Em dezembro do ano passado, publiquei artigo onde me perguntava para onde ia o dólar. Pergunta das mais difíceis em economia, haja visto que o câmbio se parece muito com um passeio aleatório, onde a observação de hoje é igual a de ontem mais algum ruído. Mais fácil, desse modo, é prever a tendência do câmbio do que seu valor em determinado ponto do tempo. Aquela altura, com o conjunto de informações disponível, o mercado e eu projetamos um câmbio no fim desse ano próximo a 2,80 R$/US$, o que indicava uma tendência de desvalorização. Dado tudo o que ocorreu até aqui, o câmbio encontra-se acima de 4 R$/US$ e a tendência de desvalorização não parece ainda ter cedido. Por que, questiono, erramos tanto?
No artigo em questão, ressaltei que prever câmbio era algo extremamente complicado [para não dizer, insano], dado que o conjunto de choques a que a variável está sujeita parece ser excessivamente grande. Naquela época, chamei atenção para alguns fatores, que listo abaixo:
Não se sabe, por exemplo, por quanto tempo ainda o preço das commodities – e do petróleo, em particular – continuará caindo, com graves repercussões sobre os países emergentes. Os juros norte-americanos irão subir, mas não se tem indicação de quando isso de fato irá ocorrer. Além disso, no campo doméstico, como será feito o ajuste fiscal? Quais impostos serão elevados? Cide e CPMF voltam? E diante do quadro político desafiador, azeitado pela Operação Lava-Jato, será factível aprovar esse pacote fiscal no Congresso?
A pergunta que encerra o parágrafo, inconvenientemente difícil de ser posta nos modelos, parece ter tido um sonoro não como resposta, o que agravou nossa situação fiscal, tendo consequências diretas sobre a trajetória da taxa de câmbio. Nesse aspecto, como podemos melhorar nossas previsões sobre essa variável? Ou, melhor, será que isso é possível?
Aproveitei que abri um script hoje com o pacote gtrend e pesquisei a palavra-chave "dólar". O gráfico é posto abaixo.
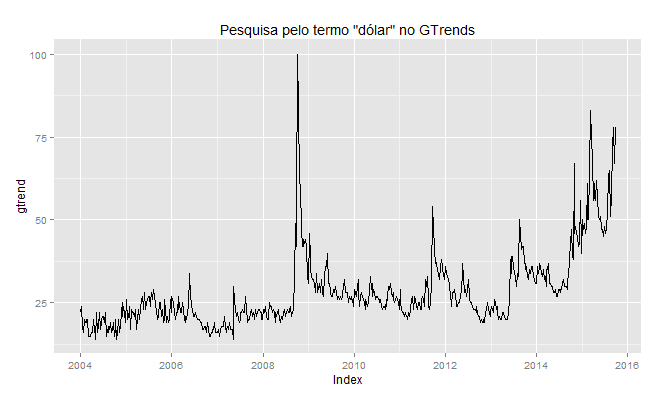
O gtrends parece captar essa desvalorização recente. O passo seguinte é comparar a pesquisa no gtrends com a taxa de câmbio. Esta, eu obtive do Banco Central com a função getSeries, elaborada pelo Alexandre Rademaker. Feito isto, precisamos mensalizar o dado do gtrends para que seja possível comparar com a taxa de câmbio, além é claro, de adequar a amostra das duas séries - os dados do gtrends só estão disponíveis a partir de janeiro de 2004. A correlação entre as duas séries pode, então, ser vista no gráfico abaixo.
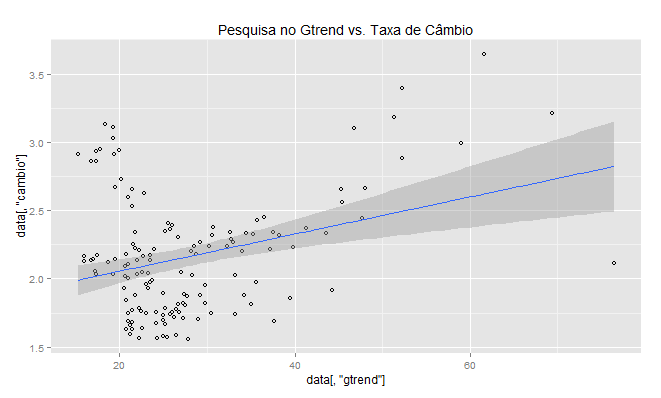
Qual a relação entre as séries? Um teste de causalidade de granger foi feito, não antes de verificar raiz unitária. O câmbio não passou no teste, enquanto o gtrends passou. Feito isto, verificou-se que tanto o câmbio exerce influência sobre o gtrends quanto este exerce influência naquele, dado todos os critérios de informação. Eu vou, entretanto, poupar o leitor desses passos, até por que isso já foi feito nesse espaço. Vamos passar para um BVAR, onde queremos ver as funções de impulso-resposta entre o gtrends e o câmbio. Com o teste de granger, estávamos apenas interessados em ver se estávamos autorizados a estimar um VAR. Com o BVAR, estamos querendo usar as séries em nível, informando, claro, a presença de raiz unitária. Antes, os correlogramas do câmbio e do gtrends são postos abaixo. Ah, sim, foi utilizado o pacote BMR.
