Introdução
A Inteligência Artificial Generativa (IA Generativa) redefiniu os limites da automação, permitindo otimizar processos manuais e repetitivos em diversas áreas. Na economia, finanças e ciência de dados, o impacto é transformador. Desde a coleta de dados brutos até a análise e apresentação de insights, a IA Generativa atua como um multiplicador de produtividade.
Neste artigo, vamos demonstrar como criar um AI Assistant — um “analista-robô” encarregado de ler, interpretar e resumir os resultados financeiros (Release de Resultados) de empresas brasileiras. O objetivo é automatizar o fluxo de trabalho que analistas fundamentalistas e agentes do mercado financeiro realizam a cada temporada de balanços trimestrais.
Quer ver a vídeoaula do tutorial deste exercício? E receber o código que o produziu? Faça parte do Clube AM e receba toda semana os códigos em R/Python, vídeos, tutoriais e suporte completo para dúvidas.
Para garantir uma excelente experiência ao usuário final, este assistente operará dentro de um Dashboard interativo construído com Shiny para Python. A seguir, detalhamos o passo a passo desse desenvolvimento.
Passo 01: Configuração do Ambiente e Bibliotecas
Iniciamos preparando o ambiente e instalando as dependências do projeto. Além das bibliotecas centrais, utilizaremos o python-dotenv, que é responsável por carregar variáveis de ambiente a partir de um arquivo .env — uma prática de segurança indispensável para não expor chaves de API no código-fonte.
# Instalação das dependências no terminal
pip install google-genai shiny shinywidgets plotly requests python-dotenvA arquitetura do nosso projeto depende das seguintes bibliotecas:
requests: Para realizar o download do arquivo PDF diretamente do site de Relações com Investidores (RI) da empresa.shinyeshinywidgets: Para a construção da interface reativa do dashboard.google.genai: O novo SDK do Google para interagir com o modelo Gemini.plotly: Para a renderização dos gráficos de velocímetro (gauges).dotenv: Para o gerenciamento seguro de credenciais.
