Com o consequente aumento do uso de mecanismos de buscas para se obter informações sobre qualquer objeto de interesse, foi criado uma nova forma de obter relações entre diversas variáveis através dos dados. Essa questão também pode ser aplicada ao mercado financeiro. Com a inserção de mais brasileiros no mundo das finanças, o aumento de pesquisas sobre termos relacionados a empresas podem ser úteis na investigação dos movimentos de seus preços. No post de hoje iremos realizar um exercício, no qual iremos ver a relação entre a pesquisa do termo "Ibovespa" no Google com a cotação mensal da Ibovespa.
Primeiro, devemos obter nossos dados. Um forma simples de extrair o número de pesquisa de um termo se dá através do Google Trends, e em que podemos utilizar o pacote {gtrendsR}. Para extrair os dados da Ibovespa, utilizamos o pacote {quantmod}.
library(gtrendsR) library(tidyverse) library(timetk) library(quantmod) library(astsa)
</pre>
# Busca o termo "Ibovespa"
data_gtrends = gtrends(keyword = c("Ibovespa"),
geo = "BR", time='all', onlyInterest=TRUE)
# Tratamos os dados, seleciona o período e transforma em time series
ibov_gtrends <- purrr::map_df(data_gtrends, ~ .x) %>%
dplyr::select(date,hits) %>%
filter(date > "2018-01-01") %>%
tk_ts(start = 2018, frequency = 12)
<pre>
</pre>
# Busca a cotação da Ibovespa
getSymbols("^BVsp",
warnings = FALSE,
from = "2018-01-01",
src = "yahoo")
# Transforma os dados em mensais
ibovespa_monthly <- BVSP %>%
to.period(period = "months",
OHLC = TRUE)
