Uma cadeia de Markov calcula a probabilidade de um sistema passar de um estado para outro quando o futuro depende apenas do presente. Aplicada ao mercado financeiro, ela responde a uma pergunta direta: depois de um mês de alta, qual a chance de o próximo mês também ser de alta? Este tutorial mostra como estimar essa resposta no R, com quatorze anos de dados reais do ITUB4.
O resultado surpreende quem espera encontrar tendência. Ao estimar a matriz de transição do papel entre 2012 e 2025, todas as probabilidades ficam coladas em 50%, e o efeito do mês atual desaparece já no mês seguinte. O modelo funciona; o que ele mede é a ausência de estrutura previsível.
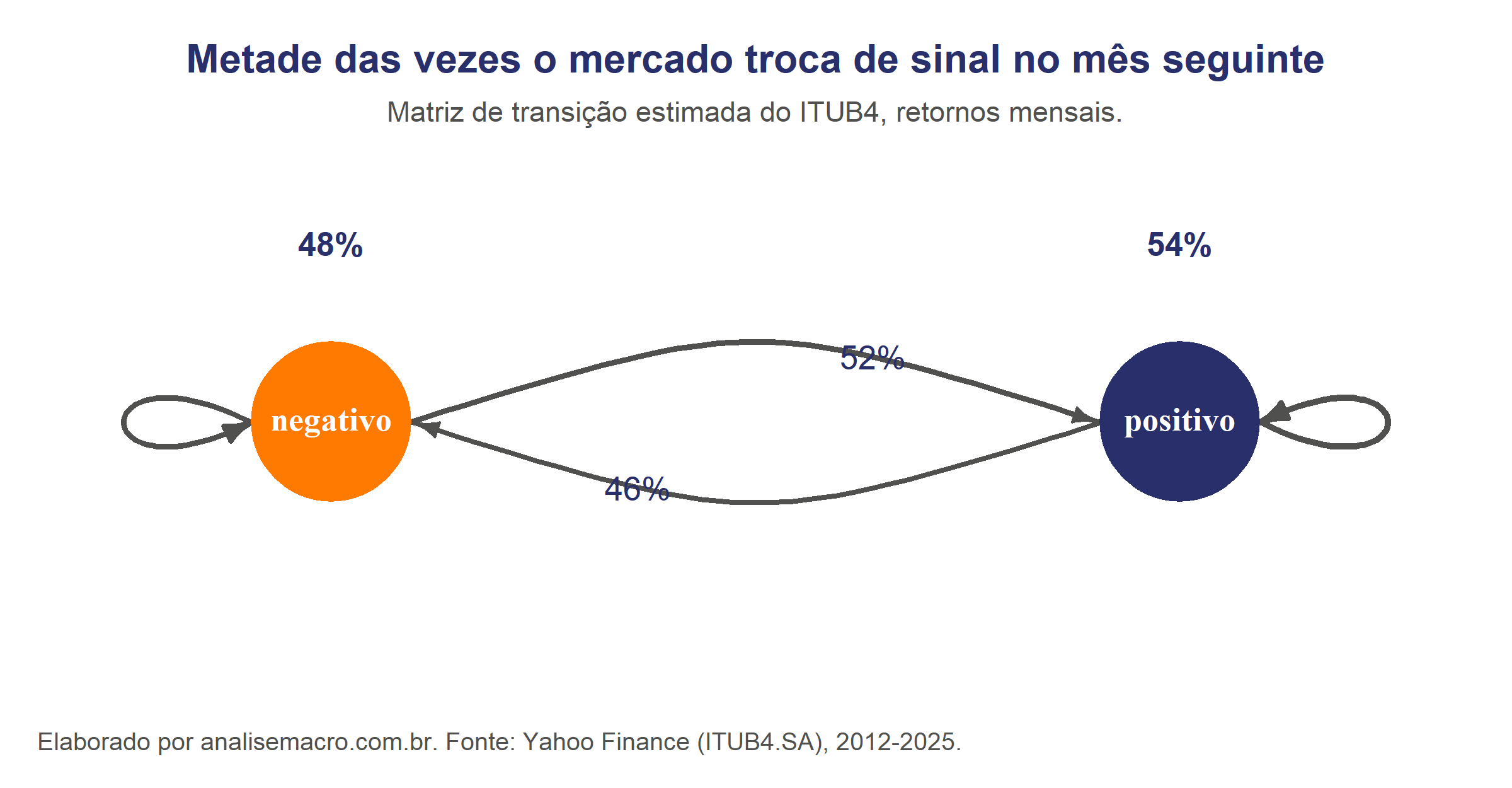
Depois de um mês positivo, a chance de outro mês positivo é de 54%. Depois de um mês negativo, ela é de 52%. A diferença de dois pontos percentuais entre as duas situações é o quanto o mês atual informa sobre o próximo — praticamente nada. O passo a passo abaixo mostra como chegar a esses números.
