Introdução
A gestão de portfólio e a análise de risco são práticas essenciais e rotineiras para investidores. Mostramos neste artigo a como avaliar a relação de Risco x Retorno utilizando o Python.
Contudo, além de muitas vezes estas ferramentas serem engessadas – dificultado a customização das análises – elas também são pagas – o que inviabiliza, por exemplo o uso destes instrumentos por pequenos investidores. O Python aparece como uma alternativa que alia a vantagem da gratuidade a um grande nível de possibilidade de customização. Estas características também são vantajosas para pesquisadores que desejam fazer trabalhos acadêmicos.
Ao final você será capaz de (i) encontrar carteiras dentro da fronteira eficiente, dadas algumas restrições que você escolha; (ii) analisar a performance desta carteira se comparada a renda fixa ou a algum benchmark; (iii) gerir o risco desta carteira.
Vamos capturar os preços de 4 ações e da Ibovespa para a analise.
import yfinance as yf import pandas as pd import numpy as np from plotnine import * from matplotlib import pyplot as plt import seaborn as sns sns.set()
tickers = ['^BVSP', 'BBDC4.SA', 'ITSA4.SA', 'GGBR4.SA', 'WEGE3.SA'] precos = yf.download(tickers, start = '2014-01-01', end = '2023-07-01', interval = '1mo')['Adj Close']
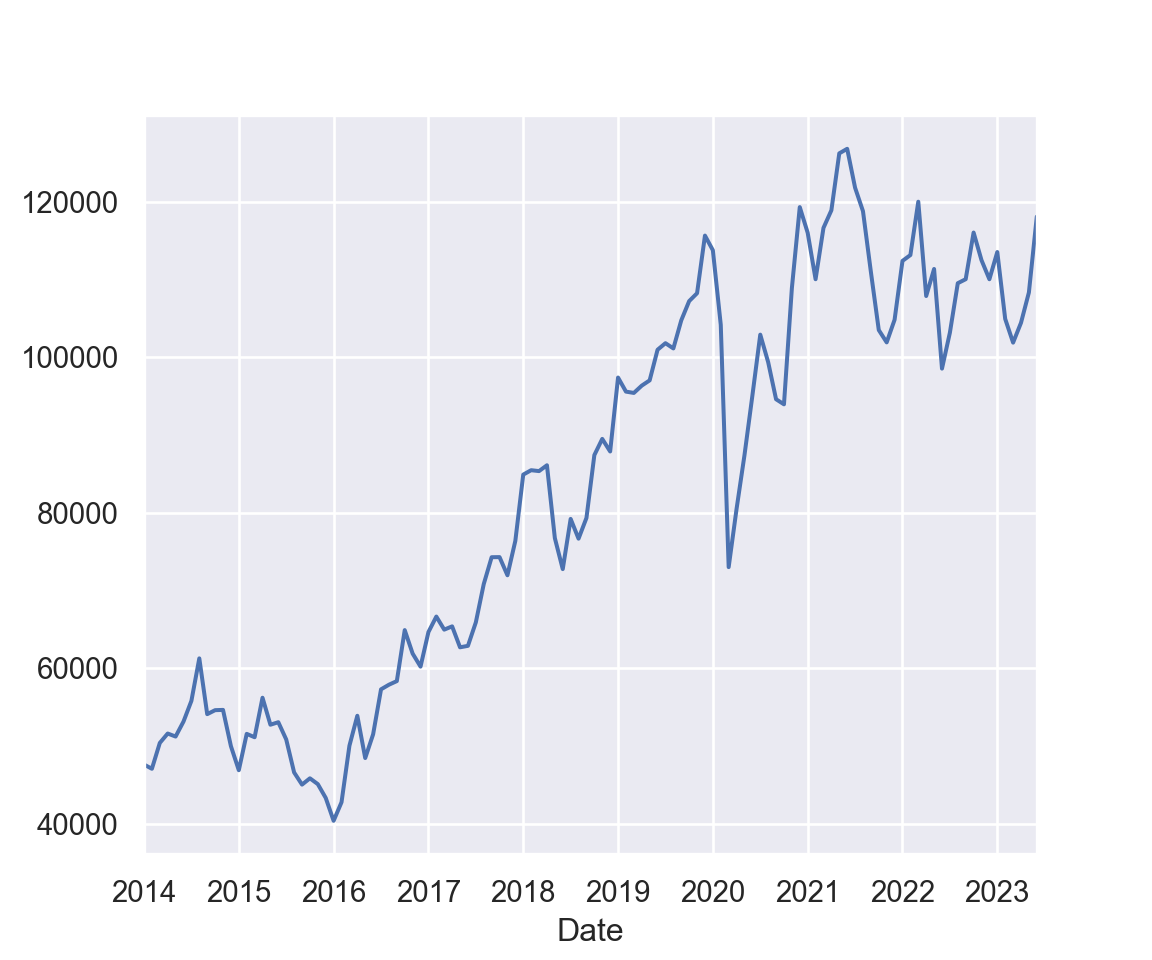
Vemos que a série do Ibovespa é bastante errática e, para este período, não parece ter uma tendência bem definida. Além disso, a série nesta forma não indica o quanto o Ibovespa está gerando de retorno diariamente, e é isto que importa para o gestor de carteiras. Em resumo, a série de nível de pontos (ou preço, para ações) não é muito informativa para o gestor de portfólio ou analista de risco. Vamos, então, transformar esta série em retorno para poder trabalhar os dados da forma melhor. Mas antes vamos definir retorno.
