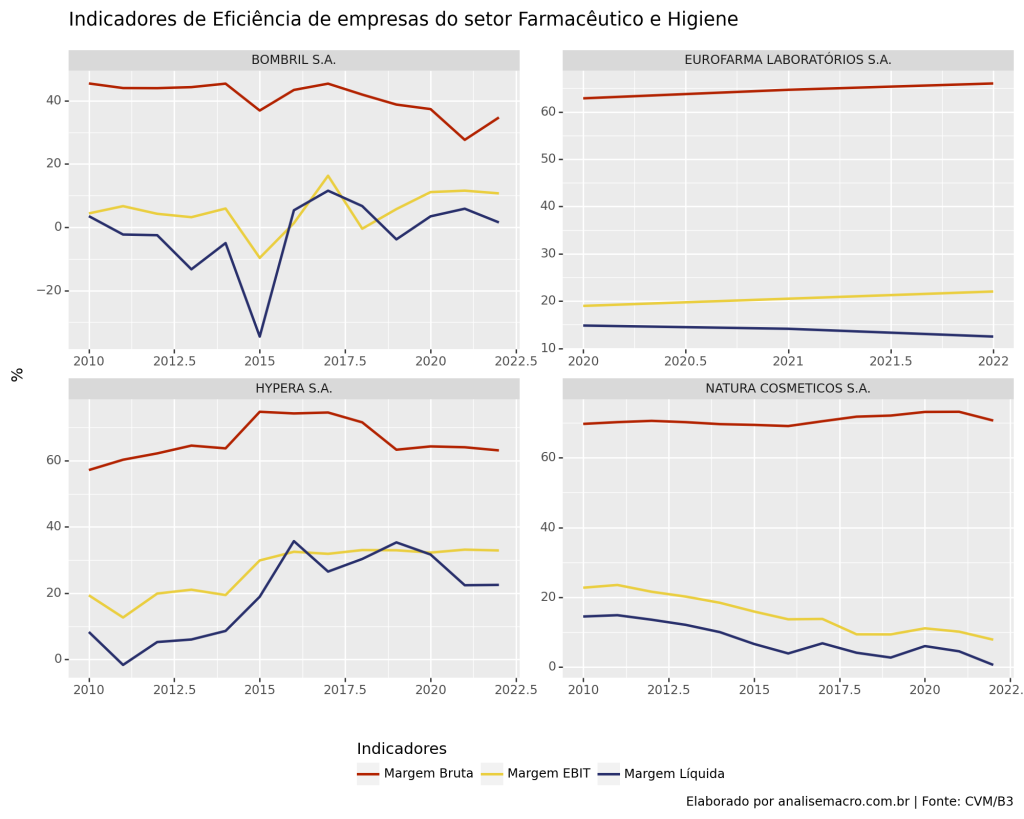
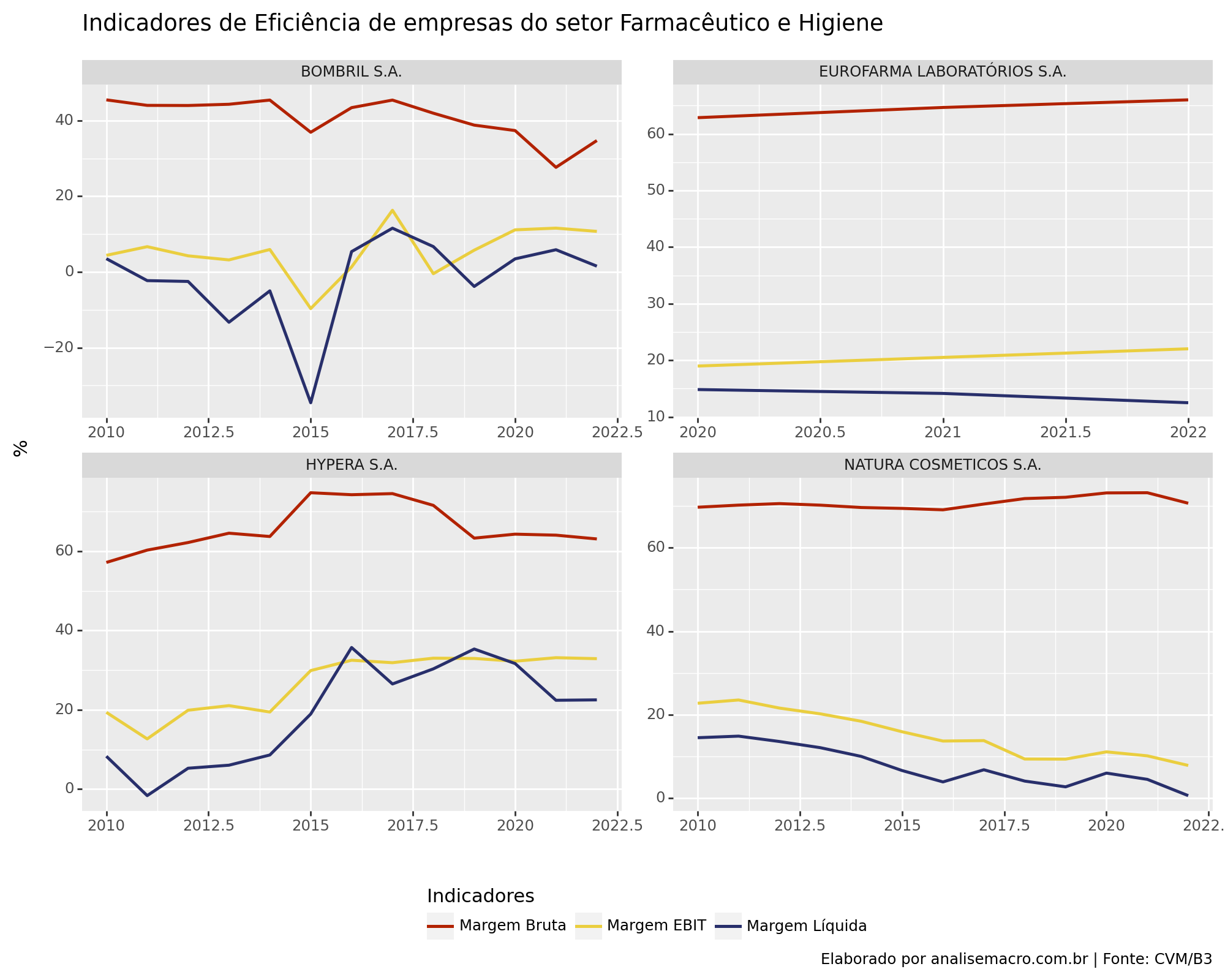
Neste artigo, abordaremos como criar indicadores de análise fundamentalista utilizando a linguagem de programação Python. Demonstraremos como coletar dados financeiros de empresas pertencentes ao setor Farmacêutico e de Higiene e, em seguida, construiremos indicadores de eficiência com base nesses dados.
Para adquirir os demonstrativos financeiros das empresas, é essencial coletar os dados diretamente do site de Dados Abertos da CVM, através do seguinte link. Os arquivos estão compactados em formato zip e devem ser descompactados para obter os arquivos .csv. Além disso, é preciso criar um loop para baixar os dados de todos os anos disponíveis. Para facilitar esse procedimento, utilizamos a seguinte função, que automatiza o processo.
1. Carrega os pacotes
# Carrega as bibliotecas import wget # biblioteca para realizar o download de sites import pandas as pd # biblioteca para manipulação de dados e data frames from zipfile import ZipFile # biblioteca para extrair arquivo zipados from plotnine import * # biblioteca para construir o gráfico
2. Cria função para coletar demonstrativos da CVM
def download_extract_concatenate_dfp_files(start_year, end_year, financial_statements):
"""
Função para realizar o download, extração e concatenação de arquivos zipados contendo os dados da Demonstração Financeira
Padronizada (DFP) de companhias abertas disponibilizados pela Comissão de Valores Mobiliários (CVM).
Parâmetros:
start_year (int): Ano inicial da coleta dos dados.
end_year (int): Ano final da coleta dos dados.
financial_statements (list): Lista de nomes dos arquivos de demonstrativos financeiros que deseja-se concatenar. Consolidado: BPA_con (balanço patrimonial ativo);
BPP_con (Balanço patrimonial passivo) DRE_con; DFC_MI_con; DFC_MD_CON; DMPL_con.
Retorna:
Arquivo .csv no diretório principal
"""
url = "https://dados.cvm.gov.br/dados/CIA_ABERTA/DOC/DFP/DADOS/"
# Cria uma lista vazia para inserir os nomes dos arquivos zipados
arquivo_zipado = []
# Define os nomes dos arquivos zipados de acordo com o range de datas
for ano in range(start_year, end_year + 1):
arquivo_zipado.append(f'dfp_cia_aberta_{ano}.zip')
# Realiza o download dos arquivos zipados de acordo com a url base
for arquivos in arquivo_zipado:
