No post de hoje vamos criar uma estratégia usando o retorno histórico de um ativo e suas defasagens para prever a direção dos seus retornos futuros, por meio de uma Regressão Linear utilizando o Python.
A Regressão Linear mensura a relação linear entre duas ou mais variáveis, podendo estimar o valor de uma variável dependente a partir de uma ou mais variáveis independente (também chamadas de Features).
Utilizaremos como variável independente o log retornos históricos do preço de uma ação e como Features os seus valores defasados. A relação entre esses valores possibilita obter a tendencia de queda ou alta do valores médios estimados dos retornos, sendo útil para a construção de estratégias de investimentos. Por exemplo, é possível criar uma hipótese de que após duas quedas, uma alta pode acontecer (reversão a média) ou ao contrário, de que outra queda possa acontecer (momentum ou tendência).
Quer saber mais sobre o uso do Python para a criação de estratégias de trading? Veja nosso curso de Python para investimentos.
Vamos criar um código para aplicar a técnica em um trade hipotético utilizando a ação ITUB4, do período de 01/01/2017 até 30/09/2022. Os dados são diários.
# Importa as bibliotecas
import numpy as np
import pandas as pd</pre>
from pandas_datareader import data as pdr
!pip install yfinance
import yfinance as yf
yf.pdr_override()
from matplotlib import pyplot as plt
plt.style.use('seaborn')
Algumas bibliotecas serão necessárias para coletar os preços da ação, realizar manipulações e cálculos e criar gráficos para representar os retornos.
Abaixo, a partir do ticker ITUB4.SA, coletamos os preços ajustados da ação por meio a função get_data_yahoo. Isso possibilita obter os dados direto do Yahoo Finance.
# Busca os preços das ações ## Define as ações assets = ['ITUB4.SA'] ## Define a data início start = '2017-01-01' end = '2022-09-30' # Busca os preços ajustados prices = pdr.get_data_yahoo(assets, start = start, end = end)[['Adj Close']]
A partir do objeto prices, contendo os preços ajustado da ação, calculamos os log retornos da ação por meio da equação  e salvamos na coluna "returns". Retiramos os dados faltantes e construímos a direção do retorno diário por meio da função sign, isto é, se houve retorno positivo ou negativo, +1 ou -1, respectivamente.
e salvamos na coluna "returns". Retiramos os dados faltantes e construímos a direção do retorno diário por meio da função sign, isto é, se houve retorno positivo ou negativo, +1 ou -1, respectivamente.
# Calcula os retornos e retira dados faltantes prices['returns'] = np.log(prices / prices.shift(1)) # Retira dados faltantes prices.dropna(inplace = True) # Cria os sinais da direção prices['direction'] = np.sign(prices['returns']).astype(int)
A tarefa agora é criar uma função para auxiliar na construção de lags dos retornos, isto é, defasar a coluna 'returns' em um período t - lags, possibilitando inserir quantas defasagens se queira, no caso, selecionamos 2 lags. O útil da função é que ela criará automaticamente o nome das colunas dos lags em um for loop.
# Cria função que defasa os retornos (lags)
lags = 2
def create_lags(data):
global cols
cols = []
for lag in range(1, lags + 1):
col = 'lag_{}'.format(lag)
data[col] = data['returns'].shift(lag)
cols.append(col)
# Cria os lags create_lags(prices) # Retira os dados faltantes prices.dropna(inplace=True)
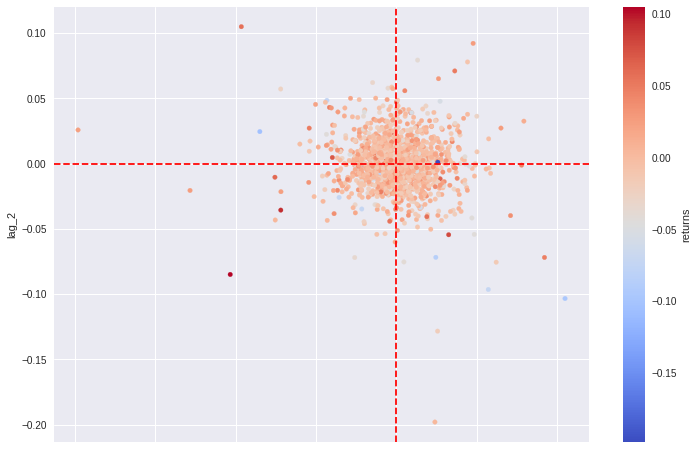
Temos agora um data frame com os preços, os retornos, o sinal do retorno no dia e duas colunas com defasagem do retorno. Vamos visualizar a relação entre três destas features por meio de um gráfico de dispersão, escolhendo o eixo x com o lag_1, eixo y com lag_2 e a cor representado pelo retorno.