precos['^BVSP'].plot();
O retorno de um ativo financeiro é a variação percentual de seu preço entre dois períodos de tempo, no nosso caso dias. Existem duas formas de calcular o retorno. A primeira é discretamente:
![\[R_{t,disc}=\frac{P_{t}-P_{t-1}}{P_{t-1}}= \Delta P_t\%\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-48d801b4b6085999a2715f460a8c92d3_l3.png "Rendered by QuickLaTeX.com")
Onde o retorno de um período (dia),  , é a diferença entre o preço
, é a diferença entre o preço  no período
no período  (por exemplo, hoje) e o preço no período
(por exemplo, hoje) e o preço no período  (por
(por
exemplo, ontem) dividido pelo preço em . Isto nos dá a variação percentual  do ativo.
do ativo.
A segunda maneira de calcular os retornos -- que é a que vamos utilizar --, é a forma contínua, também chamada de log-retorno. Esta é a maneira mais utilizada em finanças práticas, por trazer algumas conveniências técnicas.
![\[R_{t,cont} = ln\left(\frac{P_t}{P_{t-1}}\right)=ln(P_t)-ln(P_{t-1})\approx \Delta P_t\%\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-19b7d195a76a64446b80e2c7e8c52c25_l3.png "Rendered by QuickLaTeX.com")
Então o log-retorno,  , é igual ao logaritimo natural do preço de hoje dividido pelo preço de ontem. Pelas propriedade do log natural, isto é igual a diferença dos logs dos preços, que é aproximadamente igual aos retornos discretos.
, é igual ao logaritimo natural do preço de hoje dividido pelo preço de ontem. Pelas propriedade do log natural, isto é igual a diferença dos logs dos preços, que é aproximadamente igual aos retornos discretos.
Agora vamos, de fato, calcular os retornos.
retornos_simples['^BVSP'] retornos_log['^BVSP']
# Criar histograma fig, ax = plt.subplots(1,1) for p in retornos_log.columns: retornos_log[p].plot(kind = 'density') plt.legend() fig.show();
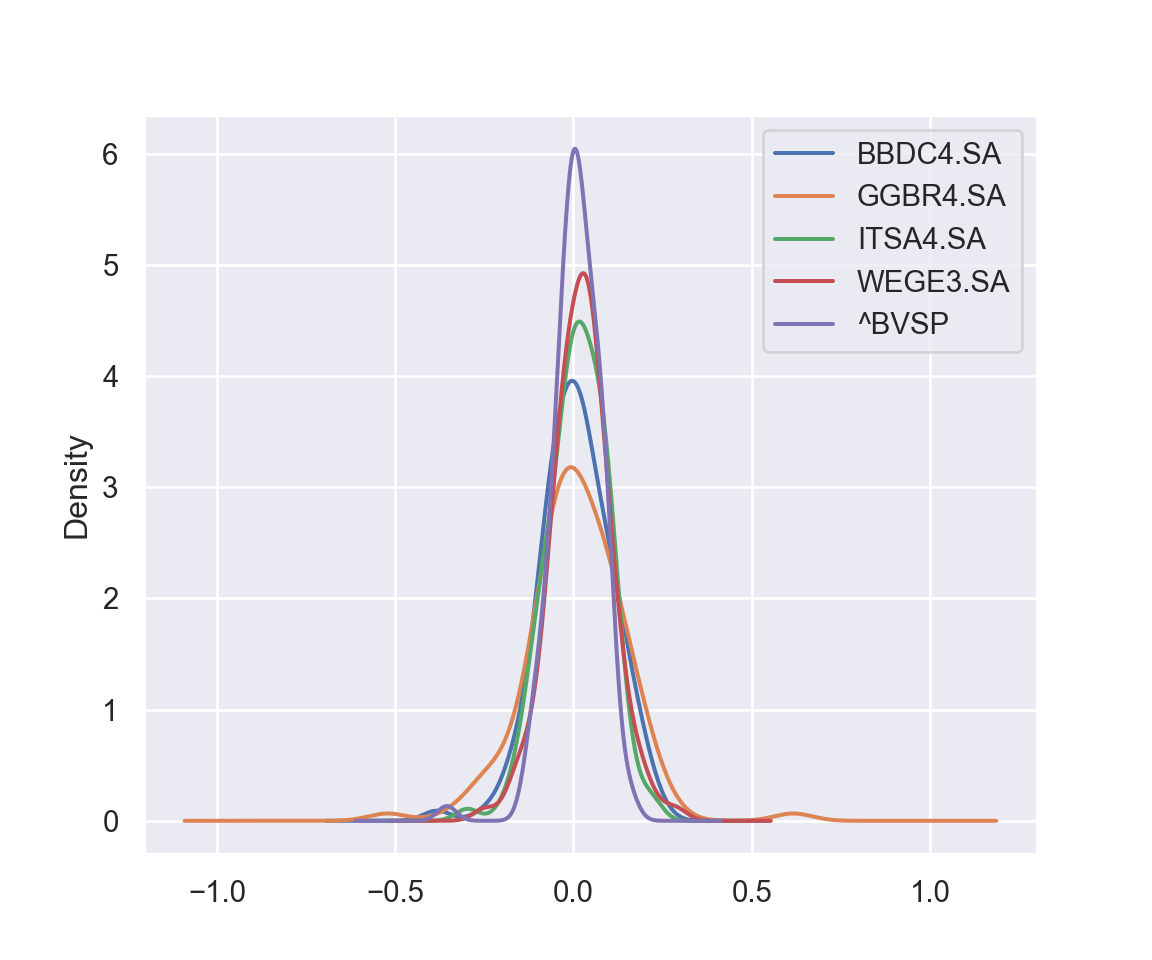
Transformamos a série de nível para retornos.
