Resumo
Este projeto demonstra como criar um dashboard para análise de dados das demonstrações financeiras de empresas brasileiras, utilizando dados disponibilizados pela CVM. Desenvolvemos o dashboard com Python e Shiny, permitindo a coleta, tratamento e análise dos dados diretamente na interface.
Como automatizar uma análise?
Com uma linguagem de programação, é possível desenvolver métodos que automatizam processos, facilitando sua implementação em sistemas como dashboards.
Estrutura do Dashboard
O desenvolvimento do dashboard será feito em etapas:
- Compreensão e uso das fontes de dados;
- Criação de um código para coleta de dados;
- Análise e visualização de dados por meio de gráficos;
- Implementação do código em um ambiente de dashboard;
- Automatização da coleta e análise com o GitHub Actions.
O que iremos analisar?
Antes de começar o código, vamos entender melhor o escopo do que será construído. A partir dessa compreensão, utilizaremos um exemplo inicial como protótipo do dashboard.
Indicadores contábeis
Indicadores extraídos das demonstrações financeiras auxiliam decisões de investimento e representam uma base importante na análise fundamentalista. Com esses indicadores, é possível comparar empresas do mesmo setor e avaliar se uma ação está "descontada" (ou seja, com preço de mercado abaixo de seu valor intrínseco), gerando oportunidades de investimento.
A análise regular desses indicadores é essencial para investidores, mas muitos encontram dificuldade não apenas em acessar esses dados, como também em automatizar o processo de coleta e análise.
Com o código disponível, vamos mostrar como importar automaticamente os demonstrativos das empresas listadas na B3 e realizar uma análise inicial dos indicadores.
Demonstrações Financeiras Padronizadas
Antes de buscar os dados, é importante compreender a fonte. As empresas listadas na B3 enviam à CVM suas Demonstrações Financeiras Padronizadas, de acordo com as instruções contábeis da CVM.
Entre os demonstrativos obrigatórios na DFP, temos:
- Balanço Patrimonial Ativo (BPA)
- Balanço Patrimonial Passivo (BPP)
- Demonstração de Fluxo de Caixa - Método Direto (DFC-MD)
- Demonstração de Fluxo de Caixa - Método Indireto (DFC-MI)
- Demonstração das Mutações do Patrimônio Líquido (DMPL)
- Demonstração de Resultado Abrangente (DRA)
- Demonstração de Resultado (DRE)
- Demonstração de Valor Adicionado (DVA)
Dados da CVM
As informações sobre as DFPs podem ser acessadas no Portal de Dados da CVM, com histórico disponível desde 2011:
Para baixar o histórico, clique em “Histórico desde 2010,” que leva a uma página com os arquivos anuais em formato zip. Esses arquivos são extensos e contêm diversos subarquivos, o que pode dificultar o trabalho.
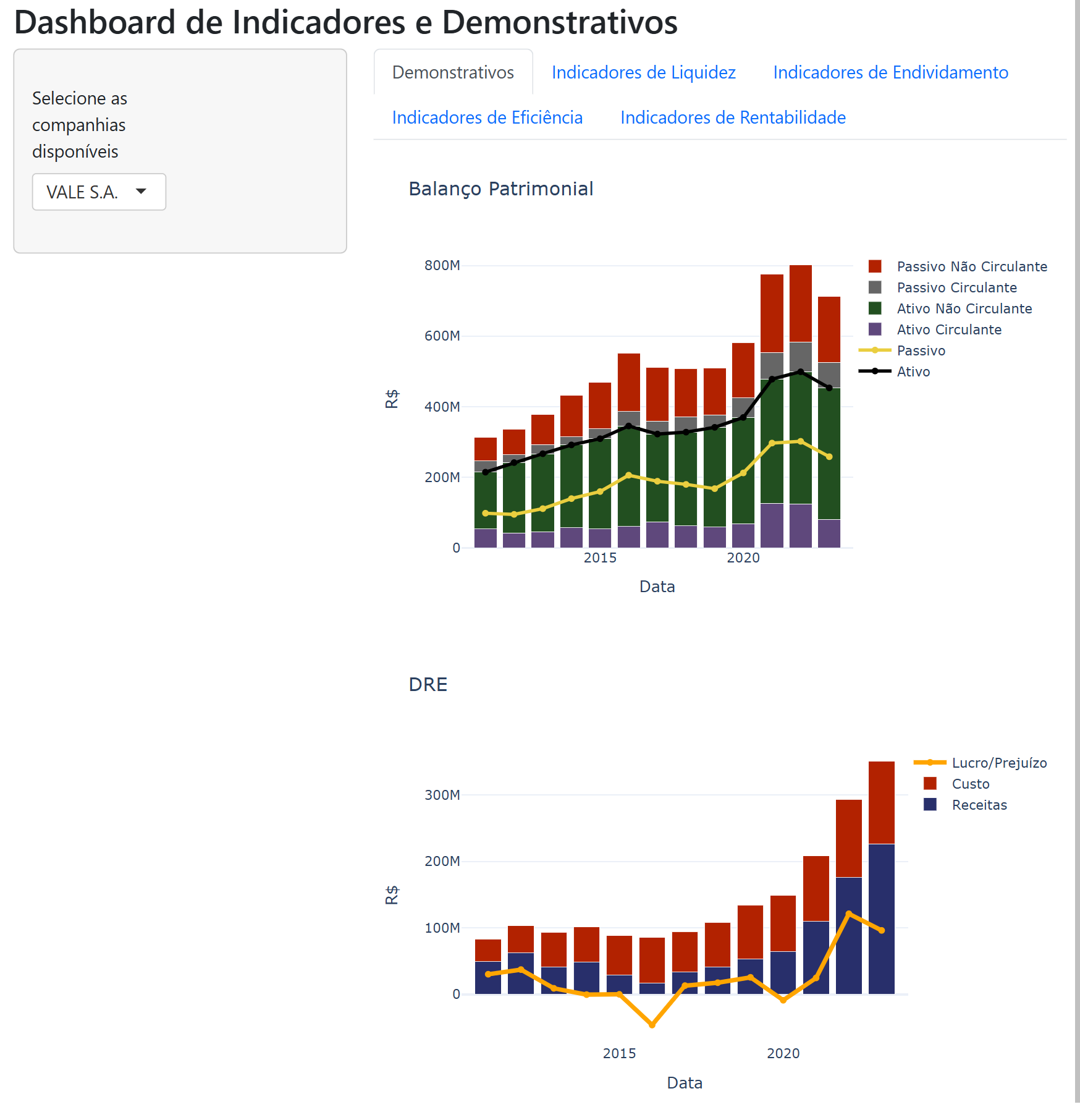
Exemplo do Dashboard
Abaixo, apresentamos uma imagem do dashboard criado com Python e Shiny.
Tenha acesso ao código e suporte desse e de mais 500 exercícios no Clube AM!
Quer o código desse e de mais de 500 exercícios de análise de dados com ideias validadas por nossos especialistas em problemas reais de análise de dados do seu dia a dia? Além de acesso a vídeos, materiais extras e todo o suporte necessário para você reproduzir esses exercícios? Então, conheça o Clube AM clicando aqui.

