Objetivo
Este exercício tem como objetivo apresentar a biblioteca pytimetk para a manipulação de dados em séries temporais no Python. Utilizaremos como exemplo os núcleos de inflação, demonstrando como carregar, estruturar, manipular e visualizar esses dados.
Para obter o código e o tutorial deste exercício faça parte do Clube AM e receba toda semana os códigos em R/Python, vídeos, tutoriais e suporte completo para dúvidas.
Passos
- Introdução Neste primeiro tópico, vamos apresentar o conceito de séries temporais, além de discutir o formato tidy data. Usaremos os núcleos de inflação como exemplo para ilustrar esses conceitos.
- Básico e Visualização de Dados Aqui, mostramos como os dados de séries temporais são estruturados em um DataFrame. Vamos também explorar como a biblioteca
pytimetkpode ser utilizada para facilitar a visualização e compreensão desses dados ao longo do tempo. - Data Wrangling Nesta seção, abordamos as técnicas de manipulação de dados, demonstrando como realizar operações com múltiplas séries temporais. Exemplos incluem o cálculo de agregações trimestrais, como média, mediana e desvio padrão, a partir de uma série temporal mensal dos núcleos de inflação.Também exploramos como utilizar o
pytimetkpara gerar lags (atrasos) e leads (avanços) de forma agrupada para todas as séries, facilitando a análise de variações passadas e futuras.Além disso, apresentamos como decompor uma série temporal para entender suas componentes (tendência, sazonalidade e resíduo) e como calcular janelas deslizantes, como a média móvel trimestral SAAR (Seasonally Adjusted Annual Rate), para obter uma visão mais clara da tendência de curto prazo.
1. Introdução
O que é uma série temporal?
Uma série temporal é uma sequência de observações coletadas ao longo do tempo, geralmente em intervalos regulares (diários, mensais, anuais, etc.). Exemplos incluem índices de preços, taxas de câmbio e temperatura diária.
Dados “tidy”
O conceito de “tidy data” refere-se à organização dos dados de forma estruturada, onde:
- Cada linha representa uma observação.
- Cada coluna representa uma variável.
- Cada célula contém um valor único.
Como isso facilita a construção?
Manter os dados organizados é essencial para facilitar a análise e a aplicação de funções de manipulação, agregação e visualização. Quando os dados estão bem estruturados, operações como agrupamento e cálculo de estatísticas se tornam mais intuitivas e eficientes.
Para ilustrar, utilizaremos a biblioteca python-bcb para carregar dados do núcleo de inflação, medidos pelo Banco Central do Brasil. Esses dados seguem uma estrutura de série temporal, pois cada observação é registrada em intervalos mensais e ordenada no tempo.
Inicialmente, os dados (tabela abaixo) são apresentados no formato wide, onde cada variável ocupa uma coluna separada. No entanto, para trabalhar com pytimetk, o formato long será mais adequado. Veremos na prática como essa transformação facilita a manipulação e a análise das séries temporais.
| Date | EX0 | EX3 | MS | DP | P55 | nucleo | |
|---|---|---|---|---|---|---|---|
| 0 | 2000-01-01 | 0.56 | 0.33 | 0.48 | 0.47 | 0.34 | 0.436 |
| 1 | 2000-02-01 | 0.45 | 0.21 | 0.44 | 0.32 | 0.13 | 0.310 |
| 2 | 2000-03-01 | 0.05 | -0.03 | 0.37 | 0.21 | 0.10 | 0.140 |
| 3 | 2000-04-01 | 0.87 | 0.22 | 0.45 | 0.60 | 0.18 | 0.464 |
| 4 | 2000-05-01 | 0.20 | 0.16 | 0.35 | 0.18 | 0.01 | 0.180 |
2. Básico e Visualização de dados
Cada DataFrame de série temporal deve ter as seguintes propriedades:
- Índice de Série Temporal: Uma coluna contendo carimbos de data/hora no formato ‘datetime64’.
- Colunas de Valor: Uma ou mais colunas contendo dados numéricos que podem ser agregados e visualizados ao longo do tempo.
- Colunas de Grupo (Opcional): Uma ou mais colunas categóricas ou de texto que podem ser agrupadas, e a série temporal pode ser avaliada por grupos.