Agora é possível analisar as estatísticas descritivas para checarmos as características dos retornos do Ibovespa. Em qualquer exercício empírico é interessante estudar as estatísticas básicas da variável com a qual você vai trabalhar. Para a gestão de portfólio, é importante analisar a média, variância e desvio-padrão do ativo (veremos mais adiante o porquê). Para outros trabalhos em finanças, principalmente na área de risco, pode ser muito importante estudar a assimetria (skewness) e a curtose da série também.
Para analisar as principais estatísticas, fazemos o uso do código abaixo:
from scipy.stats import kurtosis, skew # Calcula estatísticas descritivas desc_stats = retornos_log.describe() # Calcula a assimetria e a curtose para cada coluna skewness = retornos_log.apply(skew) kurt = retornos_log.apply(kurtosis, fisher = False) # Adiciona as métricas de assimetria e curtose ao DataFrame de estatísticas descritivas desc_stats.loc['skewness'] = skewness desc_stats.loc['kurtosis'] = kurt desc_stats
| BBDC4.SA | GGBR4.SA | ITSA4.SA | WEGE3.SA | ^BVSP | |
|---|---|---|---|---|---|
| count | 113.000000 | 113.000000 | 113.000000 | 113.000000 | 113.000000 |
| mean | 0.008081 | 0.007260 | 0.010452 | 0.021250 | 0.008033 |
| std | 0.099825 | 0.138298 | 0.084569 | 0.083522 | 0.068500 |
| min | -0.382640 | -0.521515 | -0.297199 | -0.247675 | -0.355310 |
| 25% | -0.057746 | -0.060950 | -0.038860 | -0.030257 | -0.029497 |
| 50% | 0.008238 | 0.001875 | 0.010431 | 0.024981 | 0.008016 |
| 75% | 0.081117 | 0.089704 | 0.067764 | 0.068778 | 0.058242 |
| max | 0.238493 | 0.616639 | 0.219500 | 0.286519 | 0.156724 |
| skewness | -0.417216 | 0.081657 | -0.423073 | -0.011801 | -1.287475 |
| kurtosis | 4.206233 | 6.866079 | 3.752788 | 3.994447 | 8.614712 |
Vemos que em 113 observações, o mínimo e o máximo registrados do Ibovespa foram de -0.355310 e 0.156724 e a média foi de 0.008033.
Também é possível perceber que existe assimetria (skewness) negativa de -1.287475 e que a série é leptocurtica, pois há uma curtose em excesso de 8.614712.
A curtose de uma distribuição Normal é de 3 (para a definição de Pearson, para a definição de Fisher, a curtose de uma normal é 0).
Isto quer dizer que, existem mais retornos negativos do que positivos (assimetria negativa) e que eventos extremos são mais comuns do que o normal (curtose em excesso).
Estas duas últimas características são muito comuns em séries financeiras e indicam uma possível não-Normalidade dos dados. Esta constatação é importante especialmente para análise de risco avançada. Porém, dado o caráter introdutório do curso, quando necessário, vamos adotar a hipótese simplificadora de que os retornos são Normais.
Boa parte do mercado ainda trabalha desta maneira e até mesmo a literatura indica que em alguns casos a hipótese de normalidade não é tão forte assim.
