A análise de dados é uma parte crucial do mercado financeiro e a técnica de diferenças em diferenças (DID) é uma abordagem eficaz para avaliar a relação entre duas variáveis. DID permite que você compare a mudança na variável dependente entre dois grupos antes e depois de um evento específico, ajudando a determinar se a mudança é causada pelo evento. No post de hoje, trataremos de avaliar o efeito nos retornos da ação da Eletrobras devido a sua privatização utilizando as ferramentas de DID e Controle Sintético no R.
Diferenças em Diferenças
Diferenças em Diferenças (DID) é uma técnica de inferência causal que compara a mudança na variável dependente entre dois grupos antes e depois de um evento específico. O objetivo é determinar se a mudança na variável dependente é causada pelo evento.
A técnica DID assume que os grupos são comparáveis antes do evento e que qualquer diferença na mudança na variável dependente após o evento pode ser atribuída ao evento. Isso é conhecido como "pressuposto de tendências paralelas". Se as tendências nos grupos eram semelhantes antes do evento, então qualquer diferença na mudança após o evento é provavelmente causada pelo evento.
A equação de regressão é usada para estimar o efeito do evento na variável dependente. A equação de regressão inclui a variável dependente, a variável independente (representando o evento) e as covariáveis. As covariáveis são variáveis que afetam a relação entre a variável dependente e independente e precisam ser controladas para evitar conclusões equivocadas.
A equação de regressão é usada para estimar o efeito do evento na variável dependente, controlando as covariáveis. O coeficiente da variável independente representa o efeito do evento na variável dependente. Se o coeficiente é significativo, isso sugere que o evento teve um efeito na variável dependente.
Em resumo, DID é uma técnica que permite avaliar a relação causal entre duas variáveis, comparando a mudança na variável dependente antes e depois de um evento, controlando outras variáveis que possam afetar a relação. A equação de regressão é usada para estimar o efeito do evento na variável dependente, tornando possível determinar se a mudança na variável dependente é causada pelo evento.
Exemplo: Privatização da Eletrobras
Para ilustrar o conceito de DiD, podemos utilizar como exemplo a privatização da Eletrobras ocorrida no ano de 2022. Tomaremos como evento principal o dia anterior em que as ações pertencentes a União foram negociadas, 13/06/2023. Obs. o uso de um dia anterior se refere ao fato de que utiliza-se o preço de fechamento.
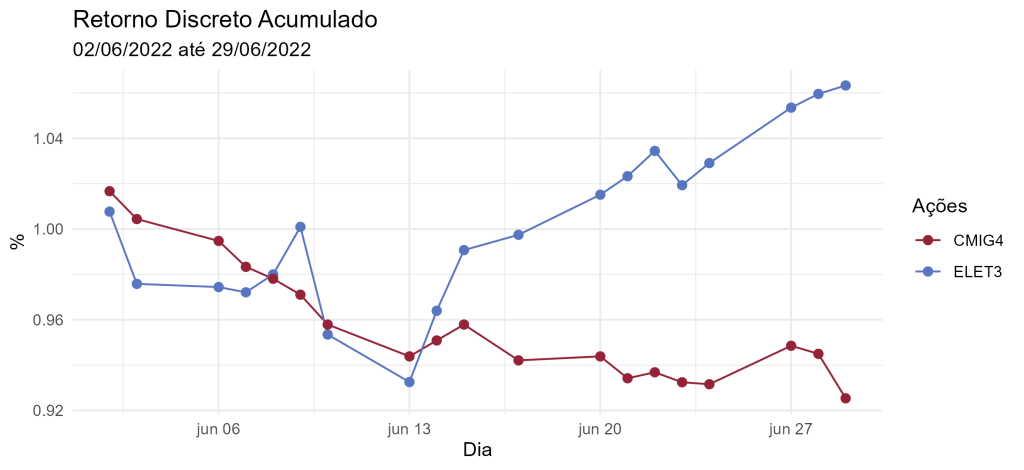
A ideia é verificar o desempenho dos retornos das ações da ELET3 com as ações de outra empresa que provêm serviços de Geração, transmissão, distribuição e comercialização de energia elétrica, portanto, vamos comparar a série de Retorno Acumulado Discreto das ações da ELETR3 e CMIG4, ambas empresas de economia mista, no período de 02/06/2022 até 29/06/2022.