# Visualiza a dispersão dos lags em conjunto com o retorno prices.plot.scatter(x='lag_1', y='lag_2', c='returns', cmap='coolwarm', figsize=(12, 8), colorbar=True) plt.axvline(0, c='r', ls='--') plt.axhline(0, c='r', ls='--')
Vamos construir a previsão dos retornos por meio dos lags e da direção com uma Regressão Linear. Vamos utilizar o ambiente do sklearn, estimando separadamente os retornos e a direção, e prevendo os resultados respectivamente. Veja que a partir dos resultados da regressão, escolhemos a posição vendida ou comprado por meio da direção das duas previsões, a criação dessas posições é necessária para construir o backtest do trading.
# Cria a regressão para prever a direção de mercado from sklearn.linear_model import LinearRegression model = LinearRegression() ## Fita com os lags prices['pos_ols_1'] = model.fit(prices[cols], prices['returns']).predict(prices[cols]) ## Fita com a direção prices['pos_ols_2'] = model.fit(prices[cols], prices['direction']).predict(prices[cols]) # Cria as posições da direção da regressão prices[['pos_ols_1', 'pos_ols_2']] = np.where(prices[['pos_ols_1', 'pos_ols_2']] > 0, 1, -1)
Para o backtest, supomos que não há custos operacionais e não realizamos nenhuma diferenciação de treino e teste, apenas calculamos os retornos acumulados das estratégias de acordo com as posições obtidas.
# Cria o backtest ## Backtest da regressão com os valores defasasdos prices['strat_ols_1'] = prices['pos_ols_1'] * prices['returns'] ## Backtest da regressão com as posições prices['strat_ols_2'] = prices['pos_ols_2'] * prices['returns'] ## Acumula prices[['returns', 'strat_ols_1', 'strat_ols_2']].sum().apply(np.exp)
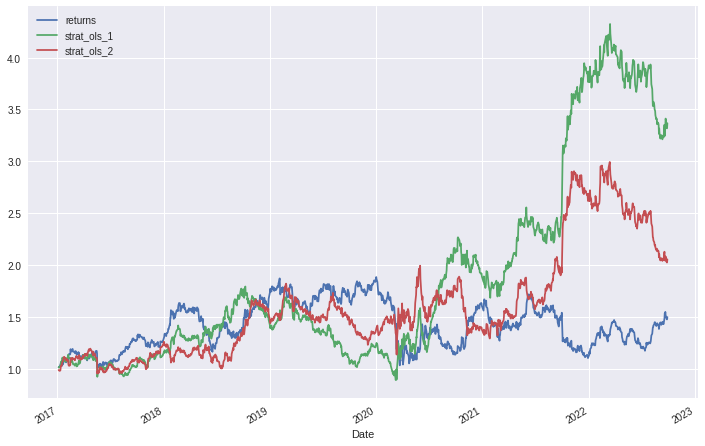
Com os retornos acumulados, podemos comparar os resultado das estratégias entre si e com os retornos acumulados do ativo.
# Acumula e plota o resultado da estratégia prices[['returns', 'strat_ols_1', 'strat_ols_2']].cumsum().apply(np.exp).plot(figsize=(12, 8));
______________________________________
Quer saber mais?
Veja nosso curso de Python para Investimentos.
Referências
Hilpisch, Yves. Python for Finance: Analyze big financial data. O'Reilly Media, Inc., 2014.