Retorno e Risco
Em uma descrição livre, é possível separar a gestão de portfólio em quatro grandes processos dinâmicos:
- escolha dos ativos que o investidor deseja ter em carteira (tipicamente escolhido por técnicas de análise macro, fundamentalista, técnica ou quantitiva);
- otimização, isto é, a escolha da melhor carteira – o quanto investir em cada ativo (para maximizar a razão retorno/risco);
- análise da performance da carteira;
- gestão do risco (tipicamente modelagem e previsão da probabilidade de perda financeira).
Não abordaremos a primeira parte do processo de gestão. Vamos assumir que após algum processo de análise, o gestor selecionou as ações do Bradesco (BBDC4), Itaúsa (ITSA4), Gerdau (GGBR4) e Wege (WEGE4). O foco será no processo de otimização, análise de performance e gestão do risco.
Mas ainda antes disso vamos definir alguns conceitos importantes para a gestão de carteiras.
Retorno e Risco de Ativos Individuais
No contexto de gestão de carteiras, os ativos individuais são caracterizados por duas dimensões: retorno e risco. O retorno, neste curso, é tratado como a média amostral dos retornos de um ativo durante um certo período de tempo.
Formalmente:
![\[\bar{R}_{i} = \frac{\sum_{t=1}^T (R_{it})}{T}\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-d0407c3353a92c145f8215397e03a732_l3.png "Rendered by QuickLaTeX.com")
Então, o retorno esperado do ativo  ,
,  é igual a soma de todos os retornos do ativo
é igual a soma de todos os retornos do ativo  dividido pelo número de observações,
dividido pelo número de observações,  .
.
Tomemos o Ibovespa como exemplo prático, novamente. Para calcular sua média amostral, isto é, o retorno esperado basta utilizarmos o método mean.
retornos_log.mean()
BBDC4.SA 0.008081
GGBR4.SA 0.007260
ITSA4.SA 0.010452
WEGE3.SA 0.021250
^BVSP 0.008033
dtype: float64O risco, nesta seção, é tido como a variância amostral ou o desvio padrão da série de retorno do ativo. Formalmente:
![\[\sigma_i^2= \frac{\sum_{t=1}^T(R_{it}-\bar{R}_i)^2}{T-1}\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-80f8e185598e3ae5f5322d1529dd1747_l3.png "Rendered by QuickLaTeX.com")
Onde,  é a variância do ativo , que é a soma das diferenças ao quadrado.
é a variância do ativo , que é a soma das diferenças ao quadrado.
O valor da variância, contudo, não é facilmente interpretado. Por isso, em exercícios práticos é muito comum usarmos o desvio-padrão como a métrica de risco.
![\[\sigma_i= \sqrt{\frac{\sum_{t=1}^T(R_{it}-\bar{R}_i)^2}{T-1}}\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-efd4d4fe0a13ad1cdbe30ab3fbc84554_l3.png "Rendered by QuickLaTeX.com")
O desvio-padrão  é simplesmente a raíz quadrada da variância. A vantagem desta métrica é que ela pode ser intepretada em termos deporcentagem. Assim, um desvio-padrão de 20%, por exemplo, significa que o ativo varia normalmente 20% em torno do retorno esperado.
é simplesmente a raíz quadrada da variância. A vantagem desta métrica é que ela pode ser intepretada em termos deporcentagem. Assim, um desvio-padrão de 20%, por exemplo, significa que o ativo varia normalmente 20% em torno do retorno esperado.
Em termos um pouco mais formais, assumindo uma distribuição Normal, há uma probabilidade de 68\% de os retornos do ativo variarem 20\% em torno da média. Ou seja, com probabilidade de 68\% os retornos estarão na faixa de  e
e 
No caso dos retornos:
# cálculo da variância retornos_log.var(ddof = 1)
BBDC4.SA 0.009965
GGBR4.SA 0.019126
ITSA4.SA 0.007152
WEGE3.SA 0.006976
^BVSP 0.004692
dtype: float64# cálculo do desvio-padrão retornos_log.std(ddof = 1)
BBDC4.SA 0.099825
GGBR4.SA 0.138298
ITSA4.SA 0.084569
WEGE3.SA 0.083522
^BVSP 0.068500
dtype: float64Retorno e Risco de Carteiras e o Papel da Diversificação
Uma carteira combina um conjunto de ativos, com diferentes pesos. Considerando dois ativos A e B, podemos, por exemplo, decidir investir 50% em A e 50% em B. Quando isto acontece criamos um “novo” ativo, a carteira, que terá retorno e risco diferentes do investimento individual em cada um dos ativos – inclusive na forma de calcular. Além disso, agora é necessário considerar outra dimensão: a covariância ou correlação. Estas medem o quanto a variação de um ativo depende do outro, portanto estas medidas podem impactar no risco da carteira.
O principal motivo para investir em mais de um ativo é o conceito de diversificação. Por que a diversificação é importante? A resposta normalmente é algo como “porque dilui o risco”. Contudo, esta mera definição não é clara.
Vamos escrevê-la em termos matemáticos. Para isso precisamos definir os conceitos de retorno e risco do portfólio (e não dos ativos individuais).