Quer reproduzir este exercício?
O script completo em R vai para os assinantes do Boletim AM: importação dos preços via quantmod, construção dos estados, teste da propriedade de Markov, estimação da matriz com intervalos de confiança e os gráficos prontos. Assine, é gratuito, e receba o código no e-mail.
O que é uma cadeia de Markov
Uma cadeia de Markov é um modelo para sequências de eventos em que a probabilidade do próximo evento depende só do evento atual. Todo o histórico anterior é irrelevante, porque a informação que ele carrega já está resumida em onde o processo se encontra agora.
Essa é a chamada propriedade de Markov, e é ela que dá aos processos desse tipo o apelido de "sem memória". A memória não some: ela se concentra inteiramente no presente.
O ganho prático é a economia. Modelar como todo o passado influencia o futuro exigiria um número enorme de parâmetros. A hipótese de Markov reduz a dinâmica inteira a uma tabela de probabilidades de transição, que no caso de dois estados tem apenas dois valores livres.
Estado, transição e matriz
Um estado é a situação em que o processo pode estar num dado momento. Neste exercício há dois: o mês fechou com retorno positivo ou com retorno negativo.
Uma probabilidade de transição é a chance de sair de um estado e chegar a outro no período seguinte. A probabilidade de ir de positivo para negativo, por exemplo, é a chance de um mês de alta ser seguido por um mês de queda.
A matriz de transição organiza todas essas probabilidades numa tabela quadrada, com uma linha e uma coluna por estado. Cada linha soma 1, porque partindo de qualquer estado o processo necessariamente vai para algum lugar.
Como o exercício foi construído
O caminho vai do preço bruto até a probabilidade estimada em cinco etapas. Cada uma resolve um problema específico, e todas rodam em R.
Do preço ao estado
A série de preços chega em frequência diária e precisa ser reduzida à mensal, guardando o último preço de cada mês. Sobre essa série calculamos o retorno mensal simples, que é a variação percentual de um mês para o outro.
O estado sai do sinal desse retorno: acima de zero vira "positivo", o restante vira "negativo". Definir o estado pelo retorno, e não pela comparação direta de preços, deixa explícito o que está sendo medido e o que fazer com o caso raro de retorno exatamente nulo.
Testar antes de estimar
Antes de confiar no modelo, cabe checar se a hipótese que o sustenta é plausível para esses dados. O pacote markovchain traz um teste qui-quadrado que compara as transições observadas com o que se esperaria caso o passado mais distante importasse.
No ITUB4 o p-valor ficou em 0,85, muito acima de qualquer nível de significância usual. Não rejeitamos a hipótese de que a sequência satisfaz a propriedade de Markov, o que autoriza seguir com a estimação.
Uma ressalva honesta: não rejeitar não é o mesmo que provar. Um p-valor alto significa que a amostra não trouxe evidência contra a hipótese. Com dois estados e cerca de 165 transições, o teste tem poder limitado para detectar dependências sutis.
Como a matriz é estimada
A estimação usa máxima verossimilhança, um método que escolhe os valores dos parâmetros que tornam os dados observados os mais prováveis possíveis. Para cadeias de Markov ele tem uma forma simples e intuitiva: contar.
A probabilidade de ir de positivo para positivo é o número de vezes em que um mês positivo foi seguido de outro mês positivo, dividido pelo total de meses positivos que tiveram um mês seguinte. É a definição empírica de probabilidade condicional aplicada às transições.
| Estado no mês atual | Vai para negativo | Vai para positivo | Transições observadas |
|---|---|---|---|
| Negativo | 48,1% | 51,9% | 77 |
| Positivo | 46,1% | 53,9% | 89 |
Matriz de transição estimada do ITUB4, retornos mensais de 2012 a 2025. Fonte: Yahoo Finance.
