“‘Aprender com os dados’ é uma definição fundamental dos modelos de aprendizado de máquina. Mas e se pudéssemos aplicar esse conceito às estratégias de investimento? Aqui, vamos explorar exatamente isso. Vamos introduzir um exercício de Python que utiliza Deep Neural Networks (DNNs) para prever os movimentos do mercado financeiro, com base em valores históricos de log-retornos como dados de entrada.
As DNNs são inspiradas no funcionamento do cérebro humano e são compostas por diversas camadas, incluindo uma camada de entrada, uma camada de saída e várias camadas ocultas. Essa arquitetura permite que as redes neurais aprendam relações complexas e tenham um desempenho superior em uma variedade de problemas.
Exploraremos o poder das Deep Neural Networks (DNNs) para prever a direção do movimento do mercado com base em dados históricos de log-retornos. Ao utilizar os valores defasados da série temporal e transformá-los em outras features, buscamos criar um modelo capaz de identificar padrões e tendências no mercado financeiro.
Neste contexto, abordaremos o backtesting vetorizado de estratégias de algo-trading, onde o termo “algo-trading” se refere a estratégias de negociação financeira automatizadas. Essas estratégias são baseadas em algoritmos projetados para tomar decisões de compra, venda ou neutras em instrumentos financeiros, sem intervenção humanas.
Dados
Para fins de aprendizado, vamos buscar dados da empresa VALE3 no período de jan/2010 até dez/2022, em intervalo diário. Filtramos o preço de fechamento, e calculamos os log-retornos da série. Em seguida, criamos as defasagens do log-retorno.
A ideia básica por trás do uso de retornos logarítmicos defasados como features é que eles podem ser informativos na previsão de retornos futuros. Por exemplo, alguém pode hipotetizar que após dois movimentos descendentes, um movimento ascendente é mais provável (“reversão à média”), ou, ao contrário, que outro movimento descendente é mais provável (“momentum” ou “tendência”).
Podemos também transformar as defasagens de valor contínuo em features binárias e avaliar a probabilidade de um movimento ascendente e um movimento descendente, respectivamente, a partir das observações históricas desses movimentos.
Para obter o código e o tutorial deste exercício faça parte do Clube AM e receba toda semana os códigos em R/Python, vídeos, tutoriais e suporte completo para dúvidas.
Aprenda a coletar, processar e analisar dados do mercado financeiro no curso de Python para Investimentos.
Treinamento do Modelo
O algoritmo é treinado e testado em dados de features binárias ou contínuas. A ideia é que os padrões de valores das features permitam uma previsão dos movimentos futuros do mercado com uma taxa de acerto melhor do que 50%. Implicitamente, presume-se que o poder preditivo dos padrões persista ao longo do tempo. Nesse sentido, não deveria fazer (muita) diferença em qual parte dos dados um algoritmo é treinado e em qual parte dos dados ele é testado - implicando que se pode quebrar a sequência temporal dos dados para treinamento e teste (sempre haverá a possibilidade de implementação de separação sequencial e o uso de cross-validation).
Uma maneira típica de fazer isso é dividir aleatoriamente os dados em treino e teste para testar o desempenho dos algoritmos fora da amostra, tentando emular a realidade, onde um algoritmo durante a negociação se depara continuamente com novos dados.
Aplicamos a separação dos conjuntos de dados aleatoriamente e aplicamos o modelo DNN. Isso evita que tenhamos overfitting na nossa estratégia.
Código
MLPClassifier(alpha=1e-05, hidden_layer_sizes=[500, 500, 500], max_iter=500,
random_state=1, solver='lbfgs')
MLPClassifier(alpha=1e-05, hidden_layer_sizes=[500, 500, 500], max_iter=500,
random_state=1, solver='lbfgs')
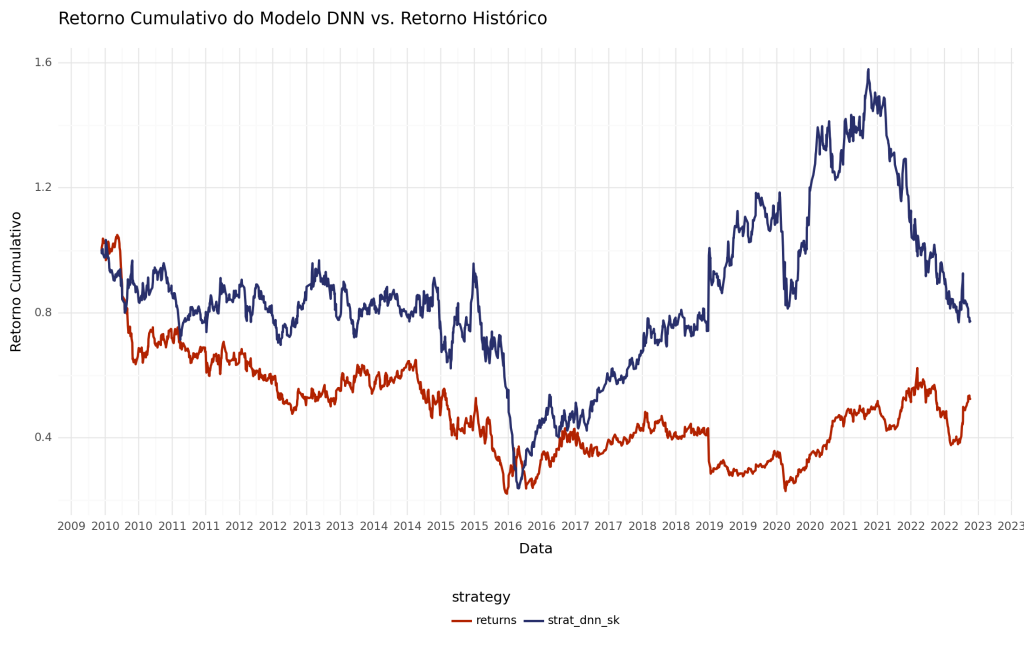
Com a previsão direcional em mãos, podemos aplicar o backtesting vetorizado para avaliar o desempenho das estratégias de negociação desenvolvidas. Nesta etapa, nossa análise se baseia em uma série de suposições simplificadoras, incluindo “custos de transação zero” e a utilização do mesmo conjunto de dados tanto para o treinamento quanto para o teste dos modelos.