![\[R_p=\sum_{i=1}^I(w_{i}{R}_i)\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-86dd0038f3cc8332c634e6dde5f25bcf_l3.png "Rendered by QuickLaTeX.com")
em que  é o peso do ativo no portfólio, podendo ser calculado como:
é o peso do ativo no portfólio, podendo ser calculado como:
![\[w=\frac{valor\;da\;ação}{total\;investido\;no\;portfólio}\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-a324d830fbba5d78263ed7394d1f8aa7_l3.png "Rendered by QuickLaTeX.com")
A fórmula geral do retorno esperado de um portfólio é
![\[\bar{R}_p=\sum_{i=1}^I(w_{i}\bar{R}_i)\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-a1efa85ecc5b2fb5cd19f48bd40cc16f_l3.png "Rendered by QuickLaTeX.com")
onde,
- é o peso do ativo e;
- é o retorno esperado (média amostral) do ativo .
Ou de forma mais simples (para o caso de dois ativos):
![\[\bar{R}_p=(w_A\bar{R}_A) + (w_B\bar{R}_B)\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-80eccc67e9f888b5c20941fb20def767_l3.png "Rendered by QuickLaTeX.com")
Ou seja, o retorno esperado de um portfólio é apenas uma média ponderada dos retornos esperados (médias amostrais) de cada ativo. Este é o primeiro conceito importante para a gestão de carteiras: o quanto se espera ganhar, ou seja, o retorno esperado quando se combinam dois ou mais ativos.
Um exemplo: suponha que o ativo A tenha retorno médio de 10% e o B de 20%.
Suponha ainda que você investirá 40% em A e 60% em B. Então,
Ou seja, o retorno esperado de um portfólio é apenas uma média ponderada dos retornos esperados (médias amostrais) de cada ativo. Este é o primeiro conceito importante para a gestão de carteiras: o quanto se espera ganhar, ou seja, o retorno esperado quando se combinam dois ou mais ativos.
Um exemplo: suponha que o ativo A tenha retorno médio de 10% e o B de 20%.
Suponha ainda que você investirá 40% em A e 60% em B. Então
r_p = (0.10*0.4)+(0.2*0.60) r_p
0.16
Sendo assim, se o retorno dos ativos combinados é menor do que o do ativo maior (esse sempre é o caso, pois a fórmula é uma média ponderada – uma combinação convexa –, então o resultado sempre será menor ou igual do que do ativo de maior retorno) não seria sempre melhor investir no ativo de maior retorno? A resposta, na grande maioria dos casos é não.
Isto porque é necessário analisar o segundo conceito importante da gestão de carteiras, o risco. Pois, se o risco do ativo B for muito maior do que o ativo A e você investir tudo nele, você pode perder muito dinheiro. Enquanto que se você combinar um pouco do ativo A com o B, seu retorno tende a ser menor, mas seu risco também pode diminuir.
Vamos ver isto de uma maneira mais formal, analisando o desvio-padrão de um portfólio. A fórmula geral para ele é:
![\[\sigma_P=\sqrt{\sum_{j=1}^N(w_j^2 \sigma_j^2)+\sum_{j=1}^N\sum_{\substack {k=1 \\ k \neq j}}^N(w_j w_k \sigma_{jk})}\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-cbe042737fbab09dffa4d1bd7ce6f104_l3.png "Rendered by QuickLaTeX.com")
No caso de dois ativos:
![\[\sigma_P=\sqrt{w_A^2\sigma_A^2+w_B^2\sigma_B^2+2w_Aw_B\sigma_{AB}}\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-b6118a797215168fc2b60ae2486a2fce_l3.png "Rendered by QuickLaTeX.com")
onde,
-  é o desvio-padrão do portfólio;
é o desvio-padrão do portfólio;
- é a desvio-padrão do ativo e;
-  é a covariância entre os ativos
é a covariância entre os ativos  e
e  .
.
O desvio padrão representa o conceito de risco. Ou seja, temos um retorno
esperado de  , mas existe uma incerteza relacionada a este retorno, representado pela variância/desvio-padrão.
, mas existe uma incerteza relacionada a este retorno, representado pela variância/desvio-padrão.
Repare que o desvio-padrão não é uma simples média ponderada. O terceiro termo inclui a covariância, que pode impactar diretamente sobre o risco da carteira.
A covariância é calculada como:
![\[\sigma_{AB}=\frac{\sum_{t=1}^T[R_{At}-\bar{R}_A][R_{Bt}-\bar{R}_B]}{T-1}\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-648aa332a2ad3fe839aada53760f7362_l3.png "Rendered by QuickLaTeX.com")
A covariância é o terceiro conceito importante na gestão de carteiras e pode ser visto como o risco conjunto entre dois ativos. Uma simples inspeção na
fórmula da variância do portfólio revela que uma covariância negativa pode causar a redução do risco ao combinarmos dois (ou mais) ativos.
