inadimplência exerce influência sobre o spread, como o caso contrário. Isso é facilmente demonstrado pelo procedimento de Toda-Yamamoto, operacionalizado no código abaixo.
library(BETS) library(ggplot2) library(forecast) library(gridExtra) library(vars) library(aod) ## Dados inad = BETS.get(21082) spread = BETS.get(20783) data = ts.intersect(spread, inad) df = data.frame(inad=data[,2], spread=data[,1]) ### Toda-Yamamoto ### Selecionar Defasagem def = VARselect(df,lag.max=12,type="both") def$selection var10 = VAR(df, p=10, type='both') serial.test(var10) ### Teste de Wald var11 = VAR(df, p=11, type='both') ### Wald Test 01: Spread não granger causa inadimplência wald.test(b=coef(var11$varresult[[1]]), Sigma=vcov(var11$varresult[[1]]), Terms=c(2,4,6,8,10,12,14,16,18,20)) ### Wald Test 02: Inadimplência não granger causa spread wald.test(b=coef(var11$varresult[[2]]), Sigma=vcov(var11$varresult[[2]]), Terms= c(1,3,5,7,9,11,13,15,17,19))
Caso o leitor queira reproduzir o exercício, verá que de fato há uma causalidade bidirecional na relação entre inadimplência e spread bancário. Isso dito, como o policymaker deve atacar o problema? Faz sentido reduzir o spread bancário na marra para que a inadimplência caia? Por exemplo, vamos usar os bancos públicos para forçar uma redução do spread? Ou faz mais sentido atacar o risco de crédito, seja com a redução da assimetria de informação entre credor e o tomador de empréstimo, seja por meio de maior celeridade na recuperação de crédito? De um lado, estão economistas que olham o problema com base em teoria e evidência do que é feito ao redor do mundo. Do outro, estão pessoas que não têm a menor ideia do que estão falando.
Atacar o risco de crédito por meio de maior celeridade na recuperação de crédito e/ou na construção de um banco de dados público com informações sobre os tomadores tem efeitos permanentes sobre o mercado, fazendo com que tanto a inadimplência quanto o spread bancário caiam.
Uma outra forma de atacar o problema é simplesmente controlar preços, como fez recentemente o governo Dilma, com as taxas de juros da Caixa Econômica e do Banco do Brasil. Como não ataca o verdadeiro problema, que é o risco de crédito, ele terá apenas efeitos passageiros sobre o spread bancário.
Esse, de fato, é apenas um exemplo de como o debate econômico no Brasil antagoniza ideias prosaicas, de quem não tem a menor ideia do que está falando, com ideias baseadas em teoria e evidência empírica de quem realmente se deu ao trabalho de estudar o problema. Às vezes, cansa... 🙁
___________________________________
Saiba como fazer análises como essa em nossos Cursos Aplicados de R.
[/et_pb_text][/et_pb_column][/et_pb_row][/et_pb_section]