Código
returns 0.526768 strat_dnn_sk 0.770468 dtype: float64
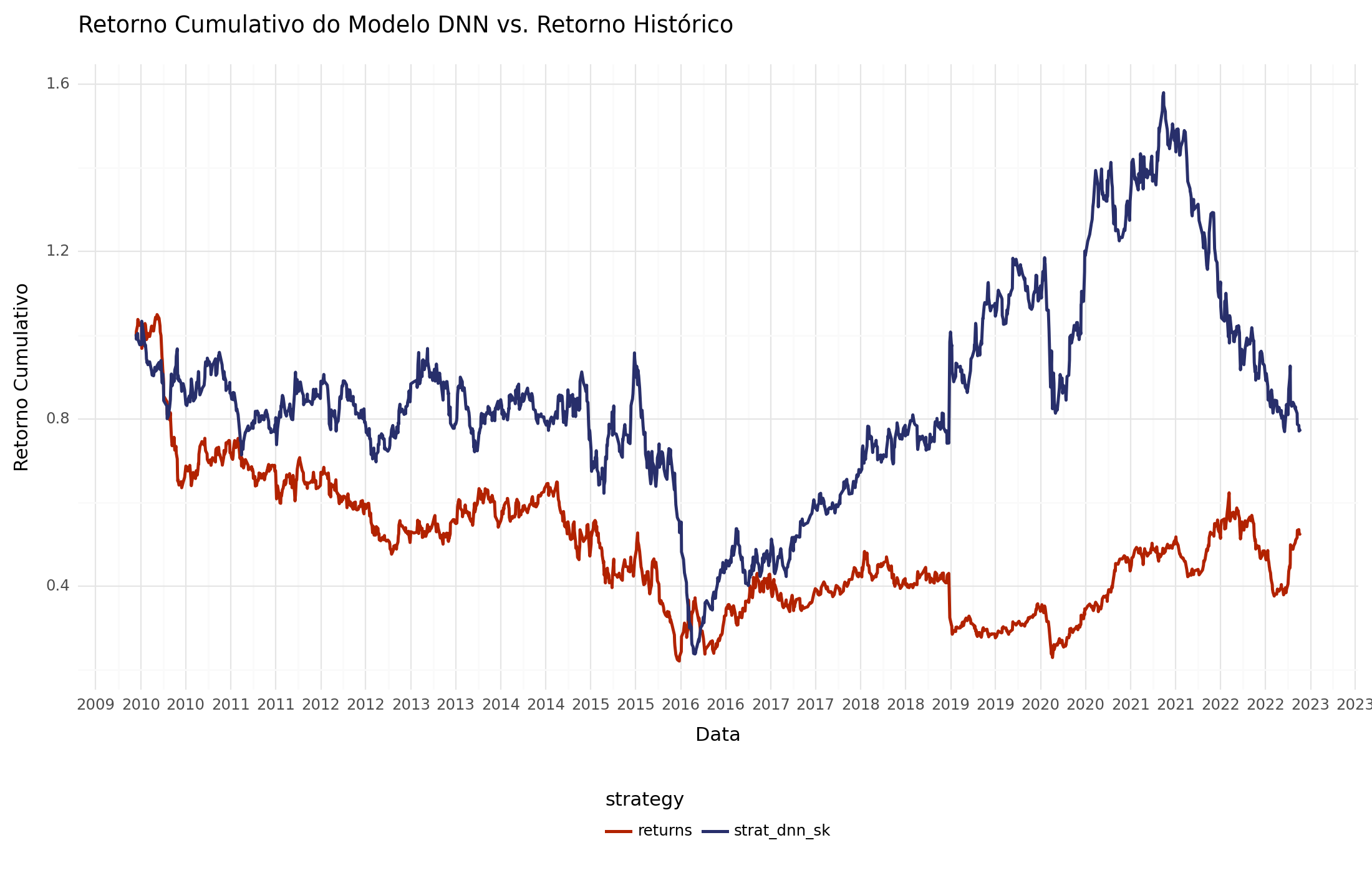
(Obs. isso não é recomendação de investimento).
Quer aprender mais?
Clique aqui para fazer seu cadastro no Boletim AM e baixar o código que produziu este exercício, além de receber novos exercícios com exemplos reais de análise de dados envolvendo as áreas de Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas diretamente em seu e-mail.