O conceito de covariância pode ser melhor entendido através de outra estatística (relação análoga a da variância/desvio-padrão), a correlação. Sua fórmula é:
![\[\rho_{AB}=\frac{\sigma_{AB}}{\sigma_A\sigma_B}\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-a127ff04dff50459530030e0e8d2a81c_l3.png "Rendered by QuickLaTeX.com")
A covariância, e mais diretamente a correlação, medem o quanto um ativo se movimenta em conjunto com outro. No caso da correlação esta medida é em forma de percentual, o que facilita a análise. Por exemplo, se a correlação entre A e B é de 0.80, isto que dizer que eles "andam juntos" 80\% do tempo.
Se o gestor investe, por exemplo, em dois ativos, A e B, com alta correlação positiva e A cair, a tendência será B cair numa proporção próxima à queda de
A, levando a uma queda geral do portfólio. Se a correlação entre os ativos for pequena ou negativa, a queda de A tende a ser compensada pela menor queda ou até mesmo pela alta de B.
Portanto, a diversificação é tão mais interessante quanto mais negativa for a covariância (ou correlação) entre os ativos.
Notação Matricial do Cálculo de Portfólio
Para facilitar o cálculo, podemos usar a notação matricial (para dois ativos), como segue:
![\[\sigma^2_{P} = \begin{bmatrix}{w_1 w_2}\end{bmatrix} \begin{bmatrix}{\sigma^2_1} &{\sigma_{1,2}} \\[0.3em] {\sigma_{2,1}} & {\sigma^2_2}\end{bmatrix} \begin{bmatrix}{w_1} \\{w_2}\end{bmatrix}\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-7b8bb717579456d0a3ce827335891fdc_l3.png "Rendered by QuickLaTeX.com")
A partir dessa notação, podemos entender facilmente como realizar o cálculo no Python.
Vejamos como calcular o Retorno Esperado e o Desvio Padrão do Portfólio no Python, considerando pesos iguais.
# Número de ativos
num_ativos = len(retornos_log.columns)
# Calcula pesos iguais
peso_por_ativo = 1.0 / num_ativos
pesos = [peso_por_ativo] * num_ativos
# Calcula o retorno esperado do portfólio.
retorno_esperado_portfolio = np.sum(retornos_log.mean() * pesos)
# Calcula o desvio padrão do portfólio.
cov_matrix = retornos_log.cov() # matriz de covariância
portfolio_variance = np.dot(pesos, np.dot(cov_matrix, pesos)) # variância do Portfólio
portfolio_stddev = np.sqrt(portfolio_variance) # Desvio Padrão
# Verifica os resultados
print("Retorno Esperado do Portfólio:", retorno_esperado_portfolio)
print("Desvio Padrão do Portfólio:", portfolio_stddev)
Retorno Esperado do Portfólio: 0.011015373689934414
Desvio Padrão do Portfólio: 0.07555287751010976Relação de Risco x Retorno
Supomos que investidores são racionais e portanto tendem a tomar a melhor decisão em relação a escolha dos investimento. Para tanto, dizemos que dado uma curva de indiferença, que projeta a relação do retorno esperado do ativo em relação ao retorno, tem-se que o critério de decisão do investidor será para a seleção do ativo que possui o maior retorno e o menor risco possível.
Para um mesmo nível de risco, um investidor racional seleciona o ativo de maior valor esperado. Ao contrário, quando há dois ou mais ativos que apresentam o mesmo retorno esperado, o investidor racional escolhe sempre aquele de menor risco.
Princípio da Dominância
Para que o investidor obtenha um retorno maior de sua carteira, ele deve assumir um nível mais alto de risco, portanto, há uma relação direta e proporcional entre risco e retorno. Quanto maior o risco de um ativo, maior o prêmio pelo risco pago e para um determinado nível de risco assumido, o investidor deseja auferir o maior retorno possível
Com esses conceitos em mente, podemos, através do cálculo do retornos esperado e do risco, escolher o ativo que representa a melhor escolha dessa decisão.
Vejamos no gráfico de dispersão abaixo a relação para os ativos e o portfólio criado.