Os intervalos de confiança de 95% dessas estimativas vão de aproximadamente 32% a 69%. São largos o suficiente para incluir o valor de 50% em todas as quatro células, o que significa que os dados são compatíveis com a hipótese de que o sinal do retorno mensal se comporta como o lançamento de uma moeda honesta.
É um erro comum de interpretação. Ler a matriz como "há 54% de chance de alta depois de uma alta" ignora que a mesma amostra também é compatível com 50%, e a estimativa pontual sozinha não permite distinguir uma conclusão sustentada de uma coincidência amostral. Por isso o intervalo de confiança entra no relatório junto com a probabilidade.
Para onde a cadeia converge
Com a matriz em mãos, dá para projetar a probabilidade dos estados vários meses à frente. A conta é uma multiplicação de matrizes: elevar a matriz de transição à potência do número de meses e aplicar ao ponto de partida.
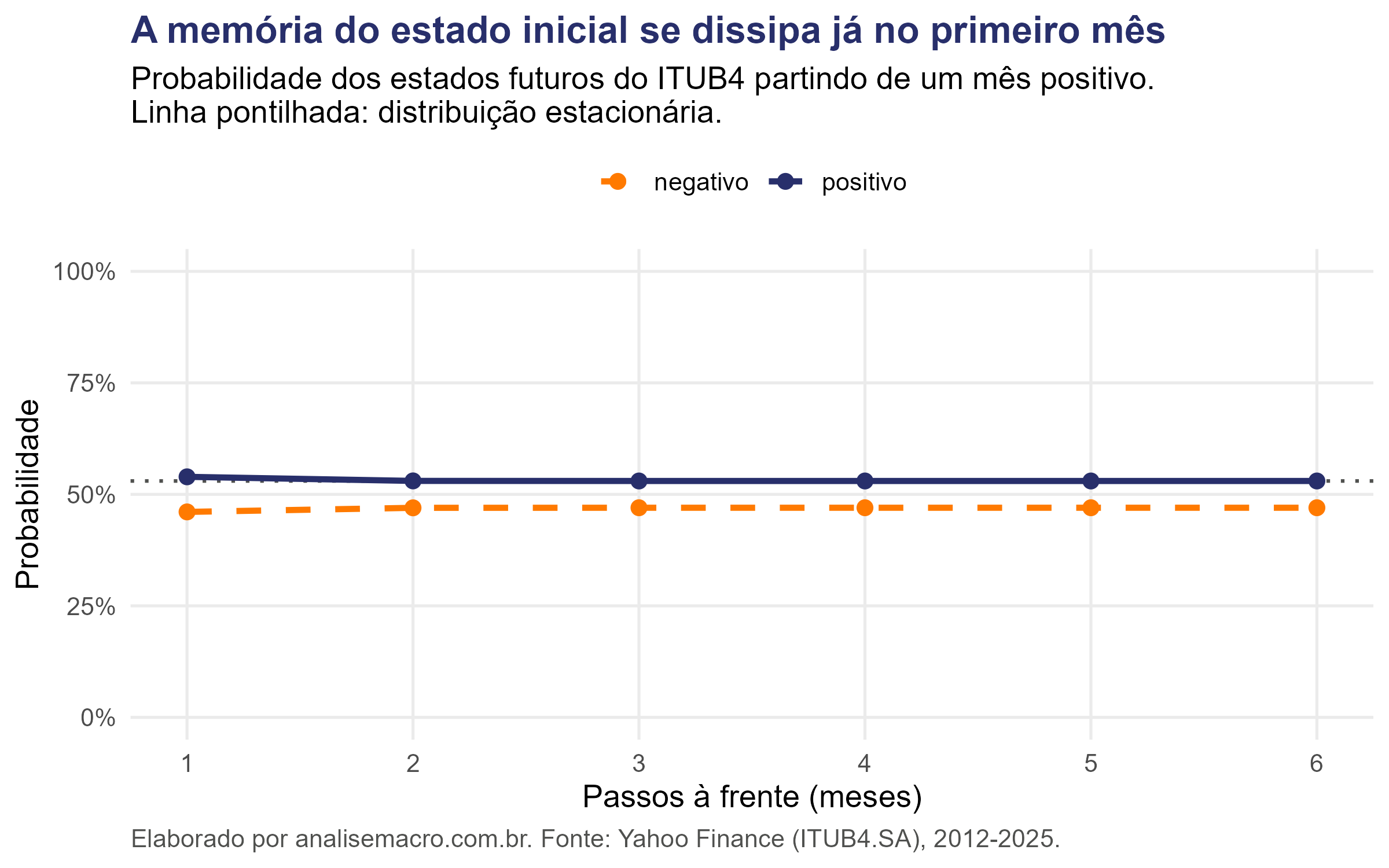
As duas curvas encostam nas linhas tracejadas quase de imediato. Partindo de um mês positivo, a probabilidade de o mês seguinte ser positivo é 53,9%; dois meses à frente ela já caiu para 53,0% e não se move mais.