Vamos transformar os dados em formato “long” e avaliar o formato com o método .glimpse
<class 'pandas.core.frame.DataFrame'>: 1812 rows of 3 columns
Date: datetime64[ns] [Timestamp('2000-01-01 00:00:00'), Timestamp(' ...
id: object ['EX0', 'EX0', 'EX0', 'EX0', 'EX0', 'EX0', 'EX ...
value: float64 [0.56, 0.45, 0.05, 0.87, 0.2, 0.3, 0.26, 0.34, ...Data Wrangling
Análise de séries temporais agrupadas
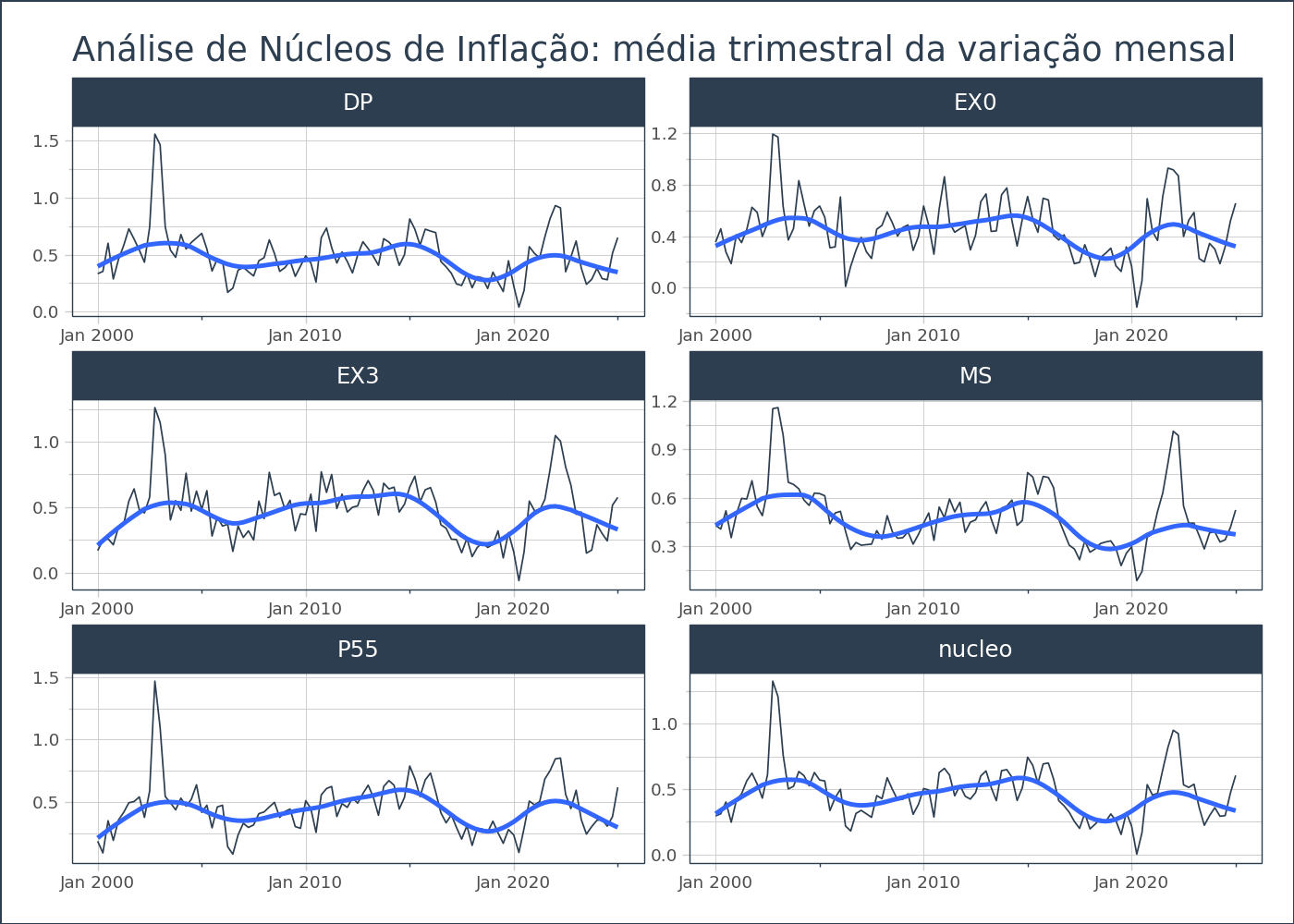
Para facilitar a construção de uma análise de dados de séries temporais (principalmente quando temos muitas séries temporais em um mesmo dataframe), usamos o agrupamento para aplicar a manipulação ou cálculo. Com base no método .summarize_by_time() criamos uma análise agrupando por cada variável (núcleo) e pelo tempo.