# Importação das bibliotecas
import requests, json, os
from shiny import reactive
from shiny.express import ui, render, input
import shinywidgets as sw
from google import genai
from google.genai import types
import plotly.graph_objects as go
from dotenv import load_dotenvPasso 02: Configurando o Modelo LLM (Gemini 2.5 Flash)
Para a análise do relatório, optamos pelo Gemini 2.5 Flash, o modelo mais recente da Google (no momento de publicação deste artigo). Ele foi escolhido por sua janela de contexto massiva e excelente custo-benefício, combinando alta capacidade de raciocínio com velocidade de inferência.
A chave de API é carregada de forma segura. Crie um arquivo chamado .env na raiz do seu projeto (e lembre-se de adicioná-lo ao .gitignore) com a seguinte estrutura: GEMINI_API_KEY=sua_chave_aqui.
Com a chave carregada, instanciamos o cliente centralizado genai.Client(). No novo SDK google-genai, este cliente substitui a antiga necessidade de configurar o ambiente e instanciar o modelo separadamente.
# Carrega as variáveis de ambiente do arquivo .env
load_dotenv()
# Inicializa o cliente da API do Gemini
client = genai.Client(api_key=os.getenv("GEMINI_API_KEY"))Passo 03: Construindo a Interface do Dashboard
Avançamos para a interface visual (UI). O layout é composto por um campo de input onde o usuário insere a URL do PDF do balanço financeiro.
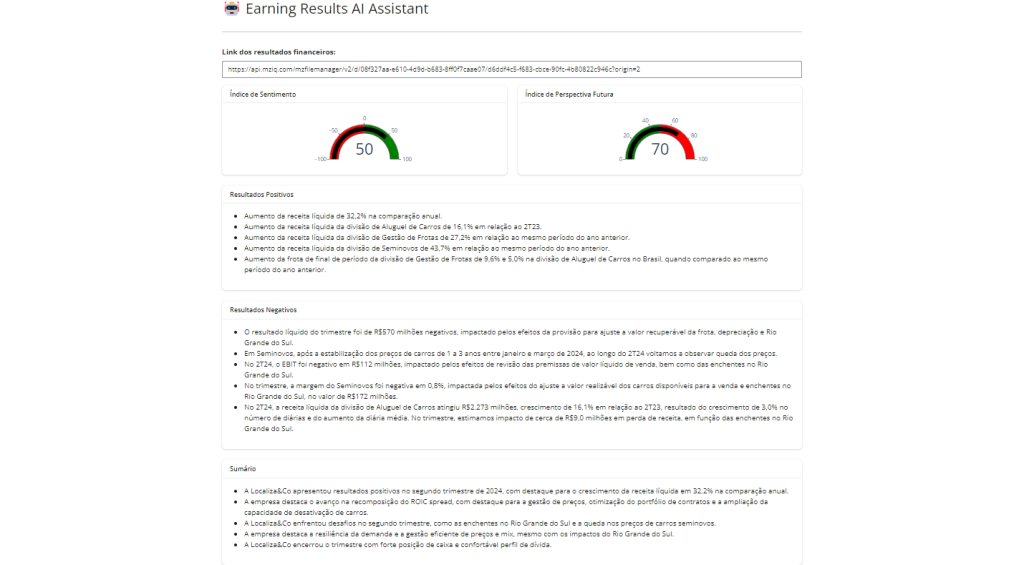
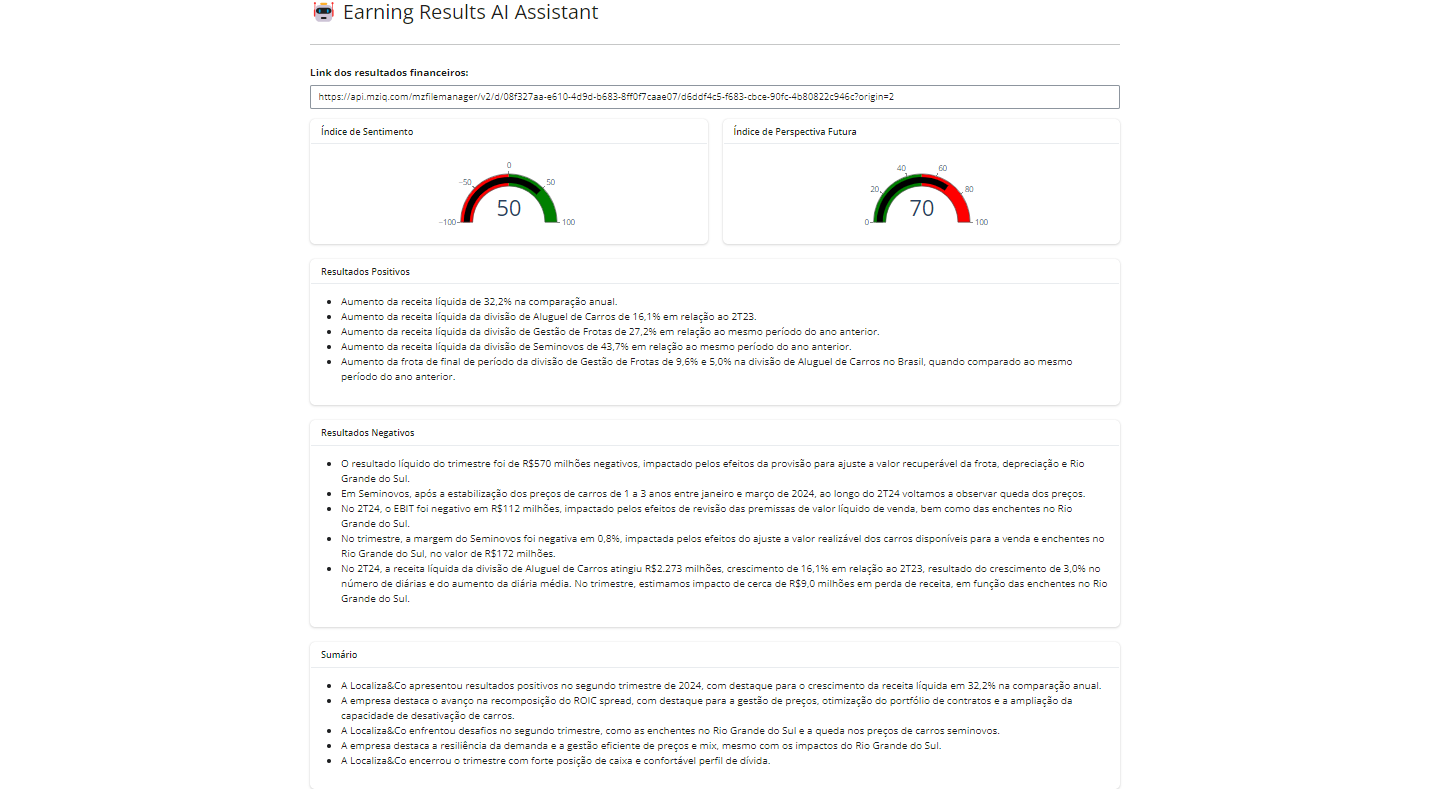
Os outputs (resultados da IA) são divididos em componentes visuais:
- Dois gráficos do tipo Gauge (velocímetro) para quantificar o Índice de Sentimento e a Perspectiva Futura.
- Três cartões de texto (Cards) renderizando Markdown para listar: Tópicos Positivos, Tópicos Negativos e um Sumário Executivo.