# Transforma em objeto time series, retirando a cotação ajustada
ibovespa_ts <- ts(Ad(ibovespa_monthly), start = c(2018, 01), freq = 12)
<pre>
</pre> # Junta os dois objetos time series ibov_all <- ts.intersect(ibov_gtrends, ibovespa_ts) # Junta em um objeto data frame ibov_df <- data.frame(date = as.Date(time(ibov_all)), ibov_gtrends = ibov_all[,1], ibovespa = ibov_all[,2]/1000) <pre>
Vemos o comportamento das séries ao longo do tempo.
</pre>
# Plota os gráficos em conjunto
ggplot(ibov_df, aes(x = date))+
geom_line(aes(y = ibovespa, colour= 'Ibovespa'), size = .8)+
geom_line(aes(y = ibov_gtrends, colour = 'Ibovespa Gtrends'), size = .8)+
scale_y_continuous(sec.axis = sec_axis(~., name= 'Ibov Gtrends Hits'))+
scale_colour_manual('',
values=c('darkblue', 'red'))+
theme(legend.position = c(.2, .3))+
xlab('')+ylab('Ibovespa (mil pontos)')+
theme(axis.text.x = element_text(angle = 45, hjust = 1))+
labs(title='Ibovespa vs. Buscas por Ibovespa no Google',
caption='Fonte: analisemacro.com.br')
<pre>
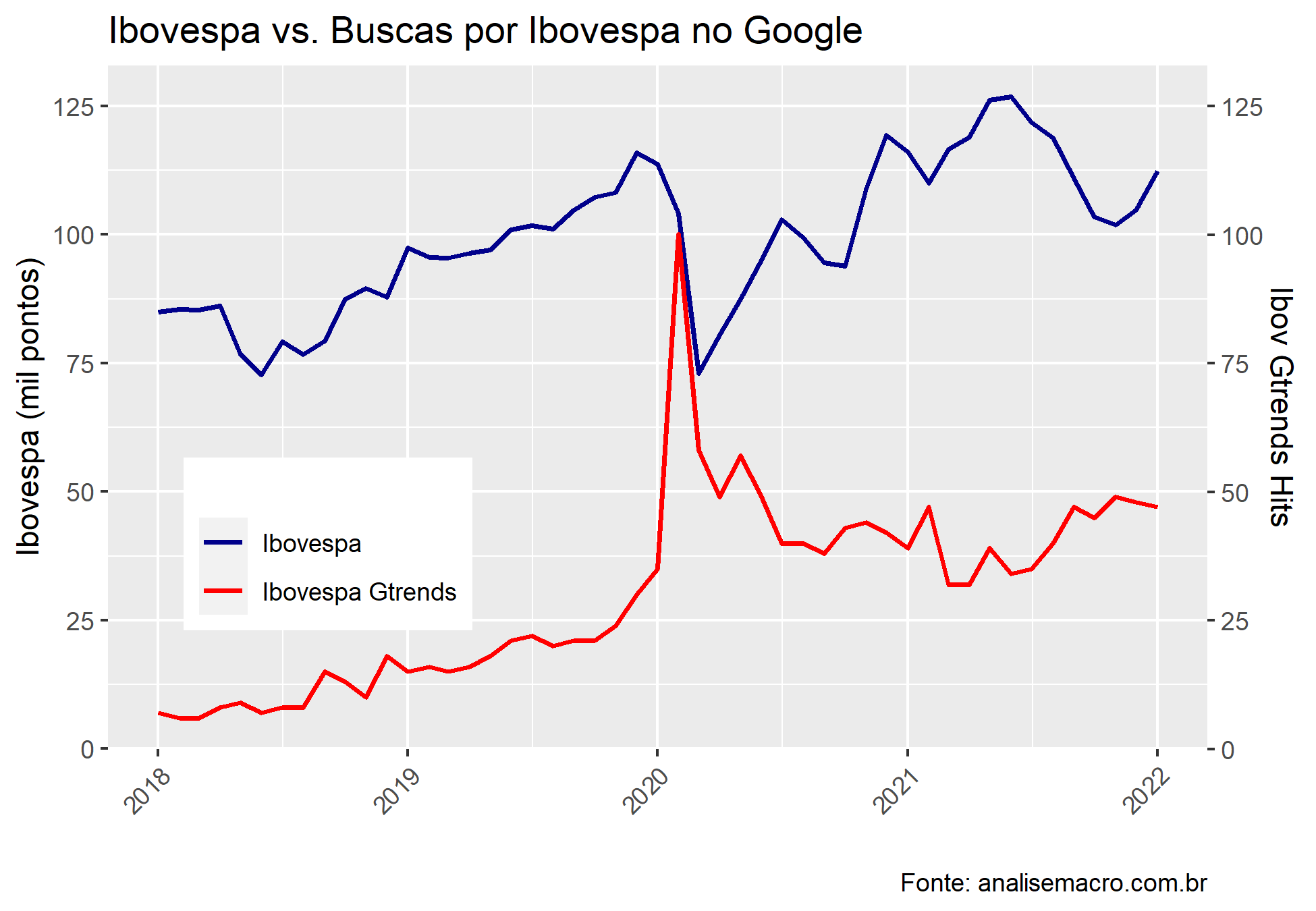
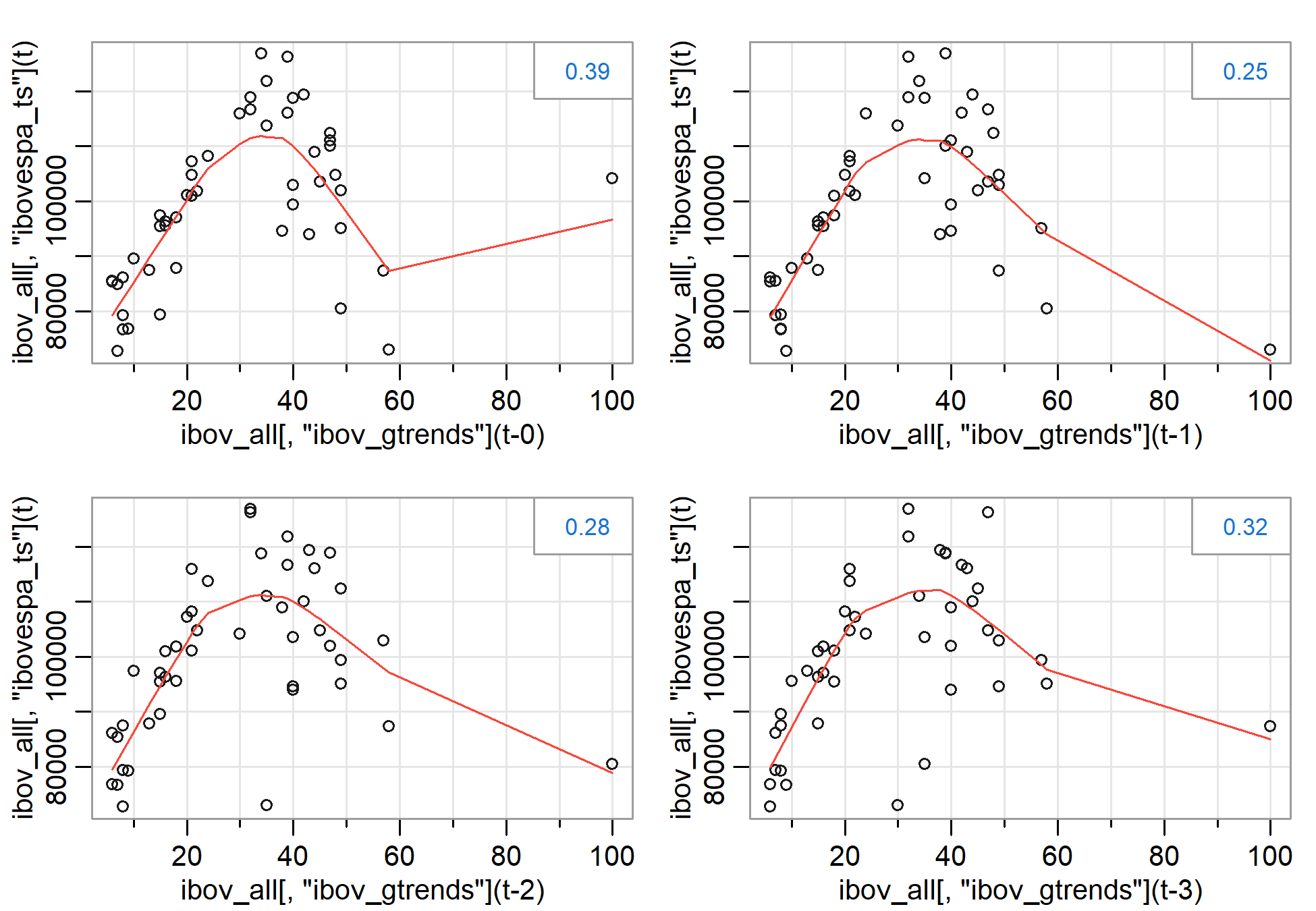
Podemos ver a correlação entre as séries e em relação a sua defasagens. Há um correlação positiva entre ambas, porém, não podemos inferir um evento causal, sendo necessário maiores investigações.
lag2.plot(ibov_all[,"ibov_gtrends"], ibov_all[,"ibovespa_ts"], max.lag = 3)
________________________
(*) Para conhecer mais sobre as relações entre variáveis do mundo das finanças, veja nossos Cursos de Finanças Quantitativas.
________________________