| id | Date | value_mean | value_median | value_min | value_q25 | value_q75 | value_max | value_range | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | DP | 2000-01-01 | 0.333333 | 0.32 | 0.21 | 0.265 | 0.395 | 0.47 | 0.26 |
| 1 | DP | 2000-04-01 | 0.353333 | 0.28 | 0.18 | 0.230 | 0.440 | 0.60 | 0.42 |
| 2 | DP | 2000-07-01 | 0.600000 | 0.72 | 0.24 | 0.480 | 0.780 | 0.84 | 0.60 |
| 3 | DP | 2000-10-01 | 0.286667 | 0.24 | 0.18 | 0.210 | 0.340 | 0.44 | 0.26 |
| 4 | DP | 2001-01-01 | 0.460000 | 0.47 | 0.36 | 0.415 | 0.510 | 0.55 | 0.19 |
Usando o método .plot_timeseries()criamos facilmente a visualização de dados para cada série temporal. O resultado abaixo referencia o valor da coluna "value_mean".
Aumentar Lags / Leads
Os Lags (atrasos) são comumente usados em previsões de séries temporais para incorporar os valores passados de uma variável como preditores. Os Leads (avanços), embora não tão comuns quanto os Lags em séries temporais, podem ser úteis em cenários onde você deseja prever um valor futuro com base em outros valores futuros.
Há várias formas de criar lags/leads, pode-se criar um única lag ou lead para toda os valores da coluna, mas no nosso caso, temos valores agrupados, ou seja, adicionamos groupby para criar lags/leads para todas as variáveis (e podemos criar mais de 1 atraso ou avanços de uma única vez).
Código
| Date | id | value | value_lag_1 | value_lag_2 | value_lag_3 | value_lead_1 | value_lead_2 | value_lead_3 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 2000-01-01 | EX0 | 0.56 | NaN | NaN | NaN | 0.48 | 0.47 | 0.34 |
| 1 | 2000-02-01 | EX0 | 0.45 | 0.56 | NaN | NaN | 0.44 | 0.21 | 0.32 |
| 2 | 2000-03-01 | EX0 | 0.05 | 0.45 | 0.56 | NaN | 0.87 | 0.18 | 0.45 |
| 3 | 2000-04-01 | EX0 | 0.87 | 0.05 | 0.45 | 0.56 | 0.18 | 0.45 | 0.22 |
| 4 | 2000-05-01 | EX0 | 0.20 | 0.87 | 0.05 | 0.45 | 0.18 | 0.16 | 0.18 |
Decomposição
A biblioteca pytimetk facilita a detecção de anomalias em séries temporais, ou seja, a identificação de valores atípicos (outliers), que são comuns em situações de uma instabilidade subjacente da série temporal ou devido a erros na inserção de dados.
Detectar anomalias é especialmente útil em diversas situações, como:
- Identificação de padrões anormais: que podem indicar problemas nos dados.
- Análise de ciclos e tendências inesperadas: para entender se a série temporária está seguindo o padrão esperado ou se há eventos fora do comum.
Uma forma de detectar anomalias é através da decomposição da série temporal. No nosso caso, ao decompor uma série temporal, podemos identificar a sazonalidade e, ao fazê-lo, podemos separar a componente sazonal da série. A decomposição ajuda a entender melhor os seguintes componentes:
- Tendência: a direção de longo prazo dos dados.
- Sazonalidade: padrões que se repetem em intervalos regulares (como variações de preço que ocorrem todo mês ou trimestre).
- Resto (ou erro): os componentes imprevisíveis ou aleatórios após remover tendência e sazonalidade.