wget.download(url + arquivos)
# Extrai os arquivos zipados
for arquivos in arquivo_zipado:
ZipFile(arquivos, 'r').extractall('DFP')
# Concatena os dados dos demonstrativos financeiros em um único DataFrame
for demons in financial_statements:
arquivo_demonstrativo = pd.DataFrame()
for ano in range(start_year, end_year + 1):
arquivo_demonstrativo = pd.concat([arquivo_demonstrativo, pd.read_csv(f'DFP/dfp_cia_aberta_{demons}_{ano}.csv', sep = ';', decimal = ',', encoding = 'ISO-8859-1')])
arquivo_demonstrativo.to_csv(f'dfp_cia_aberta_{demons}_{start_year}-{end_year}.csv', index = False)
3. Coleta os dados
# Coleta os dados da DRE
download_extract_concatenate_dfp_files(2010, 2023, ['DRE_con'])
# Realiza a leitura do arquivo
dre = pd.read_csv('dfp_cia_aberta_DRE_con_2010-2023.csv')
4. Tratamento de dados
# Realiza o filtro das contas contábeis, do código CVM e da ordem do exercício dados = dre[dre.CD_CONTA.isin(["3.01", # Receita de Venda de Bens e/ou Serviços "3.03", # Resultado Bruto "3.05", # EBIT "3.11" # Lucro/Prejuízo Consolidado do Período ]) & dre.CD_CVM.isin([12190, 26700, 21431, 19550]) & (dre.ORDEM_EXERC == 'ÚLTIMO')] # Seleciona as colunas dados = dados[["DT_REFER", "DENOM_CIA", "CD_CONTA", "DS_CONTA", "VL_CONTA"]] # Converte a coluna de data para datetime dados['DT_REFER'] = pd.to_datetime(dados['DT_REFER']) # Cria a coluna Ano dados['Ano'] = dados['DT_REFER'].dt.year dados_pivot = dados.pivot(index = ['Ano', 'DENOM_CIA'], columns = 'CD_CONTA', values = 'VL_CONTA') dados_pivot.head()
Código
| CD_CONTA | 3.01 | 3.03 | 3.05 | 3.11 | |
|---|---|---|---|---|---|
| Ano | DENOM_CIA | ||||
| 2010 | BOMBRIL S.A. | 804924.0 | 365924.0 | 35356.0 | 28317.0 |
| HYPERA S.A. | 3159728.0 | 1806425.0 | 611956.0 | 261901.0 | |
| NATURA COSMETICOS S.A. | 5136712.0 | 3579906.0 | 1167906.0 | 744050.0 | |
| 2011 | BOMBRIL S.A. | 845814.0 | 372181.0 | 56528.0 | -19313.0 |
| HYPERA S.A. | 3324630.0 | 2004064.0 | 421009.0 | -54651.0 |
5. Cria os indicadores
# Cria os indicadores indicadores = ( dados_pivot .assign(margem_bruta = (dados_pivot["3.03"]) / dados_pivot["3.01"] * 100, margem_liquida = (dados_pivot["3.11"]) / dados_pivot["3.01"] * 100, margem_ebit = (dados_pivot["3.05"]) / dados_pivot["3.01"] * 100) ) # Retira o índice indicadores.reset_index(inplace = True) # Arrendonda os valores indicadores = indicadores.round(decimals = 3) # Seleciona colunas e arredonda valores indicadores = indicadores[['Ano', 'DENOM_CIA', 'margem_bruta', 'margem_liquida', 'margem_ebit']].round(decimals = 3) indicadores_long = indicadores.melt(id_vars = ['Ano', 'DENOM_CIA'], var_name = "Indicadores") indicadores_long
Código
