Neste exercício mostramos como realizar a previsão da Volatilidade do Bitcoin em USD através do modelo HAR. Realizamos uma comparação da especificação proposta dos modelos tipo HAR type utilizando modelos de machine learning. O procedimento de coleta, tratamento e modelagem é realizado através do Python.
Aprenda a coletar, processar e analisar dados na formação de Do Zero à Análise de Dados Econômicos e Financeiros com Python.
Quer aprender a como criar modelos de série econômicas brasileiras usando Machine Learning e IA Generativa? Veja nosso curso IA para previsão Macroeconômica usando Python.
Introdução
O modelo HAR (Heterogeneous Autoregressive Model) é um modelo de previsão de volatilidade que considera diferentes horizontes temporais, como diário, semanal e mensal. Ele é especialmente útil para capturar a natureza persistente da volatilidade em mercados financeiros. A ideia central é que a volatilidade atual pode ser influenciada pela volatilidade observada em diferentes intervalos de tempo.
Estrutura do Modelo HAR
A fórmula básica do modelo HAR é:
![\[RV_t = \beta_0 + \beta_1 RV_{t-1} + \beta_2 RV_{t-1}^{(w)} + \beta_3 RV_{t-1}^{(m)} + \epsilon_t\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-d49f082778bef053cfa2f26b2c224418_l3.png "Rendered by QuickLaTeX.com")
Onde:
-  é a volatilidade realizada no dia
é a volatilidade realizada no dia  .
.
-  é a volatilidade realizada no dia anterior.
é a volatilidade realizada no dia anterior.
-  é a média da volatilidade realizada na semana anterior.
é a média da volatilidade realizada na semana anterior.
-  é a média da volatilidade realizada no mês anterior.
é a média da volatilidade realizada no mês anterior.
-  são parâmetros a serem estimados.
são parâmetros a serem estimados.
-  é o termo de erro.
é o termo de erro.
Para o caso do exercício, a Volatilidade Realizada calculada é a seguinte:
![\[RV_t \equiv \sum_{j=1}^{M} r_{t,j}^2\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-860ca3ac51e4a31013e800e268b5d524_l3.png "Rendered by QuickLaTeX.com")
HAR-J
Existem diversos tipos de modelos do tipo HAR. Um deles é conhecido como HAR-J, que é uma extensão do modelo HAR padrão que incorpora um componente de salto diário ( ) para capturar saltos bruscos na volatilidade. A inclusão desse componente permite ao modelo capturar melhor a dinâmica da volatilidade, especialmente em mercados financeiros onde saltos repentinos são comuns.
) para capturar saltos bruscos na volatilidade. A inclusão desse componente permite ao modelo capturar melhor a dinâmica da volatilidade, especialmente em mercados financeiros onde saltos repentinos são comuns.
A fórmula do modelo HAR-J é:
![\[RV_{t+h} = \beta_0 + \beta_d RV_t^{(1)} + \beta_w RV_t^{(5)} + \beta_m RV_t^{(22)} + \beta_j J_t + \epsilon_{t+h}\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-09c9cdc9bb317ebbb9f59d716d456d7b_l3.png "Rendered by QuickLaTeX.com")
Onde:
-  é a volatilidade realizada no dia
é a volatilidade realizada no dia  .
.
-  é a volatilidade realizada diária.
é a volatilidade realizada diária.
-  é a média da volatilidade realizada nos últimos 5 dias (semanal).
é a média da volatilidade realizada nos últimos 5 dias (semanal).
-  é a média da volatilidade realizada nos últimos 22 dias (mensal).
é a média da volatilidade realizada nos últimos 22 dias (mensal).
- é o componente de salto.
-  são os parâmetros a serem estimados.
são os parâmetros a serem estimados.
-  é o termo de erro.
é o termo de erro.
Componente de Salto ( )
)
O componente de salto é definido como a diferença entre a volatilidade realizada () e a variação bipower ( ), mas somente quando essa diferença é positiva. Isso permite ao modelo capturar apenas os saltos positivos na volatilidade, que são frequentemente indicativos de eventos bruscos ou choques no mercado.