Obter os valores da componente sazonal é importante porque nos permite remover os efeitos sazonais da inflação, facilitando uma análise direta. Por exemplo, ao comparar o valor da inflação de junho com o de janeiro, a remoção da sazonalidade nos permite fazer uma comparação mais justa, sem o viés de variações sazonais, evitando conclusões errôneas.
Vamos ver agora como podemos decompor a série de núcleos para análise:
Código
<class 'pandas.core.frame.DataFrame'>: 302 rows of 12 columns
Date: datetime64[ns] [Timestamp('2000-01-01 00:00:00'), ...
observed: float64 [0.43600000000000005, 0.3100000000 ...
seasonal: float64 [0.04124796495639957, 0.0398861003 ...
seasadj: float64 [0.39475203504360046, 0.2701138996 ...
trend: float64 [0.30151674808436446, 0.3105837774 ...
remainder: float64 [0.093235286959236, -0.04046987775 ...
anomaly: object ['No', 'No', 'No', 'No', 'No', 'No ...
anomaly_score: float64 [0.010826410463910974, 0.122878754 ...
anomaly_direction: int64 [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ...
recomposed_l1: float64 [-0.0756379185193996, -0.067932753 ...
recomposed_l2: float64 [0.9259850975915778, 0.93369026230 ...
observed_clean: float64 [0.43600000000000005, 0.3100000000 ...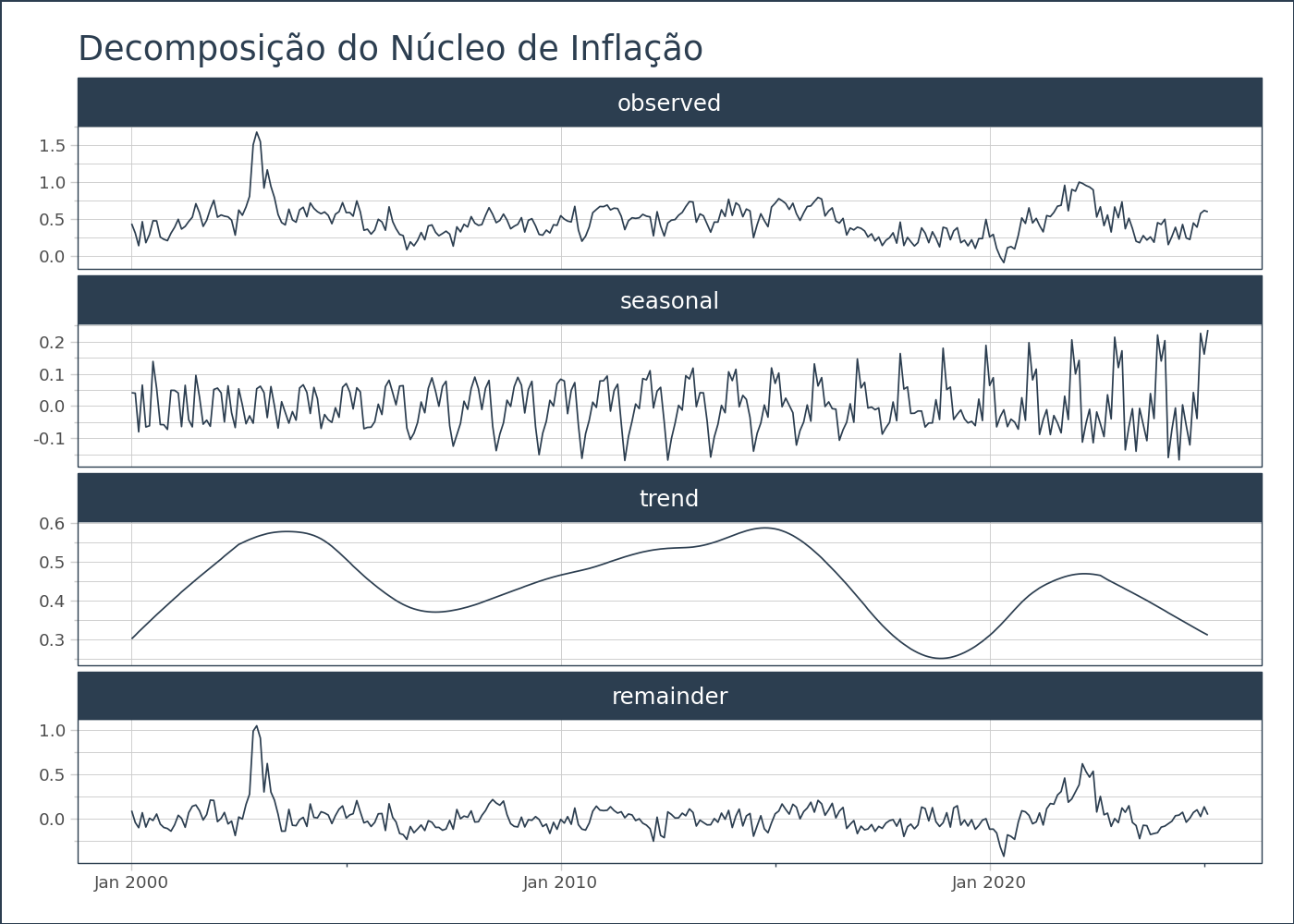
Janelas Deslizantes
A utilização de janelas deslizantes permite calcular agregações em intervalos de tempo fixos, o que ajuda a identificar e capturar tendências em uma série temporal.
