A análise de componentes principais ou Principal component analysis, consiste em uma técnica popular que visa reduzir a dimensionalidade de um conjunto de variáveis. No post de hoje, iremos realizar uma aplicação da técnica em finanças utilizando o R.
O objetivo do uso da análise de componentes principais consiste em reduzir um número significante de variáveis que explicam uma variável resposta, de forma a encontrar a variabilidade em torno de cada variável latente, isto é, uma variável "oculta" que explica a variável resposta.
A partir disso é possível compreender quais as variáveis latentes, isto é, quantos fatores de risco representam a variabilidade de um conjunto de ações ou índices de investimentos.
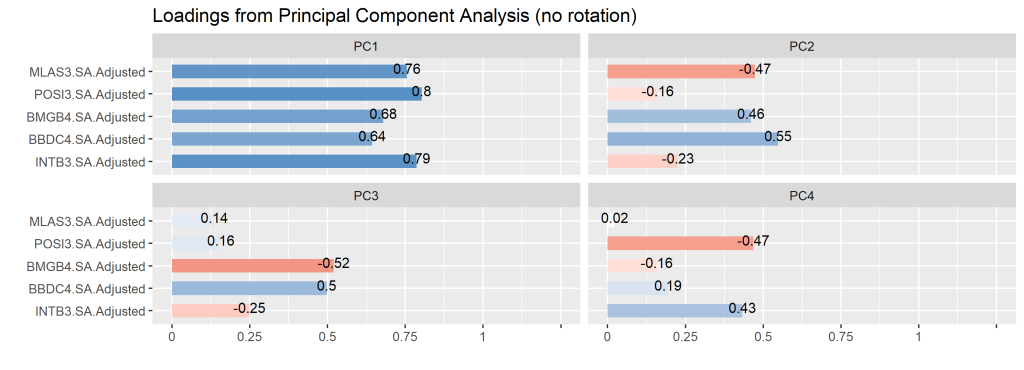
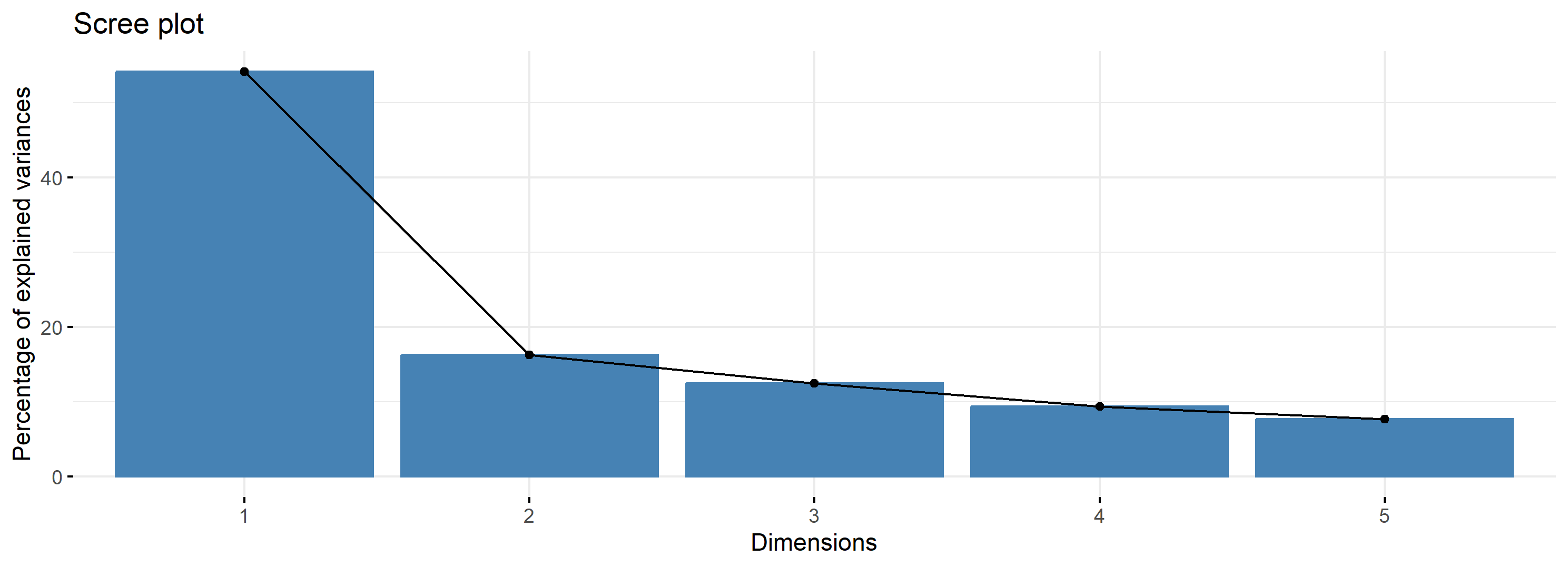
Vejamos a aplicação utilizando o R. Selecionamos 6 ações, 3 compreendendo o setor de tecnologia e 3 o setor de financeiro. Ao aplicar o PCA, vemos o primeiro componente principal explica 54,19% da variabilidade dos retornos. Pelo gráfico abaixo, fica fácil de perceber que o PCA1 é apenas uma proxy do risco de mercado.
Além disso, fica fácil perceber a relação dos fatores entre os ativos. Isso pode permitir o avanço na construção de uma carteira diversificada.
_____________________________________
Quer saber mais?
Veja nossa trilha de cursos de Finanças Quantitativas.