), mas somente quando essa diferença é positiva. Isso permite ao modelo capturar apenas os saltos positivos na volatilidade, que são frequentemente indicativos de eventos bruscos ou choques no mercado.
![\[J_t = \max(RV_t - BPV_t, 0)\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-c5f6616e96b59c3b196b8af76614cafe_l3.png "Rendered by QuickLaTeX.com")
A variação bipower () é calculada usando a seguinte fórmula:
![\[BPV_t = \left(\frac{2}{\pi}\right) \sum_{j=2}^{M} |r_{t,j-1}||r_{t,j}|\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-6067544f6edc8320588d304d6ac3fea4_l3.png "Rendered by QuickLaTeX.com")
Onde  são os retornos logarítmicos.
são os retornos logarítmicos.
Modelagem
O modelo HAR pode ser estimado via MQO, utilizando uma regressão linear múltipla. Comparações são feitas com extensões da regressão linear e modelos de machine learning. Os modelos utilizados são:
- LinearRegression
- Ridge
- Lasso
- LinearSVR
- RandomForestRegressor
Os dados são diários, com a amostra iniciando em 2018 e terminando no final de maio de 2024. Metade da amostra é separada para treino, enquanto o restante é utilizado para teste. Para o backtesting, utilizou-se a validação cruzada com janela expansiva, realizando previsões para 5 dias à frente e reestimando o modelo ao fim de cada horizonte.
Análise de dados
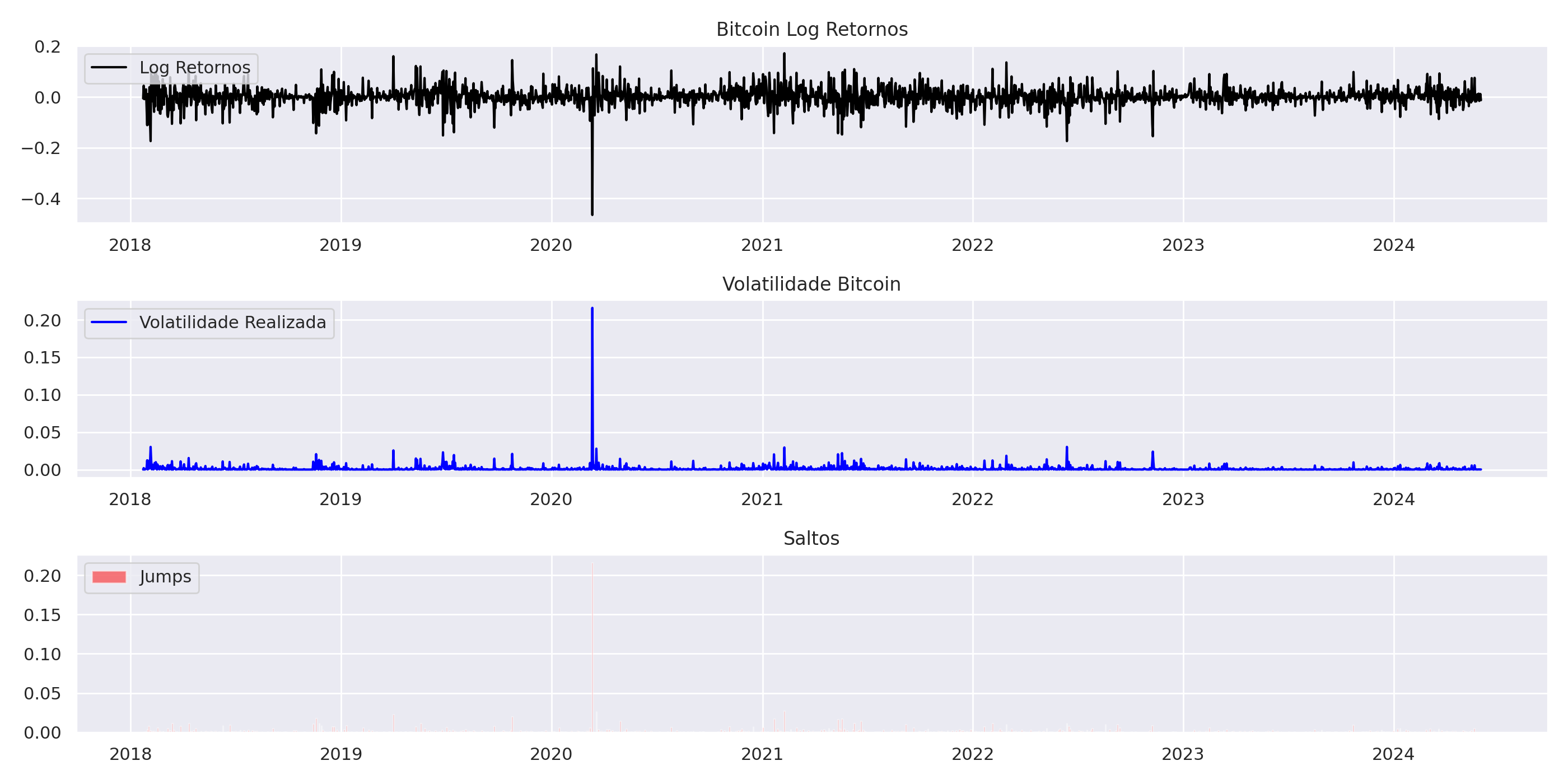
O gráfico mostra uma tendência geral de alta no preço do Bitcoin em USD desde o final de 2018. No entanto, existem períodos de flutuações consideráveis, com quedas acentuadas seguidas de recuperação.
- O Bitcoin teve um período de alta volatilidade em 2021, com quedas e recuperação significativas durante o ano.
- O Bitcoin experimentou uma queda acentuada no final de 2021 e início de 2022, com um período de recuperação mais gradual depois.