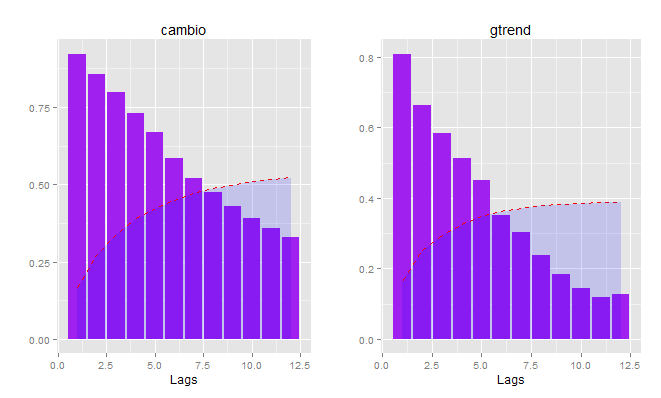
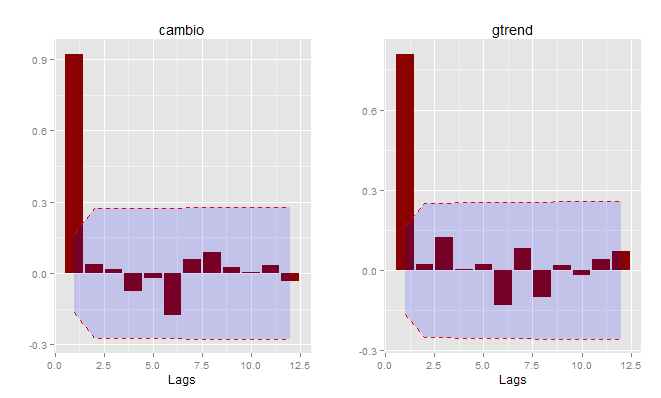
Com base nessas informações, estimei um BVAR com p=1. A função do BMR utilizada foi a BVARW, que você pode aprender mais, além de todo o pacote BMR, aqui. Estimado o modelo, chegamos, enfim, às funções impulso-resposta, postas abaixo.
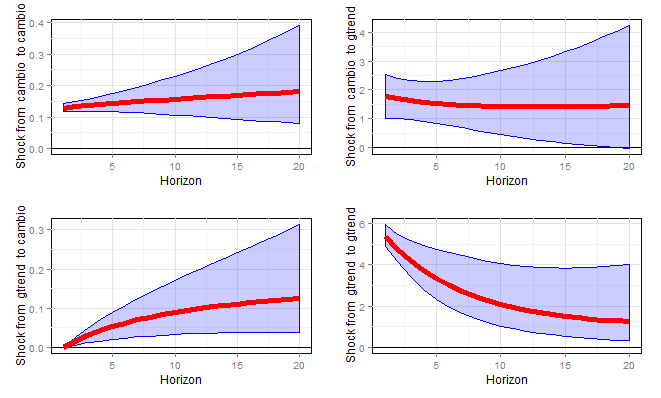
As funções impulso-resposta parecem mostrar que um choque nas pesquisas do google trends possui efeito sobre o câmbio. Dado o gráfico in natura do gtrends, que mostra um aumento das pesquisas no período recente, será que se o utilizarmos para prever o câmbio isso poderá melhorar a previsão? No momento atual, não custa tentar, não é mesmo? Quem sabe, outro dia... Enquanto isso, fique à vontade, leitor... 🙂
_______________________________________
Gostou do post? Quer aprender a fazer o mesmo? Dê uma olhada no nosso curso de Introdução ao R com aplicações em Análise de Conjuntura. Faça no Rio de Janeiro ou leve para sua empresa ou universidade!

________________________________________