# Interface Visual do Shiny
ui.page_opts(title="🤖 Earning Results AI Assistant")
ui.hr()
# Input do usuário
ui.input_text(
id="url_empresa",
label=ui.strong("Link dos resultados financeiros (PDF): "),
value="https://api.mziq.com/mzfilemanager/v2/d/08f327aa-e610-4d9d-b683-8ff0f7caae07/d6ddf4c5-f683-cbce-90fc-4b80822c946c?origin=2",
placeholder="Insira a URL do PDF aqui",
width="100%"
)
# Painel principal com os Gauges
with ui.layout_column_wrap(height="200px"):
with ui.card():
ui.card_header("Índice de Sentimento")
@sw.render_widget
def sentimento():
return go.Figure(go.Indicator(
mode="gauge+number",
value=prompt_ia()["sentimento"],
domain={"x": [0, 1], "y": [0, 1]},
gauge={
"axis": {"range": [-100, 100]},
"bar": {"color": "black"},
"steps": [
{"range": [-100, 0], "color": "red"},
{"range": [0, 100], "color": "green"},
]
}))
with ui.card():
ui.card_header("Índice de Perspectiva Futura")
@sw.render_widget
def incerteza():
return go.Figure(go.Indicator(
mode="gauge+number",
value=prompt_ia()["perspectiva"],
domain={"x": [0, 1], "y": [0, 1]},
gauge={
"axis": {"range": [0, 100]},
"bar": {"color": "black"},
"steps": [
{"range": [0, 50], "color": "red"},
{"range": [50, 100], "color": "green"},
]
}))
# Painéis de Texto (Markdown)
with ui.card():
ui.card_header("Resultados Positivos")
@render.ui
def topicos():
return ui.markdown("- " + "\n- ".join(prompt_ia()["positivos"]))
with ui.card():
ui.card_header("Resultados Negativos")
@render.ui
def outliers():
return ui.markdown("- " + "\n- ".join(prompt_ia()["negativos"]))
with ui.card():
ui.card_header("Sumário Executivo")
@render.ui
def resumo():
return ui.markdown("- " + "\n- ".join(prompt_ia()["resumo"]))Passo 04: Coleta de Dados, Upload e Engenharia de Prompt
O coração do nosso assistente é a função reativa prompt_ia(). Ela é engatilhada automaticamente sempre que a URL no input é alterada. O fluxo lógico ocorre em três etapas:
- Download do PDF: O arquivo é baixado via
requestse salvo temporariamente no servidor local. - Upload para a API: O PDF é enviado para os servidores do Google via
client.files.upload(). Isso permite que o Gemini processe o documento nativamente, eliminando a necessidade de bibliotecas complexas de extração de texto (como PyPDF2). - Geração de Conteúdo (Inferência): Enviamos as instruções do sistema (System Instructions) definindo a persona da IA como um Analista de Ações, juntamente com o prompt exigindo uma saída estritamente em formato JSON.
# Função Reativa Principal
@reactive.calc
def prompt_ia():
ui.notification_show(
"Baixando os Resultados Financeiros da empresa...",
type="message",
duration=5,
)
# 1. Fazer o download do PDF
response = requests.get(input.url_empresa())
if response.status_code == 200:
with open("resultados.pdf", "wb") as f:
f.write(response.content)
print("Download concluído e salvo como 'resultados.pdf'.")
else:
print(f"Erro ao baixar o arquivo. Status code: {response.status_code}")
ui.notification_show(
"Comunicado baixado, preparando dados para análise...",
type="message",
duration=5,
)
# 2. Faz o upload do PDF para a API do Gemini
arquivo_pdf = client.files.upload(
file="resultados.pdf",
config=types.UploadFileConfig(
display_name="Resultados PDF",
mime_type="application/pdf"
)
)
# 3. Engenharia de Prompt
instructions = """
Você é um Analista de Ações Sênior com amplo conhecimento em análise de demonstrações
financeiras de empresas brasileiras de capital aberto.
Você receberá um documento PDF oficial sobre os resultados trimestrais de uma empresa.
"""
prompt = """Sua tarefa é:
1. Analisar o sentimento geral do resultado e retornar um índice numérico de -100 a 100
(-100 = muito negativo, 0 = neutro, 100 = muito positivo).
2. Analisar as perspectivas futuras da empresa com base no *guidance* e cenário macroeconômico.
Retorne um índice numérico de 0 a 100 (0 = péssima perspectiva, 100 = excelente perspectiva).
3. Listar os top 5 tópicos positivos apresentados no resultado.
4. Listar os top 5 tópicos negativos ou riscos apresentados no resultado.
5. Resumir o comunicado em 5 pontos-chave.
Retorne sua resposta ESTRITAMENTE no formato de um arquivo JSON com as seguintes chaves exatas:
"sentimento", "perspectiva", "positivos", "negativos", "resumo".
Não inclua formatação markdown (como ```json) na sua resposta. Retorne apenas o objeto JSON puro.
"""
# Gera o conteúdo estruturado
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=[arquivo_pdf, prompt],
config=types.GenerateContentConfig(
system_instruction=instructions,
temperature=0.1, # Temperatura baixa para respostas mais analíticas e determinísticas
response_mime_type="application/json" # Força a saída em JSON
)
)
ui.notification_show(
"Analisando dados com IA...",
type="message",
duration=5,
)
# Converte a string JSON da resposta em um dicionário Python
ia_response = json.loads(response.text)
return ia_responseConsiderações Finais
O resultado deste código é um Dashboard analítico completo e funcional. Com apenas a URL de um PDF, o usuário obtém em segundos uma extração de sentimento quantitativa e um resumo qualitativo dos balanços corporativos. Como próximos passos para escalar esta solução, o aplicativo pode ser facilmente publicado na web utilizando serviços de deploy como o Shinyapps.io ou contêineres Docker em nuvem.