A construção de todos os procedimentos para a coleta e criação dos gráficos abaixo você pode obter fazendo parte do Clube AM, o repositório especial de códigos da Análise Macro.
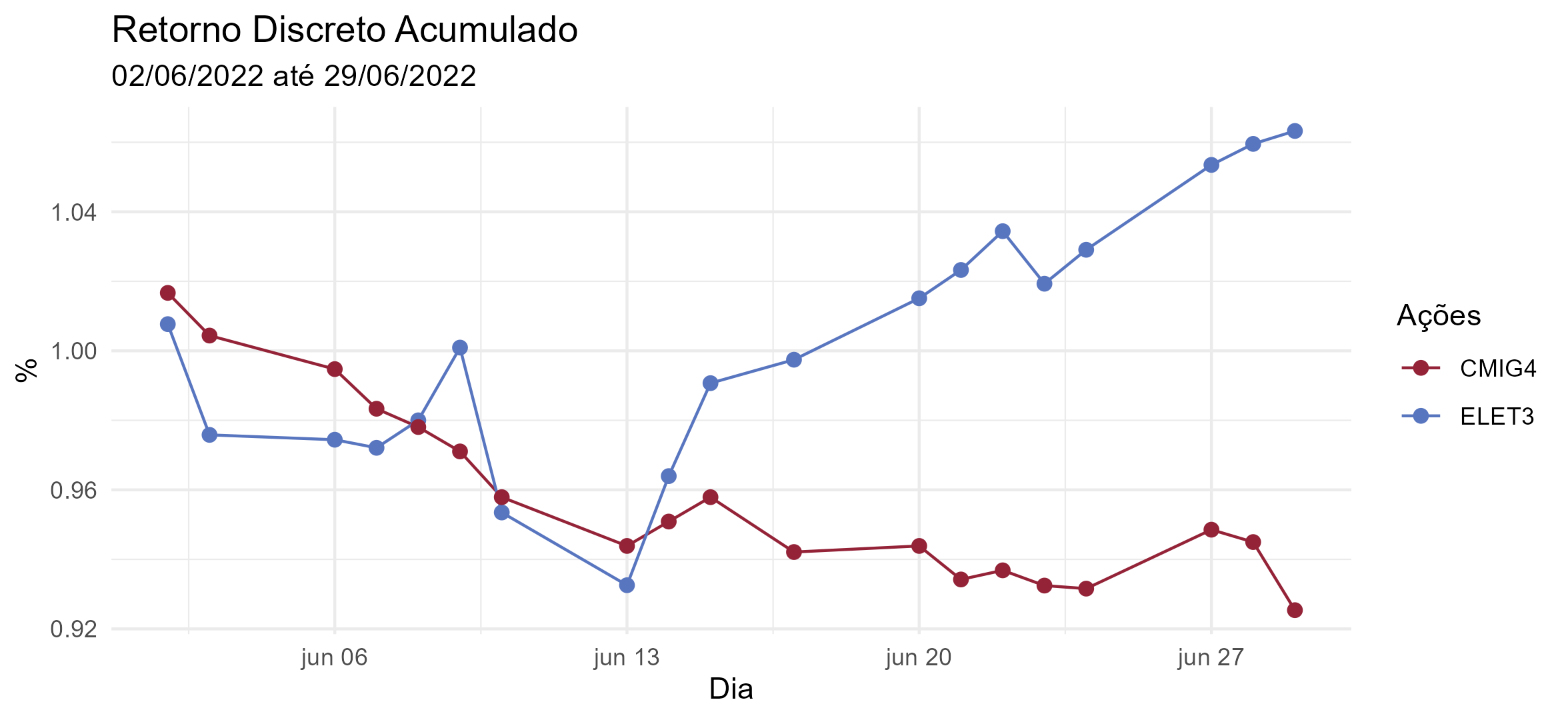
É interessante notar que de fato não há uma tendência paralela perfeita, em que a observação da ELETR3 do dia 09/06 exibe um salto, entretanto, ainda podemos considerar que antes de 13/06/2022 elas caminham juntas de fato. Além disso, após 13/06, é possível verificar o salto do retorno acumulado da ELETR3.