Essas linhas tracejadas marcam a distribuição estacionária, o vetor de probabilidades que a matriz de transição deixa inalterado. Ele indica a fração do tempo que a cadeia passa em cada estado no longo prazo, e não depende de onde o processo começou.
No ITUB4 a distribuição estacionária é de 53% para meses positivos e 47% para negativos. O leve viés altista reflete a valorização do papel no período, e bate com a frequência observada na amostra: 89 meses positivos contra 78 negativos.
A velocidade da convergência é o que mede a memória do sistema. Como as duas linhas da matriz são quase idênticas, o estado de origem quase não altera o destino, e a informação se perde num único passo. Num processo com mais persistência, como regimes de volatilidade, as linhas seriam bem diferentes entre si e a memória duraria vários períodos.
As ferramentas por trás
O que o resultado revela
- O sinal do retorno mensal não prevê o mês seguinte. A diferença entre as duas linhas da matriz é de dois pontos percentuais, e o intervalo de confiança de cada célula abrange 50%.
- A memória do estado atual dura um mês. A partir do segundo passo, a probabilidade projetada é a mesma independentemente de onde a cadeia partiu.
- O tamanho da amostra decide a conclusão. Com três anos de dados os intervalos ficariam largos demais para qualquer afirmação; quatorze anos permitem dizer que as probabilidades são estatisticamente indistinguíveis de 50%.
- O modelo não falhou. Ele mediu com precisão a ausência de estrutura previsível, o que é coerente com a hipótese de eficiência de mercado de Fama (1970).
Considerações finais
Este exercício reproduz, com dados públicos e algumas dezenas de linhas de código, um procedimento que já foi domínio exclusivo de quem tinha acesso a terminal de dados e software proprietário. Baixar quatorze anos de cotações, estimar um modelo probabilístico e testar sua hipótese central é hoje trabalho de uma tarde.
O R é uma ferramenta natural para isso porque cobre o caminho inteiro num só ambiente: a coleta dos dados, o tratamento das séries, a estimação e o gráfico final. Não é preciso exportar planilha entre programas nem reescrever a análise quando a amostra muda — trocar a data de início e rodar de novo basta.
O alcance vai além das cadeias de Markov. O mesmo caminho de coletar, transformar, modelar e visualizar se repete em quase todo problema quantitativo, e muda apenas a aplicação:
- Analista de investimentos: testar se um padrão de mercado que parece existir sobrevive ao intervalo de confiança.
- Economista: modelar transições entre regimes de crescimento, inflação ou política monetária.
- Gestor de carteira: estimar probabilidades de mudança de regime para calibrar exposição ao risco.
- Profissional de risco: usar matrizes de transição para migração de rating de crédito, aplicação clássica do método.
- Trader quantitativo: separar sinal de ruído antes de transformar uma hipótese em estratégia.
Aprender a linguagem é o que abre a porta para todas essas frentes, e o caminho começa pelos fundamentos: importar dados, tratar séries e construir a primeira análise do começo ao fim.
Você viu como funciona; aprenda a construir do zero
A formação Do Zero à Análise de Dados Econômicos e Financeiros usando R ensina exatamente o caminho deste exercício, sem exigir conhecimento prévio: coletar dados de fontes públicas, tratar séries temporais, modelar e visualizar. Quem quer acesso a todas as formações tem o AM Black, a assinatura anual.
Referências
- Fama, E. F. (1970). Efficient Capital Markets: A Review of Theory and Empirical Work. The Journal of Finance, 25(2), 383–417.
- Norris, J. R. (1997). Markov Chains. Cambridge University Press.
- Ross, S. M. (2014). Introduction to Probability Models. 11ª ed. Academic Press.
- Spedicato, G. A. (2017). Discrete Time Markov Chains with R. The R Journal, 9(2), 84–104.
Leia também: