Introdução
Ao longo das últimas décadas, a pesquisa acadêmica tem se aprofundado na análise dos fatores que compõem as características das empresas, expandindo para o modelo de três fatores de Fama e French. Este modelo, além do fator de mercado, introduziu os fatores Small Minus Big (SMB) e High minus Low (HML), refletindo assim uma compreensão mais abrangente dos elementos que influenciam os retornos das ações.
Além desses fatores fundamentais, diversos outros têm sido identificados e estudados, variando conforme o mercado em questão. Exemplos incluem Winners Minus Losers (WML), também conhecido como Momentum, e Illiquid Minus Liquid (IML), evidenciando a complexidade e a variedade de fatores que os investidores consideram ao analisar e precificar ativos.
Regressão Lasso
O Lasso (least absolute shrinkage and selection operator) é um método de regressão linear que visa não apenas prever a variável de resposta, mas também realizar a seleção de variáveis de forma automática. Ao contrário de métodos tradicionais de regressão, o Lasso penaliza os coeficientes dos preditores, levando alguns deles a zero. Isso significa que o Lasso não apenas reduz o tamanho dos coeficientes, mas também realiza uma seleção eficiente de variáveis, eliminando aquelas que têm pouco impacto na predição do resultado. Essa propriedade torna o Lasso particularmente útil em situações em que se lida com um grande número de variáveis preditoras, permitindo a identificação das mais relevantes para o modelo.
O Estimador viesado do Lasso é obtido da seguinte forma:
![\[\hat\beta_\lambda^\text{Lasso} = \arg\min_\beta \left(Y - X\beta\right)'\left(Y - X\beta\right) + \lambda\sum\limits_{k=1}^K|\beta_k|.\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-dc2d7f95e7888e113a03b3578bbf375b_l3.png "Rendered by QuickLaTeX.com")
Aqui,  é hiperparâmetro que deve ser especificado previamente.
é hiperparâmetro que deve ser especificado previamente.
Dados
Em relação aos dados, é possível obter os fatores de risco do site da NEFIN, onde também é detalhado a metodologia de criação de cada fator. Para o retorno da ação PETR4, buscamos os dados através do Yahoo Finance.
Para obter o código e o tutorial deste exercício faça parte do Clube AM e receba toda semana os códigos em R/Python, vídeos, tutoriais e suporte completo para dúvidas.
Aprenda a coletar, processar e analisar dados do mercado financeiro no curso de Python para Investimentos.
Criando o Modelo
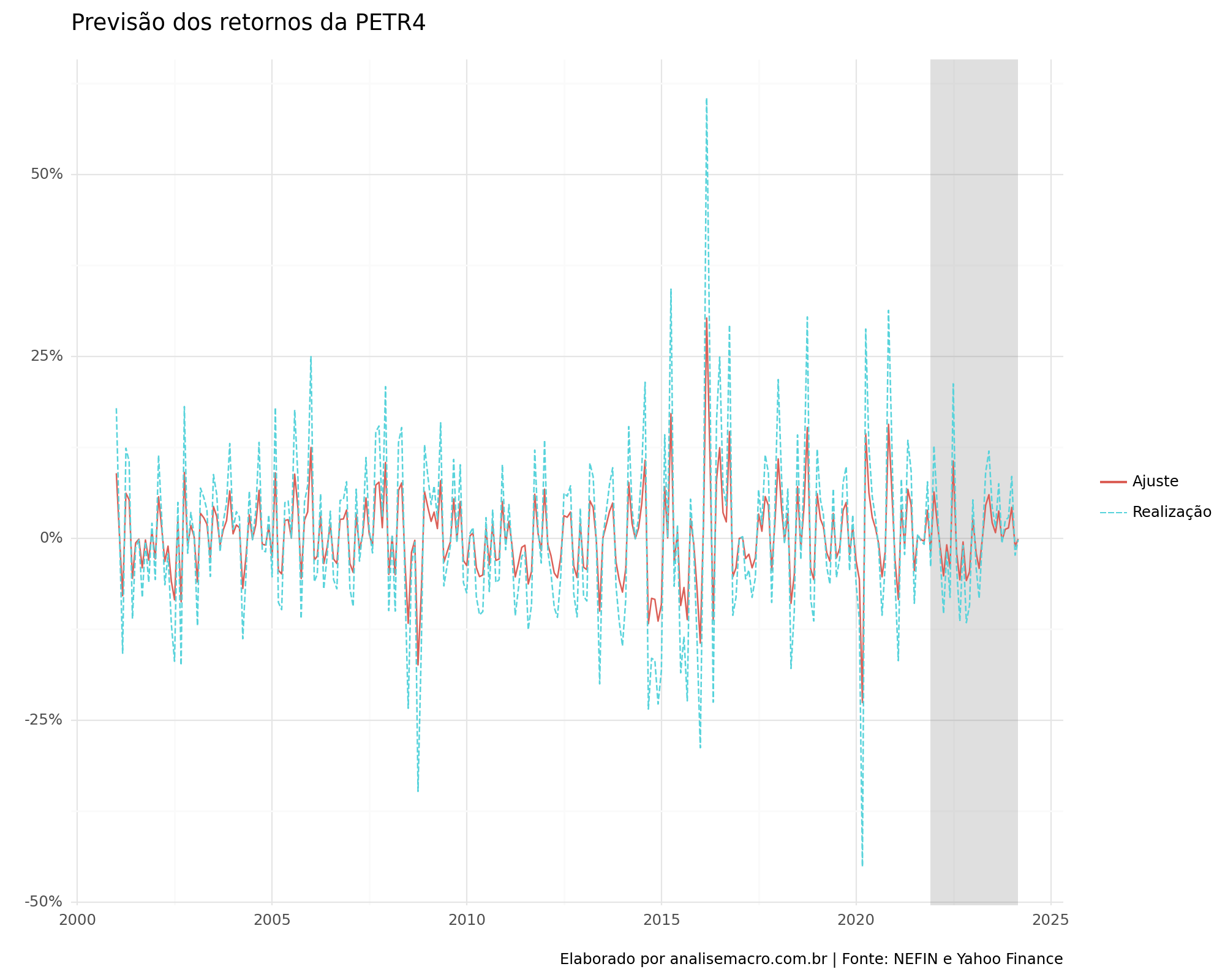
Após a coleta dos dados podemos criar o modelo utilizando a regressão Lasso. Faremos todo o procedimento dentro do workflow do sklearn. Escolhemos previamente um alpha de 0.007, sem nenhum motivo plausível, apenas para exemplificar a criação do modelo. A seguir, apresentamos o gráfico dos valores ajustados e os valores reais do retornos. No retângulo encontram-se os valores fora da amostra de estimação dos parâmetros do modelo.
Quer aprender mais?
Clique aqui para fazer seu cadastro no Boletim AM e baixar o código que produziu este exercício, além de receber novos exercícios com exemplos reais de análise de dados envolvendo as áreas de Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas diretamente em seu e-mail.