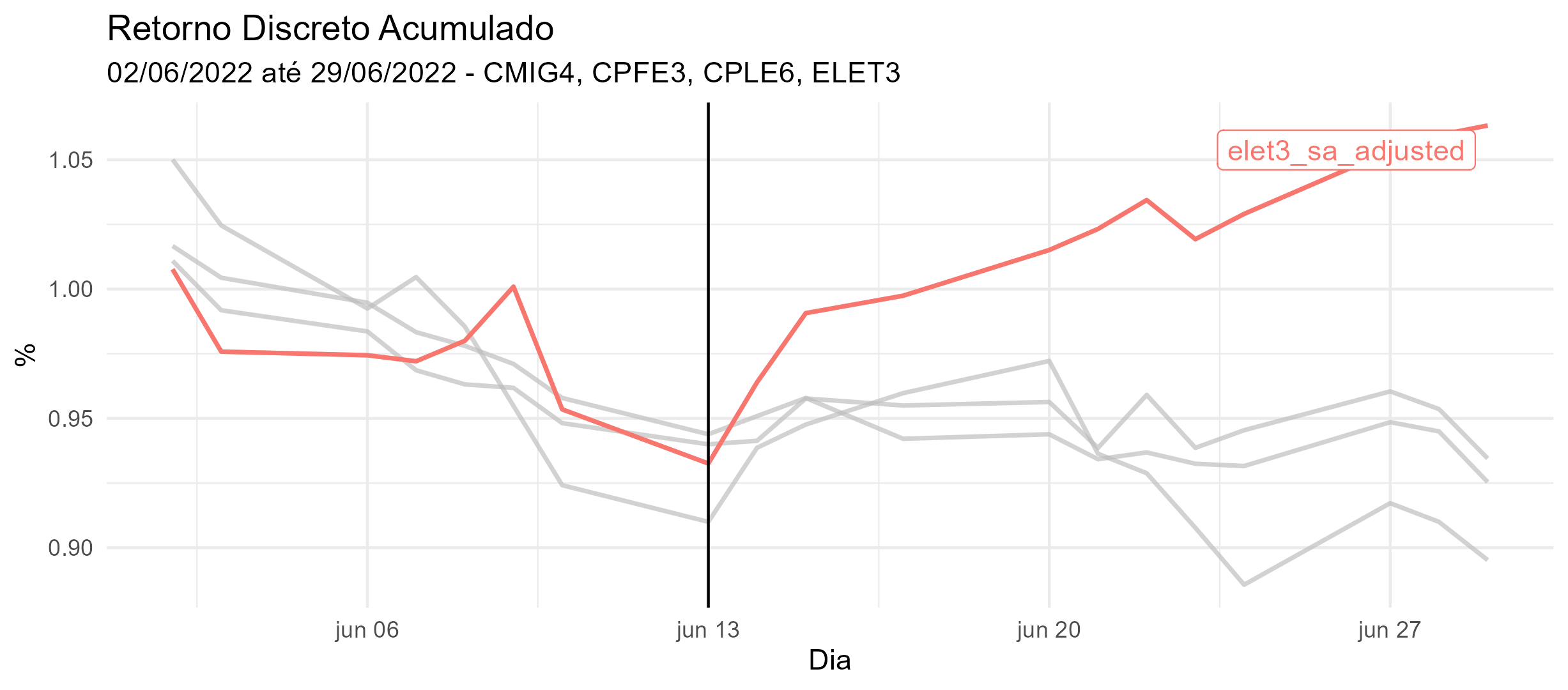
Agora, vejamos a comparação com outras empresas de economias mistas que oferecem serviços de Geração, transmissão, distribuição e comercialização de energia elétrica, a saber, CMIG4, CPFE, CPLE6.