- O preço do Bitcoin parece ter se estabilizado um pouco em 2022 e 2023, embora tenha mostrado uma tendência de alta novamente em 2024.

O gráfico de log-retornos do Bitcoin demonstra um padrão interessante:
- Volatilidade: Os log-retornos oscilam ao redor de zero, indicando uma volatilidade constante ao longo do período.
- Picos de Volatilidade: Há alguns picos significativos de volatilidade, como o ocorrido em 2020, que indicam eventos de alta volatilidade no mercado.
- Distribuição: A distribuição dos log-retornos parece ser próxima de uma distribuição normal, com a maior parte dos valores concentrada em torno de zero.
2. Volatilidade Realizada:
O gráfico de volatilidade realizada mostra como a volatilidade do Bitcoin se manifesta ao longo do tempo:
- Pico em 2020: Existe um pico acentuado de volatilidade no início de 2020, coincidente com a queda no preço do Bitcoin. Isso indica um período de grande incerteza e instabilidade no mercado.
- Flutuações: A volatilidade realizada apresenta flutuações consideráveis ao longo do período, com períodos de alta e baixa volatilidade.
- Tendência: A volatilidade realizada tende a diminuir gradualmente após 2020, indicando uma redução na incerteza do mercado.
3. Saltos:
O gráfico de saltos evidencia os momentos de maior variação no preço do Bitcoin:
- Pico em 2020: Assim como nos gráficos anteriores, o gráfico de saltos apresenta um pico significativo em 2020, sinalizando uma mudança repentina e significativa no preço do Bitcoin.
- Eventos Discretos: O gráfico de saltos destaca eventos discretos de alta volatilidade, que provavelmente representam eventos como crises ou grandes notícias.
- Tendência: A frequência e intensidade dos saltos diminuem após 2020, corroborando a tendência de menor volatilidade observada nos outros gráficos.

