Introdução
Nos últimos anos, a ascensão de aplicações baseadas em modelos de linguagem (LLMs) impulsionou a necessidade de armazenar e consultar informações de forma mais eficiente e semântica. Nesse contexto, surge um novo tipo de banco de dados: o Vector Database. Este artigo explora o conceito de Vector Database e mostra como criar um fluxo simples com LangChain para armazenar e consultar vetores com inteligência artificial.
Para obter o código e o tutorial deste exercício faça parte do Clube AM e receba toda semana os códigos em R/Python, vídeos, tutoriais e suporte completo para dúvidas.
Qual a importância do Vector Database?
Modelos de linguagem como o GPT funcionam melhor quando têm acesso a dados externos e atualizados. No entanto, esses dados não podem ser simplesmente armazenados como texto em um banco relacional tradicional, pois precisamos consultar conteúdo semanticamente relevante, e não apenas palavras-chave.
Imagine que você quer buscar informações sobre a política monetária brasileira. Um banco tradicional pode buscar por "meta de inflação", mas não entende que "controle de preços via taxa Selic" é semanticamente próximo. É aqui que entram os vetores de embeddings — representações numéricas de textos que capturam seu significado.
O que é um Vector Database?
Um Vector Database é um banco otimizado para armazenar vetores de alta dimensão (como embeddings de texto, imagens, código etc.) e realizar buscas por similaridade semântica.
Principais características:
- Indexação vetorial com algoritmos como HNSW ou FAISS.
- Busca por similaridade com métricas como cosseno ou L2.
- Integração com LLMs para RAG (Retrieval-Augmented Generation).
Exemplos populares incluem: ChromaDB, Weaviate, Pinecone, Qdrant e FAISS.
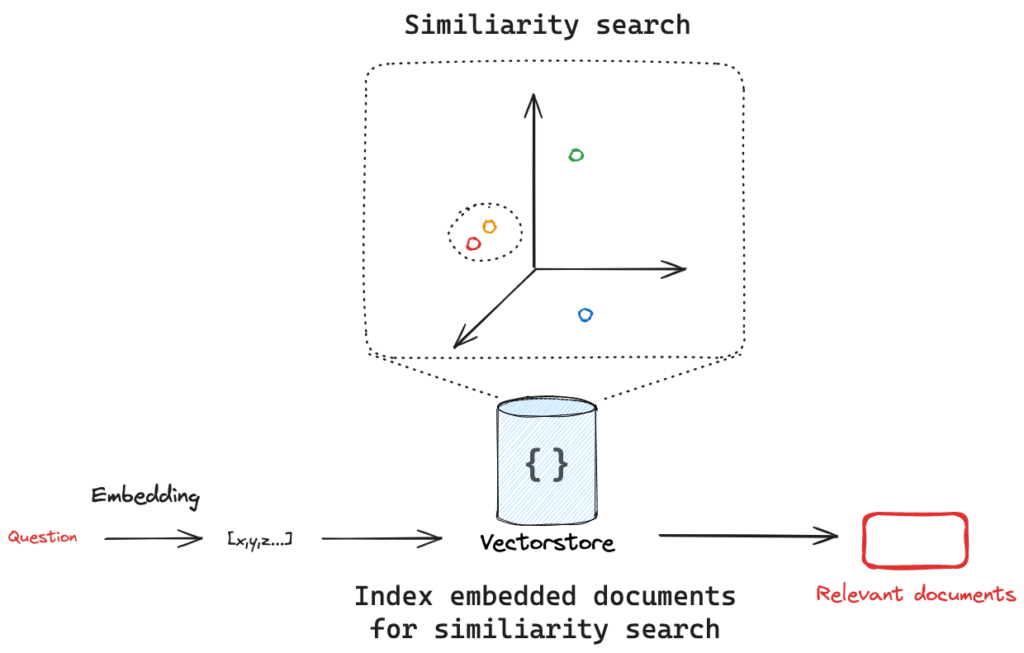
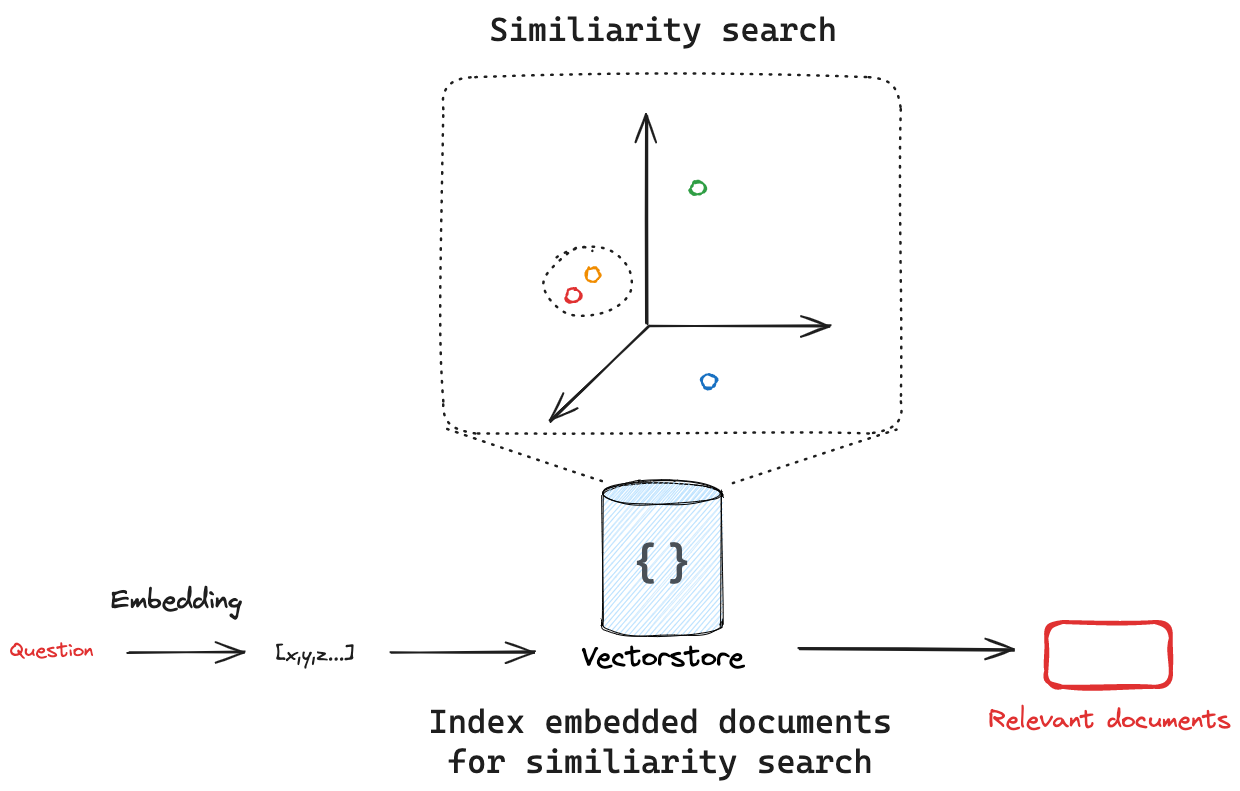