| Ano | DENOM_CIA | Indicadores | value | |
|---|---|---|---|---|
| 0 | 2010 | BOMBRIL S.A. | margem_bruta | 45.461 |
| 1 | 2010 | HYPERA S.A. | margem_bruta | 57.170 |
| 2 | 2010 | NATURA COSMETICOS S.A. | margem_bruta | 69.693 |
| 3 | 2011 | BOMBRIL S.A. | margem_bruta | 44.003 |
| 4 | 2011 | HYPERA S.A. | margem_bruta | 60.279 |
| ... | ... | ... | ... | ... |
| 121 | 2021 | NATURA COSMETICOS S.A. | margem_ebit | 10.140 |
| 122 | 2022 | BOMBRIL S.A. | margem_ebit | 10.723 |
| 123 | 2022 | EUROFARMA LABORATÓRIOS S.A. | margem_ebit | 22.031 |
| 124 | 2022 | HYPERA S.A. | margem_ebit | 32.900 |
| 125 | 2022 | NATURA COSMETICOS S.A. | margem_ebit | 7.840 |
126 rows × 4 columns
6. Visualização de dados
# Criando o gráfico
(
ggplot(indicadores_long, aes(x = "Ano",
y = "value",
color = "Indicadores"))
+ geom_line(size = 1)
+ facet_wrap("DENOM_CIA", scales = "free")
+ scale_color_manual(values = {'margem_liquida' : '#282f6b', 'margem_bruta' : "#b22200", 'margem_ebit' : "#eace3f"},
labels = {'margem_liquida' : 'Margem Líquida', 'margem_bruta' : 'Margem Bruta', 'margem_ebit' : 'Margem EBIT'})
+ labs(title = "Indicadores de Eficiência de empresas do setor Farmacêutico e Higiene",
y = '%',
x = '',
caption = "Elaborado por analisemacro.com.br | Fonte: CVM/B3")
+ theme(figure_size=(10, 8),
subplots_adjust = {'wspace': 0.25,
'hspace': 0.25},
legend_position = 'bottom')
)
Quer aprender mais?
- Cadastre-se gratuitamente aqui no Boletim AM e receba toda terça-feira pela manhã nossa newsletter com um compilado dos nossos exercícios com exemplos reais de análise de dados envolvendo as áreas de Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas;
- Quer ter acesso aos códigos, vídeos e scripts de R/Python desse exercício? Vire membro do Clube AM aqui e tenha acesso à nossa Comunidade de Análise de Dados;
- Quer aprender a programar em R ou Python com Cursos Aplicados e diretos ao ponto em Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas? Veja nossos Cursos aqui.