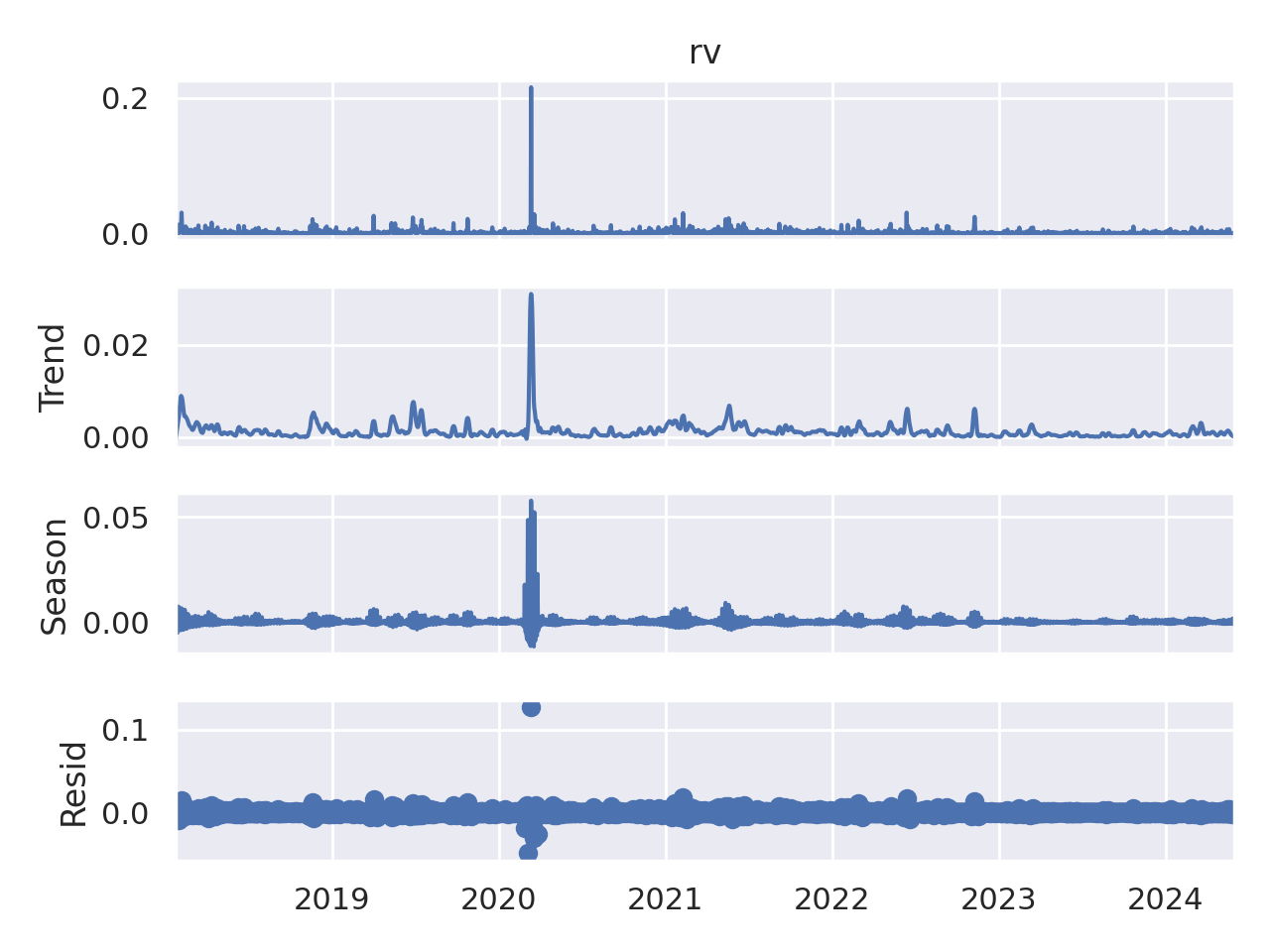
O gráfico apresenta a decomposição da volatilidade realizada do Bitcoin em suas componentes de tendência, sazonalidade e resíduo.
1. Tendência:
- A tendência da volatilidade realizada mostra um aumento gradual da volatilidade até 2020, seguido por uma redução e estabilização.
2. Sazonalidade:
- A sazonalidade da volatilidade realizada é relativamente baixa, com pequenas flutuações ao longo do tempo.
3. Resíduo:
- O componente de resíduo, que representa a parte da volatilidade não explicada pela tendência e sazonalidade, é geralmente baixo e oscila ao redor de zero.
- Há alguns picos discretos de resíduo em 2020.