# calcula o retorno esperado
re = retornos_log.mean() * 100
# calcula o risco
sigma = retornos_log.std(ddof = 1) * 100
# Cria df dos ativos
risk_return_ativos = pd.DataFrame({'ativos' : re.index,
'retorno_esperado' : re.values,
'risco' : sigma.values})
# Cria df do portfólio
risk_return_portf = pd.DataFrame({'ativos' : ['Portfólio'],
'retorno_esperado' : retorno_esperado_portfolio * 100,
'risco' : portfolio_stddev * 100})
# Junta os df
dados = pd.concat([risk_return_ativos, risk_return_portf])
# Cria o gráfico de dispersão
(ggplot(dados, aes(x = 'risco', y = 'retorno_esperado', colour = 'ativos'))
+ geom_point(size = 4)
+ labs(title = "Retorno x Risco: ativos selecionados",
x = "Risco (Desvio Padrão)",
y = "Retorno Esperado")
)

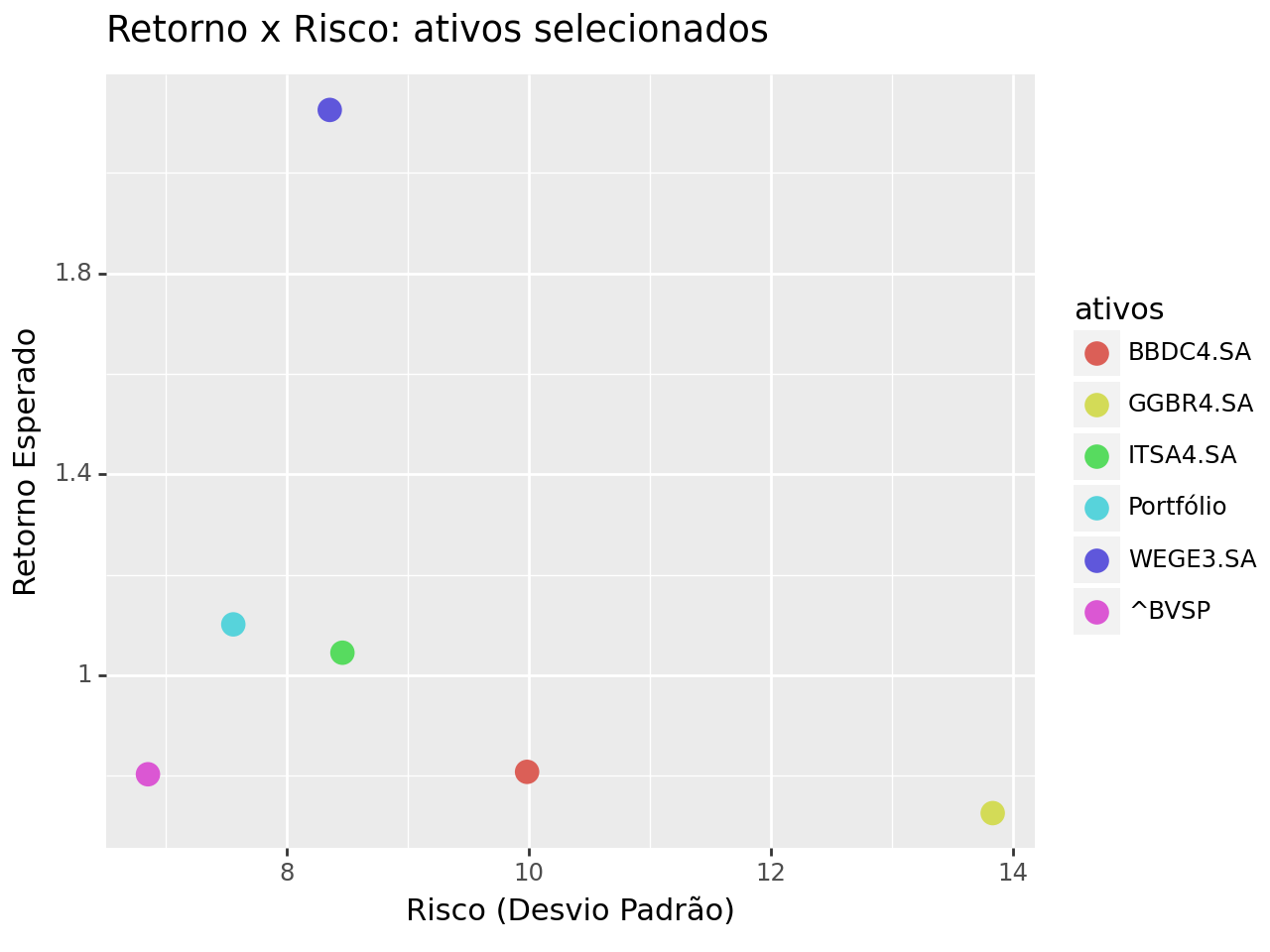
Exemplo Prático
No gráfico acima, criamos um portfólio com pesos iguais, e comparamos o seu retorno esperado e risco com os dos ativos. A ideia básica é que o portfólio tenha o menor risco possível para um dado retorno, visto o efeito da diversificação (isso se aplica para o Ibovespa).
Para melhor entendimento, podemos comparar diferentes portfólios do mesmos ativos, contudo, criando diferentes combinações de pesos. Dessa forma, podemos avaliar quais as possibilidade de retorno e risco que temos, e dessa forma, poder escolher aqueles que melhor representam o princípio da dominância.
