Backtesting é um método usado para averiguar o quão bem uma estratégia de trading ou a construção de um portfólio performou com base nos dados históricos. Vamos mostrar uma ferramenta útil para a criação de métricas do Backtesting no Python.
Idealmente, os dados históricos devem vir de um período no qual as condições econômicas são iguais ao período de futuro de constituição do portfólio, portanto, deve-se atentar e comparar a volatilidade do mercado.
Além disso, deve-se atentar-se aos custos transacionais do período, de forma que tenha-se uma visão verdadeira.
Mas como realizar o Backtesting e quais métricas são usadas para avaliar os retornos?
Existem diversos indicadores que levam em conta não somente o retorno e o risco dos dados passados da estratégia/portfólio, mas também indicadores que avaliam o retorno ajustado ao risco. Entre alguns desses, podemos elencar:
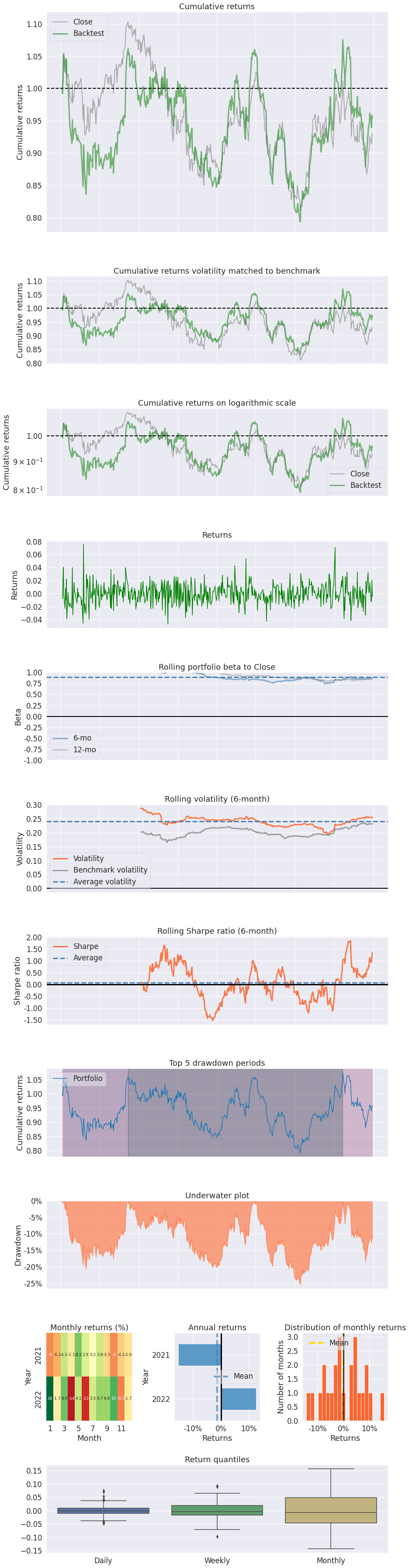
- Retorno Acumulado: visa avaliar o retorno total ao longo do tempo
- Retorno anualizado: permite comparar diferentes investimentos
- Volatilidade anual: permite comparar o risco de diferentes investimentos
- Drawndown: exibe os períodos de queda dos retornos ao longo do tempo (útil para avaliar eventos que aumentam a volatilidade, bem como o efeito de sinais de entrada/saída das estratégias)
- Sharpe ratio/Omega ratio/Sortino ratio: Indicadores de risco-retorno, que usualmente avaliam o ganho de retorno para cada aumento unitário do risco, e que são comparados com algum Benchmark.
- Beta: medida de risco sistemático
- Alpha: retorno acima do mercado
- Visualização: uso de gráficos das medidas acima para avaliar o desempenho, tais como o histograma, boxplot e gráfico de linha.
Existem muitas outras medidas e indicadores que podem ser utilizados para avaliar o desempenho de um investimento, mas o mais utilizados estão elencados acima.
In-sample e Out-of-sample
- In-sample: refere-se aos dados usados para treinar a estratégia, separando-a de uma pequena porção dos dados da amostra total;
- Out-of-sample: refere-se aos dados que são usados para testar a estratégia. Esses dados não foram usados no treino, portanto, são úteis para comparar se houve ou não viés, bem como se a estratégia performou bem.
# Instala o pyfolio direto do github !pip install git+https://github.com/quantopian/pyfolio
!pip install yfinance import yfinance as yf import pyfolio as pf from matplotlib import pyplot as plt
# Conecta as informações da ITSA4 symbol = 'ITSA4.SA' itsa_yahoo_info = yf.Ticker(symbol) itsa_history = itsa_yahoo_info.history(start = '2021-01-01', # data início end = '2022-12-31', # data fim auto_adjust = True) # OHLCV ajustado # Calcula os retornos itsa_returns = itsa_history.Close.pct_change() # Conecta as informações da IBOV (Bechmark) ibov_yahoo_info = yf.Ticker('^BVSP') ibov_history = ibov_yahoo_info.history(start = '2021-01-01', # data início end = '2022-12-31', # data fim auto_adjust = True) # OHLCV ajustado # Calcula os retornos ibov_returns = ibov_history.Close.pct_change()
Com os retornos do ativo financeiro e do benchmark em mãos, podemos averiguar o backtesting do ativo por meio de diferentes métricas usando o pyfolio. Vemos o resultado o abaixo.
A construção de todos os procedimentos para a criação dos gráficos abaixo você pode obter fazendo parte do Clube AM, o repositório especial de códigos da Análise Macro.
______________________________________
Quer saber mais?
Veja nosso curso de Python para Investimentos.