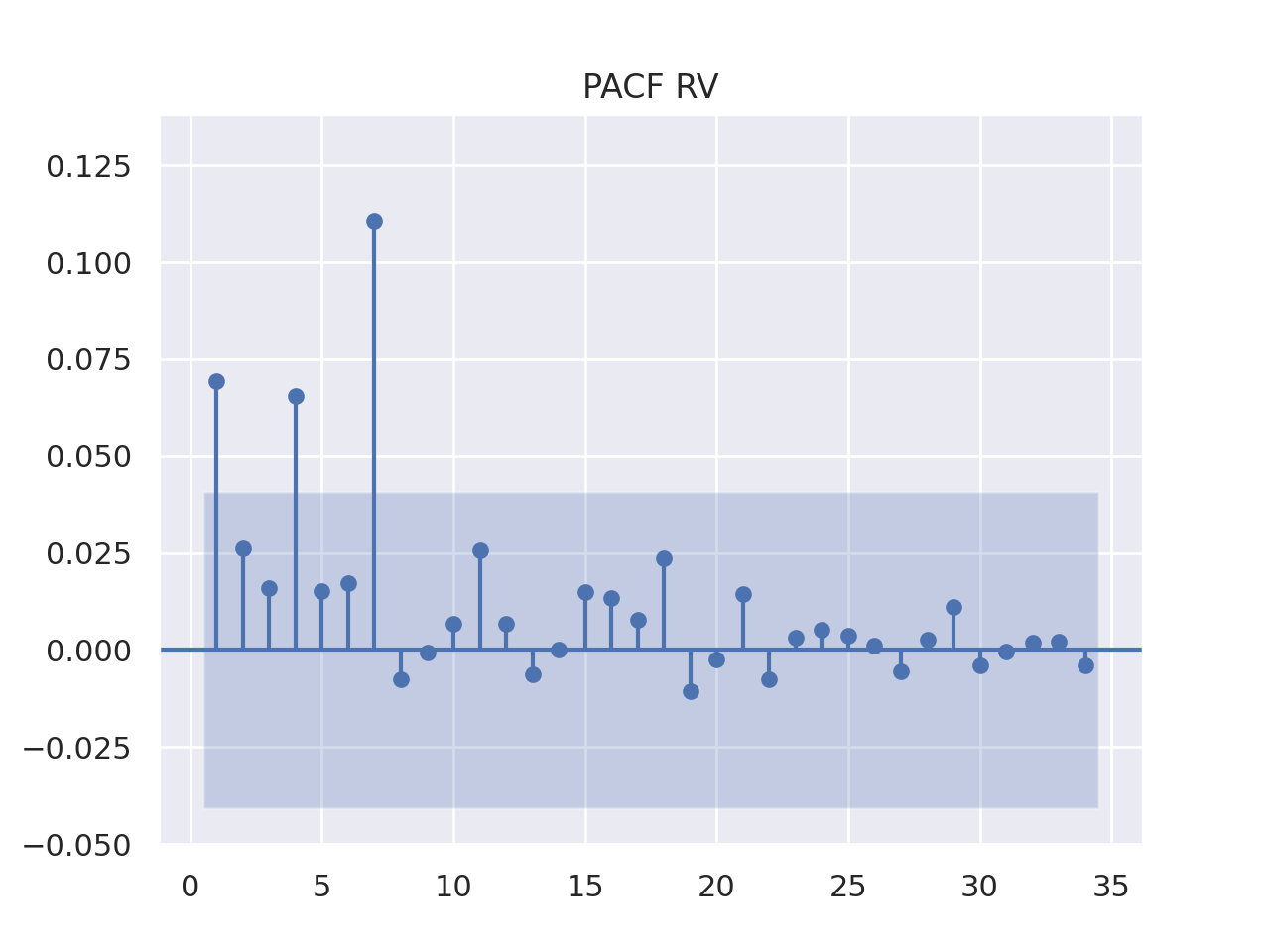
A análise conjunta do ACF e PACF da volatilidade realizada do Bitcoin indica que a série possui autocorrelação significativa e persistente, com um padrão periódico, como observado no ACF. No PACF, o primeiro lag