# calcula o retorno esperado mu = retornos_log.mean() # calcula a matriz de covariância cov_matrix = retornos_log.cov() # número de portfólio (número de pesos aleatórios gerados) num_portfolios = 25000 # cria um array para manter os resultados results = np.zeros((3,num_portfolios)) # cria o for loop para as simulações for i in range(num_portfolios): # seleciona pesos aleatórios para os portfólios weights = np.random.random(5) # verifica se os portfólios somam 1 weights /= np.sum(weights) # calcula os retornos esperado do portfólio portfolio_return = np.sum(mu * weights) # calcula a volatilidade portfolio_std_dev = np.sqrt(np.dot(weights.T,np.dot(cov_matrix, weights))) # armazena os valores no array results[0,i] = portfolio_return results[1,i] = portfolio_std_dev # Calcula o Sharpe Ratio (retorno / volatilidade) - sem taxa livre de risco results[2,i] = results[0,i] / results[1,i] # Converte o resultado para um df results_frame = pd.DataFrame(results.T, columns = ['Retorno Esperado','Desvio Padrão','Sharpe']) # Cria o gráfico de dispersão com barra para o Sharpe (ggplot(results_frame, aes(x = 'Desvio Padrão', y = 'Retorno Esperado', color = 'Sharpe')) + geom_point() + labs(title = "Simulação de Portfólios para os Ativos Selecionados") )
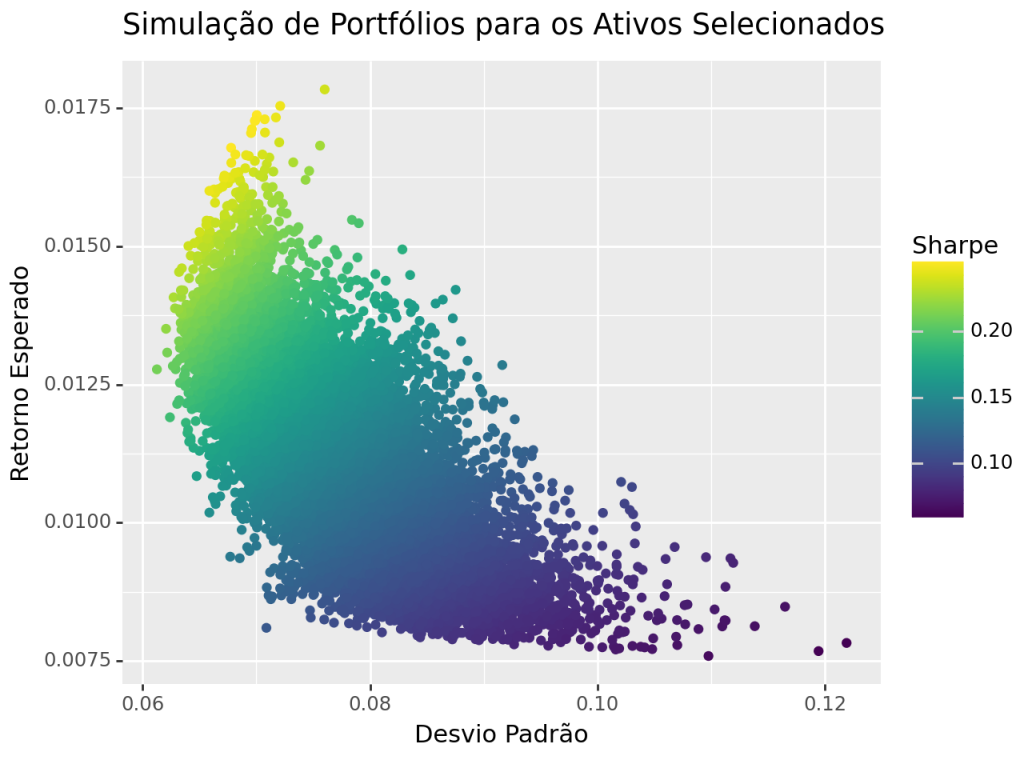 Vemos que as melhores combinações de portfólio se encontram na parte à esquerda do gráfico, onde há menor risco, para dado nível de retorno. É nesse local que temos um maior índice de Sharpe (uma medida de revela a relação de risco x retorno), e portanto, podemos saber que nesse lado se encontram as combinações em que os ativos possui menor correlação possível.
Vemos que as melhores combinações de portfólio se encontram na parte à esquerda do gráfico, onde há menor risco, para dado nível de retorno. É nesse local que temos um maior índice de Sharpe (uma medida de revela a relação de risco x retorno), e portanto, podemos saber que nesse lado se encontram as combinações em que os ativos possui menor correlação possível.
Quer aprender mais?
- Cadastre-se gratuitamente aqui no Boletim AM e receba toda terça-feira pela manhã nossa newsletter com um compilado dos nossos exercícios com exemplos reais de análise de dados envolvendo as áreas de Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas;
- Quer ter acesso aos códigos, vídeos e scripts de R/Python desse exercício? Vire membro do Clube AM aqui e tenha acesso à nossa Comunidade de Análise de Dados;
- Quer aprender a programar em R ou Python com Cursos Aplicados e diretos ao ponto em Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas? Veja nossos Cursos aqui.


