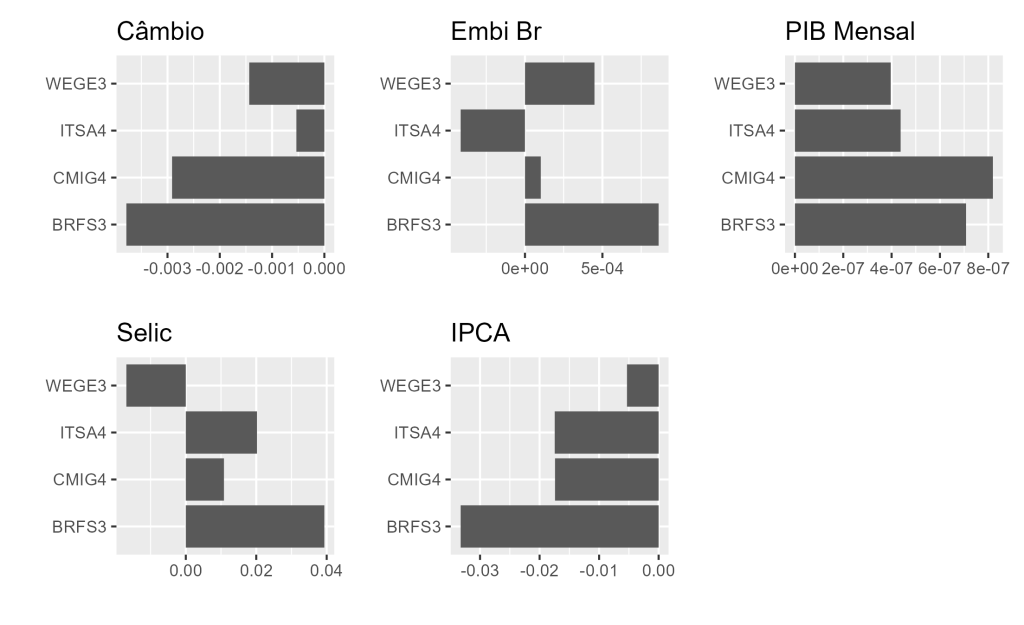
Vamos investigar os fatores que representam mudanças inesperadas de variáveis macroeconômicas em retornos de ações. A ideia será denotar a mudança inesperada como o resíduo de variáveis macroeconômicas após a remoção de sua dependência dinâmica por meio do uso de um VAR e utilizar uma regressão linear para modelar a relação com o mercado acionário. Fazemos o uso das variáveis Câmbio real, Embi BR, PIB Mensal, Selic e IPCA. Para verificar a relação, usamos o R e o Python como ferramentas de construção do exercício.
Variáveis macroeconômicas contém informações relevantes para a formação do preço de uma ação, entretanto, os preços de ações são comumente sensíveis a novas noticias econômicas, principalmente aquelas não esperadas.
Uma forma interessante de obter essa "informação não esperada" pode ser usando os erros de um VAR para um conjunto de variáveis macroeconômicas estabelecidas.
Neste exercício, escolhemos: Câmbio real, Embi BR, PIB Mensal, Selic e IPCA para obter as informações não conhecidas, usando o resíduo do modelo. Com a obtenção do resíduo de cada variável, as regredimos e obtemos a relação dessas surpresas em relação aos log retornos de quatro ativos do mercado acionário brasileiro: WEGE3, CMIG4, ITSA4 e BRFS3.
Para entender como foi criado o gráfico e o modelo abaixo, faça parte do Clube AM, o repositório de códigos da Análise Macro, contendo exercícios semanais de R e Python.
No gráfico abaixo, verificamos os resultados dos coeficientes estimados de cada fator de supressa macroeconômica para cada surpresa.
_____________________
Quer saber mais?
Veja nossa trilha de cursos de Finanças Quantitativas
Referências
Chen, N. F., Roll, R., & Ross, S. A. (1986). Economic forces and the stock market. Journal of business, 383-403.
Tsay, Ruey S. Analysis of Financial Time Series 3rd Edition (2010)