Fluxo: embedding, VectoDatabase e similarity search
A seguir, explicamos todos os passos necessários para o fluxo de leitura de uma VectoDataBase.
-
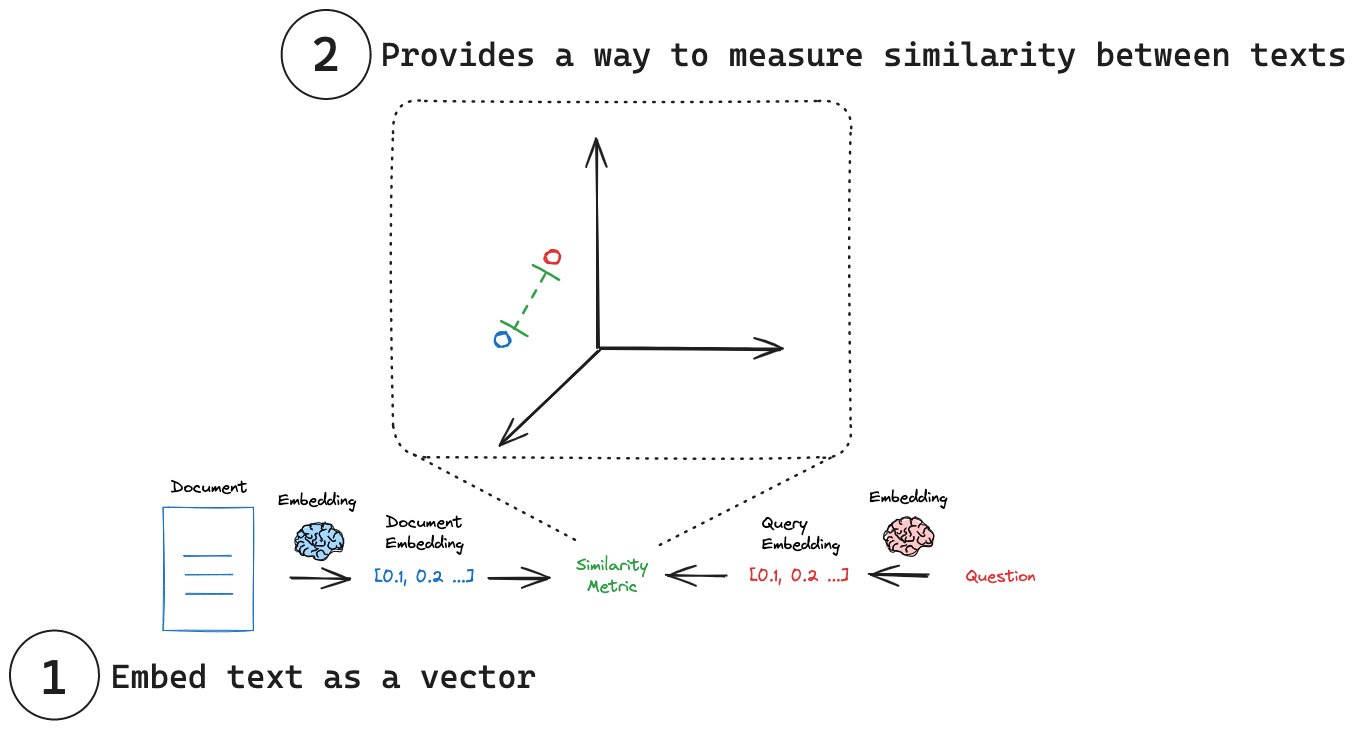
- Embedding Tudo começa com a conversão de textos em vetores numéricos. Essa transformação é feita por um modelo de embedding, que mapeia palavras, frases ou documentos inteiros para um espaço vetorial de alta dimensão. A ideia é que textos com significados semelhantes ocupem posições próximas nesse espaço, mesmo que usem palavras diferentes. Por exemplo, as frases "a inflação está subindo" e "os preços estão aumentando" gerarão vetores parecidos, pois expressam ideias semelhantes. Essa representação é fundamental para permitir que os sistemas de IA façam buscas por significado, e não apenas por palavras exatas.
- Vector Database:
Uma vez que os textos (como parágrafos de um relatório ou artigos de pesquisa) foram transformados em vetores, esses vetores são armazenados em um Vector Database. Ao contrário dos bancos de dados tradicionais, que lidam com números e strings organizados em tabelas, o Vector Database é otimizado para armazenar e consultar vetores. Ele utiliza algoritmos especializados, como HNSW ou FAISS, para permitir buscas rápidas e eficientes com base em similaridade semântica. Isso significa que, quando o sistema quiser encontrar textos relacionados a uma pergunta, ele poderá recuperar os trechos mais “parecidos em significado” com ela, mesmo que usem termos completamente diferentes.
- Similarity Search:
Quando o usuário envia uma pergunta — por exemplo, “quais são os riscos para a inflação nos próximos meses?” — essa pergunta também é convertida em um vetor usando o mesmo modelo de embedding. Em seguida, esse vetor é comparado com todos os vetores armazenados no banco de vetores. O sistema retorna os trechos