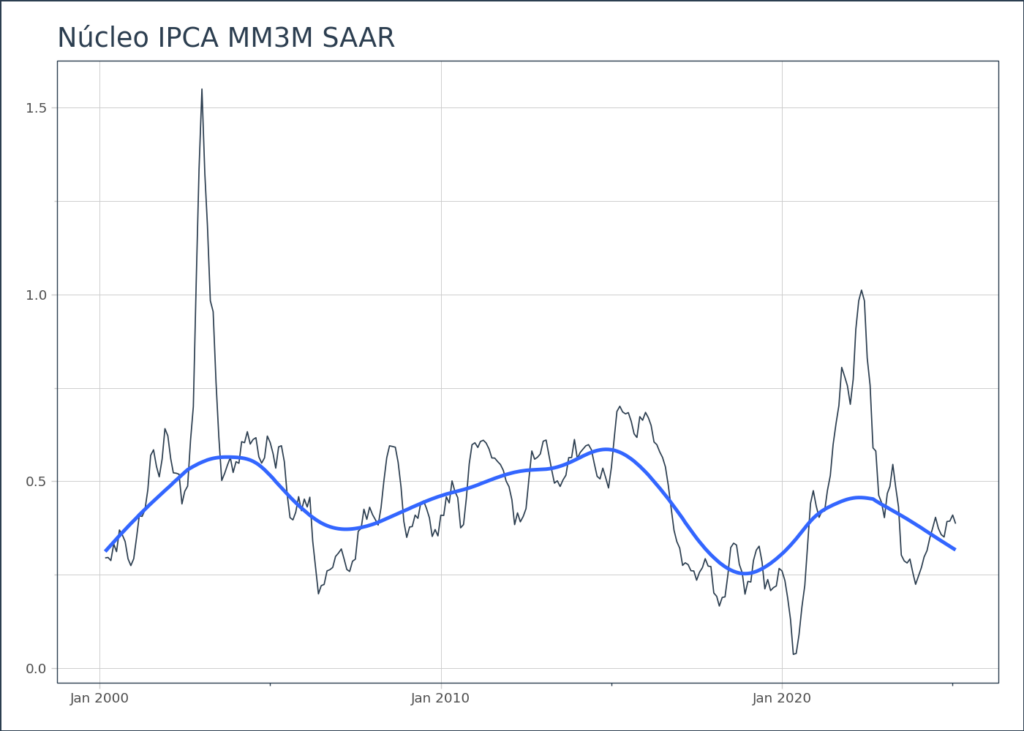
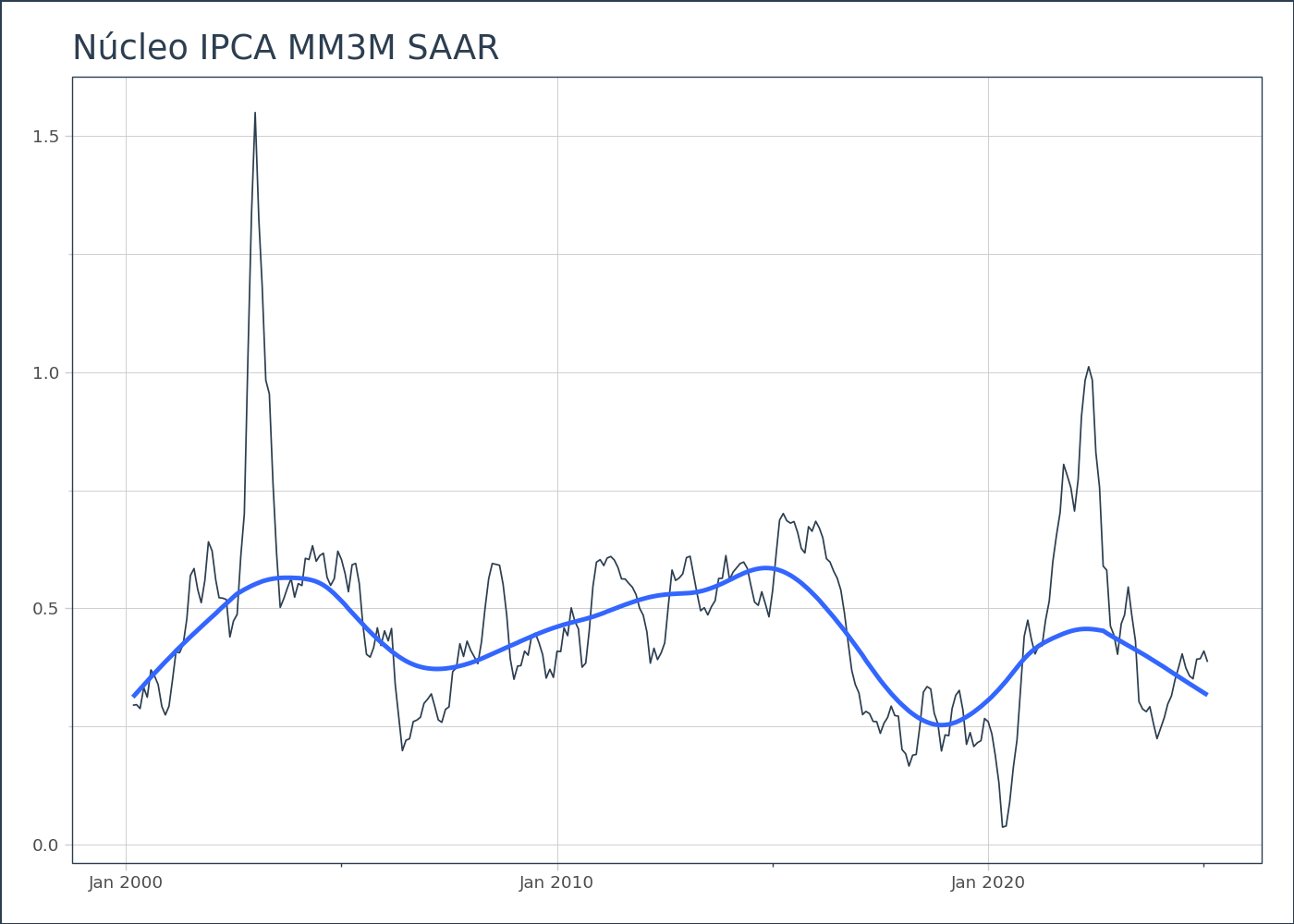
No caso da inflação, uma análise comum é calcular a média móvel de 3 meses, ajustada sazonalmente e anualizada. Esse é um indicador amplamente utilizado por analistas e pelo próprio Banco Central para entender os movimentos de curto prazo na tendência da inflação.
A partir dos dados ajustados sazonalmente, podemos utilizar o método .augment_rolling para calcular a média móvel de 3 meses do núcleo da inflação. Esse processo ajuda a suavizar as flutuações mensais e revela de forma mais clara a evolução da inflação em um período mais longo, ajustada para os efeitos sazonais.
Quer aprender mais?
Conheça nossa Formação do Zero à Análise de Dados Econômicos e Financeiros usando Python e Inteligência Artificial. Aprenda do ZERO a coletar, tratar, construir modelos e apresentar dados econômicos e financeiros com o uso de Python e IA.

