
O aprendizado de máquina (ML) é visto como parte da inteligência artificial. Algoritmos de ML constroem um modelo com base em dados de treinamento para fazer previsões ou decisões sem serem explicitamente programados para fazê-lo. Neste exercício, usamos o Python para aplicar modelos de ML conhecidos como random forests e neural networks a uma aplicação simples na precificação de opções: o treinamento dos modelos para aprender a precificar opções de compra sem conhecimento prévio dos fundamentos teóricos da famosa equação de precificação de opções de Black e Scholes (1973).
Os dados utilizados correspondem aos contratos de opções da empresa VALE durante o ano de 2023. Esses contratos são classificados como opções de compra (“Call options”) e incluem uma variedade de informações essenciais para o cálculo do preço por meio da equação de Black-Scholes, explicada abaixo.
Aprenda a coletar, processar e analisar dados no Workshop Do Zero à Análise de Dados Econômicos e Financeiros usando Python, se inscreva aqui!
Apreçamento de ações
Em sua forma mais básica, opções de compra dão ao proprietário o direito, mas não a obrigação, de comprar uma ação específica (o ativo subjacente) a um preço específico (o preço de exercício  ) em uma data específica (a data de exercício
) em uma data específica (a data de exercício  ). O preço de Black-Scholes (Black e Scholes 1973) de uma opção de compra para um ativo subjacente que não paga dividendos é dado por
). O preço de Black-Scholes (Black e Scholes 1973) de uma opção de compra para um ativo subjacente que não paga dividendos é dado por
(1) 
(2) 
(3) 
onde  é o preço da opção como função do preço da ação subjacente hoje,
é o preço da opção como função do preço da ação subjacente hoje,  , com tempo até o vencimento, ,
, com tempo até o vencimento, ,  é a taxa de juros livre de risco e
é a taxa de juros livre de risco e  é a volatilidade do retorno da ação subjacente.
é a volatilidade do retorno da ação subjacente.  é a função de distribuição cumulativa de uma variável aleatória normal padrão.
é a função de distribuição cumulativa de uma variável aleatória normal padrão.
A equação de Black-Scholes fornece uma maneira de calcular o preço livre de arbitragem de uma opção de compra uma vez que os parâmetros , e são especificados (argumentavelmente, em um contexto realista, todos os parâmetros são fáceis de especificar, exceto , que deve ser estimado).
Criação dos Modelos
Nosso objetivo aqui é denominar o preço da opção como variável dependente e as demais variáveis como independentes e imputar nos modelos de ML. Para tanto, realizamos os seguintes procedimentos:
- Separamos o conjunto de treino (80%) e teste (20%)
- Normalizamos os valores das variáveis utilizadas
- Treinamos os modelos
- Avaliamos o modelo, calculando o erro médio absoluto.