que estão mais próximos da pergunta no espaço vetorial, ou seja, aqueles cujo conteúdo é mais relevante para responder a ela. Essa etapa é chamada de similarity search ou busca por similaridade. Os textos recuperados funcionam como um “contexto de apoio” para o LLM, que poderá gerar uma resposta mais precisa, baseada em conteúdo real e atualizado, como um relatório do Banco Central.
Exemplo simples: Criando e consultando um Vector Database com LangChain
Esse é o núcleo de uma aplicação RAG (Retrieval-Augmented Generation), onde o LLM não responde só com o que foi treinado, mas com base em informações externas armazenadas de forma vetorial.
Como exemplo, usamos o documento Relatório de Política Monetária de Junho de 2025. Assim, adicionamos contexto para o modelo de linguagem responder perguntas sobre a inflação e decisões da autoridade monetária nos próximos trimestres.
Assim, com o fluxo RAG, realizamos a seguinte pergunta:
Considerações
Vector Databases são fundamentais para aplicações modernas com LLMs, pois permitem armazenar e recuperar conhecimento de forma semântica. Usando ferramentas como Chroma e Langchain, é possível criar sistemas inteligentes que combinam memória vetorial com raciocínio automático.
Para economistas, contadores e analistas financeiros, isso abre portas para:
- Criar sistemas de resposta automática com base em legislações, balanços ou documentos internos;
- Fazer buscas inteligentes em relatórios de inflação, atas do Copom ou artigos técnicos;
- Integrar bancos de dados econômicos ao fluxo de análise de forma mais intuitiva.
Quer aprender mais?
Conheça nossa Formação do Zero à Análise de Dados Econômicos e Financeiros usando Python e Inteligência Artificial. Aprenda do ZERO a coletar, tratar, construir modelos e apresentar dados econômicos e financeiros com o uso de Python e IA.