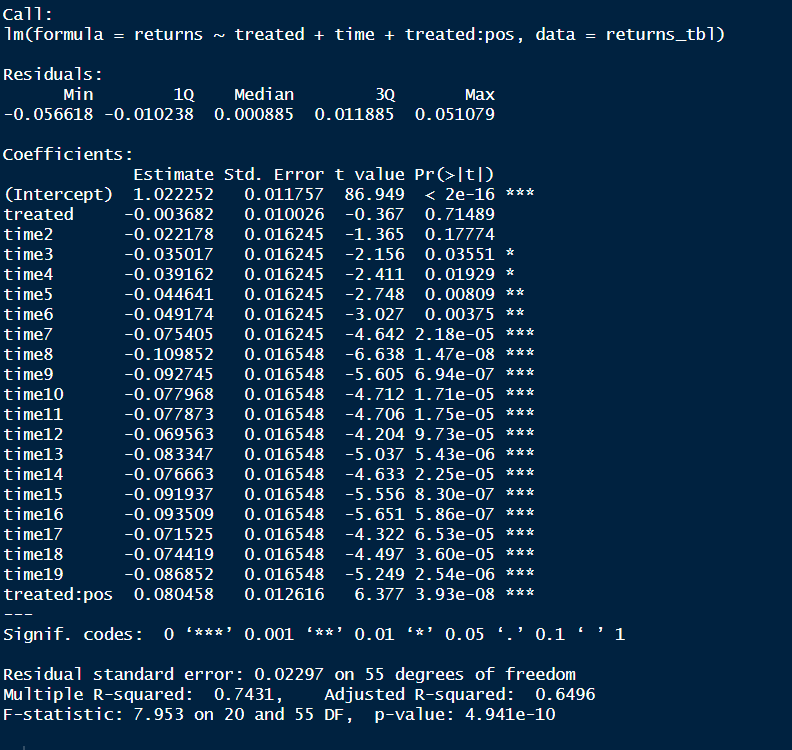
Podemos então sugerir o uso da regressão DiD através da função lm(). Na imagem abaixo, temos a equação utilizada e os resultados.
Controle Sintético
O Controle Sintético é outra técnica de inferência causal que busca comparar a mudança na variável dependente entre dois grupos, assim como na DID. No entanto, ao contrário da DID, que compara a mudança antes e depois de um evento específico, o Controle Sintético compara a mudança na variável dependente entre um grupo de tratamento e um grupo de controle que são semelhantes ao grupo de tratamento, exceto pelo evento em questão.
O Controle Sintético usa algoritmos para identificar grupos de controle semelhantes ao grupo de tratamento, baseados em covariáveis, e compara a mudança na variável dependente entre esses grupos. O objetivo é estimar o efeito do evento, controlando outras variáveis que possam afetar a relação.
Com o pacote {microsynth}, podemos criar um controle sintético usando as demais empresas e comparar a diferenças com o Retorno Acumulado da ELET3.
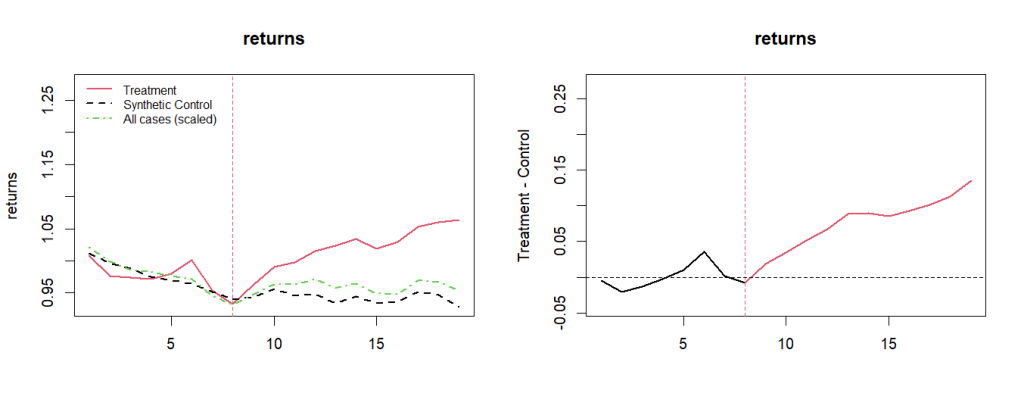
Em resumo, tanto o Controle Sintético quanto a DID são técnicas de inferência causal que buscam avaliar a relação entre duas variáveis, comparando a mudança na variável dependente entre grupos. No entanto, enquanto a DID compara a mudança antes e depois de um evento específico, o Controle Sintético compara a mudança entre um grupo de tratamento e um grupo de controle semelhante. Ambas as técnicas buscam controlar outras variáveis que possam afetar a relação e estimar o efeito do evento na variável dependente.
_____________________________________
Quer saber mais?
Veja nossa trilha de cursos de Finanças Quantitativas e de Avaliação de Políticas Públicas.