Avaliação dos Modelos
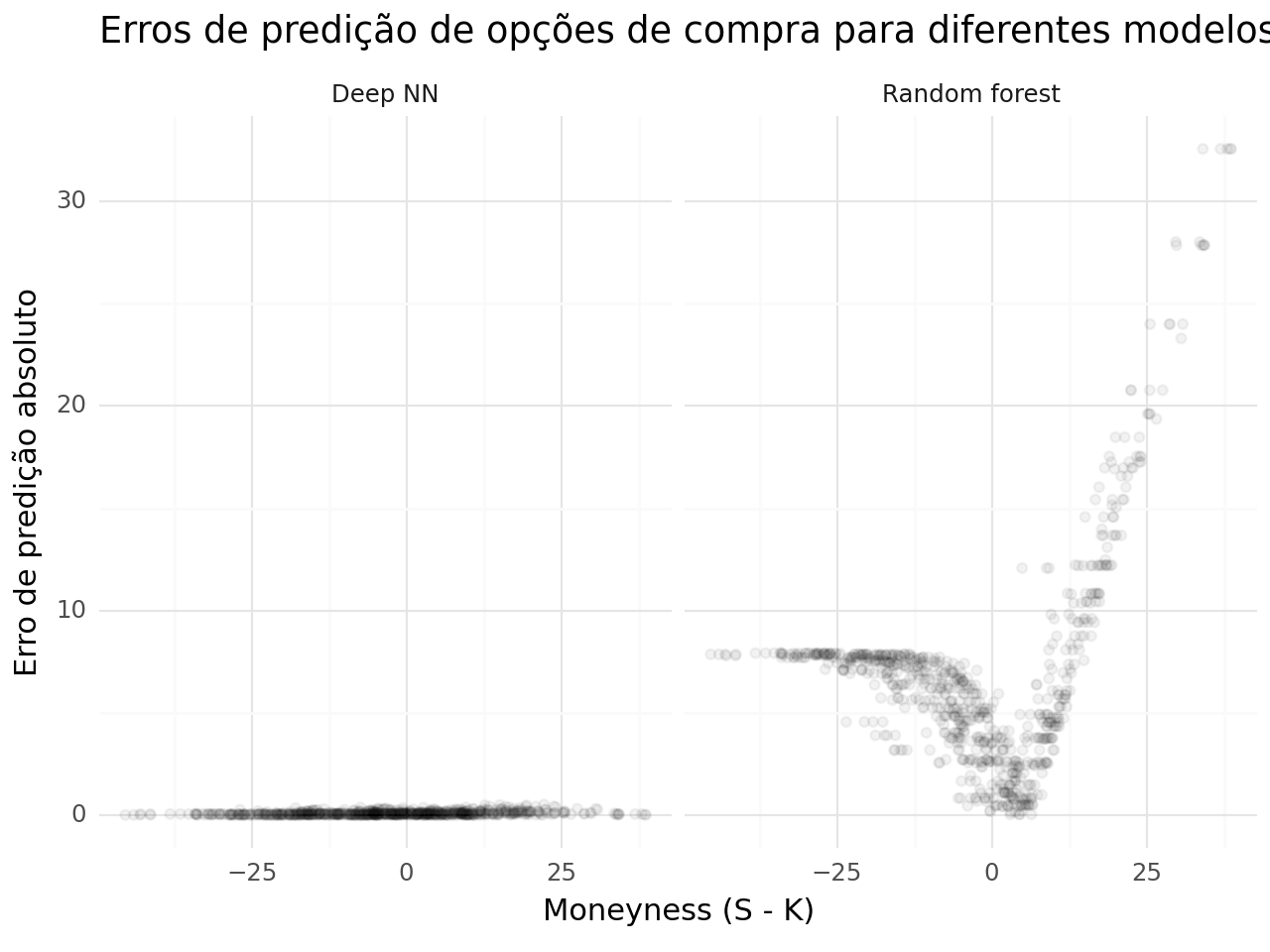
A figura abaixo mostra o erro de previsão absoluto para os valores obtidos pelos dois modelos. O erro de previsão é avaliado em uma amostra de opção de compra que não foram usadas para o treino. O que verificamos é que Deep Neural Networks performou muito melhor que Random Forest, obtendo um erro de previsão menor em todos os locais de dinheiro, enquanto o Random Forest possui somente um baixo erro de previsão de opções no dinheiro.
Quer aprender mais?
Clique aqui para fazer seu cadastro no Boletim AM e baixar o código que produziu este exercício, além de receber novos exercícios com exemplos reais de análise de dados envolvendo as áreas de Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas diretamente em seu e-mail.
Referências
Christoph Frey, Chistoph Scheuch, Stefan Voigt, Patrick Weiss. Tidy Finance with Python. https://www.tidy-finance.org/python/
Black, Fischer, and Myron Scholes. 1973. “The pricing of options and corporate liabilities.” Journal of Political Economy 81 (3): 637–54. https://www.jstor.org/stable/1831029.