apresenta autocorrelação significativa, enquanto os lags seguintes são próximos de zero, sugerindo um processo AR(1), ou seja, a volatilidade atual é influenciada principalmente pela volatilidade do período anterior.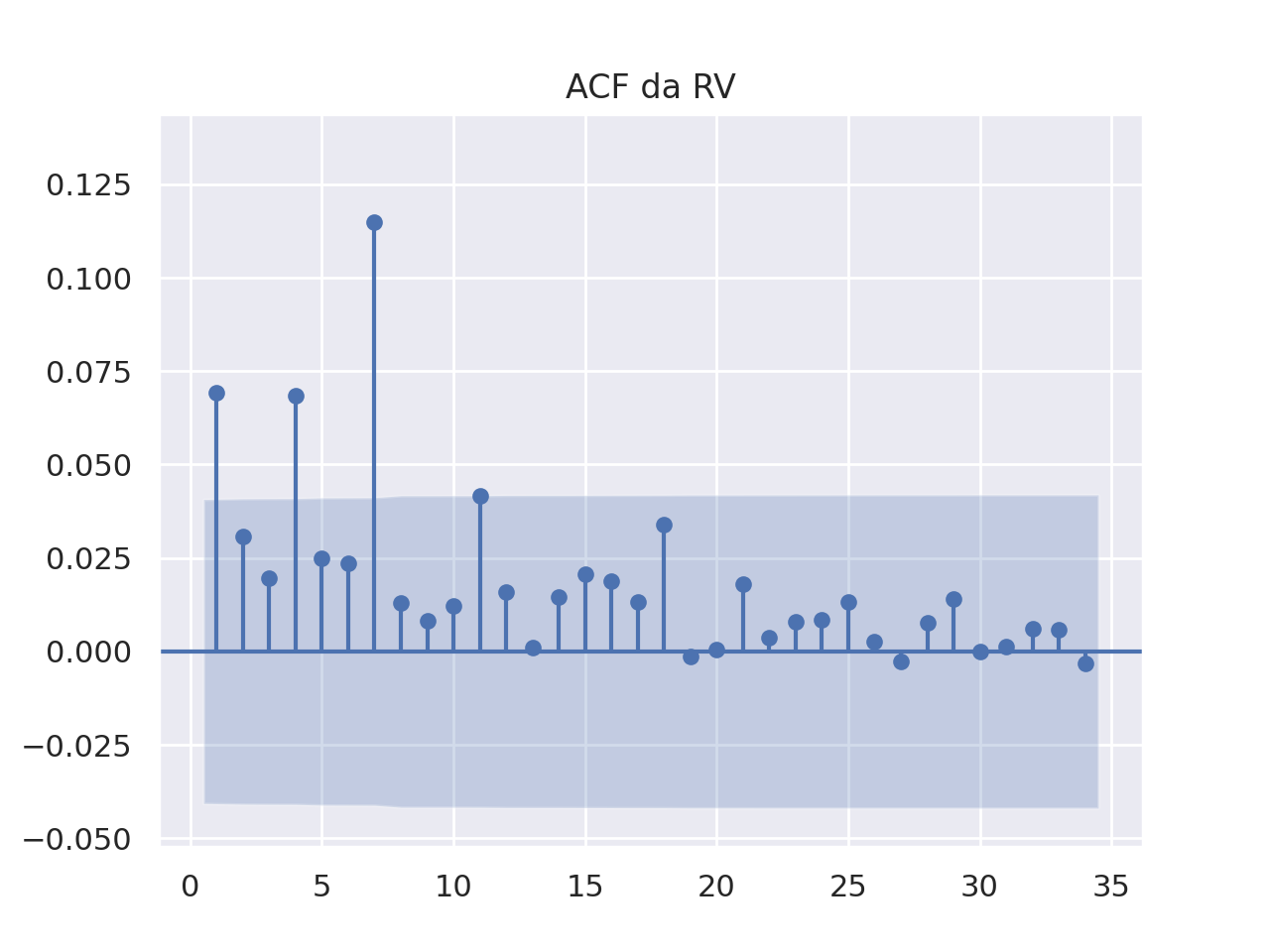
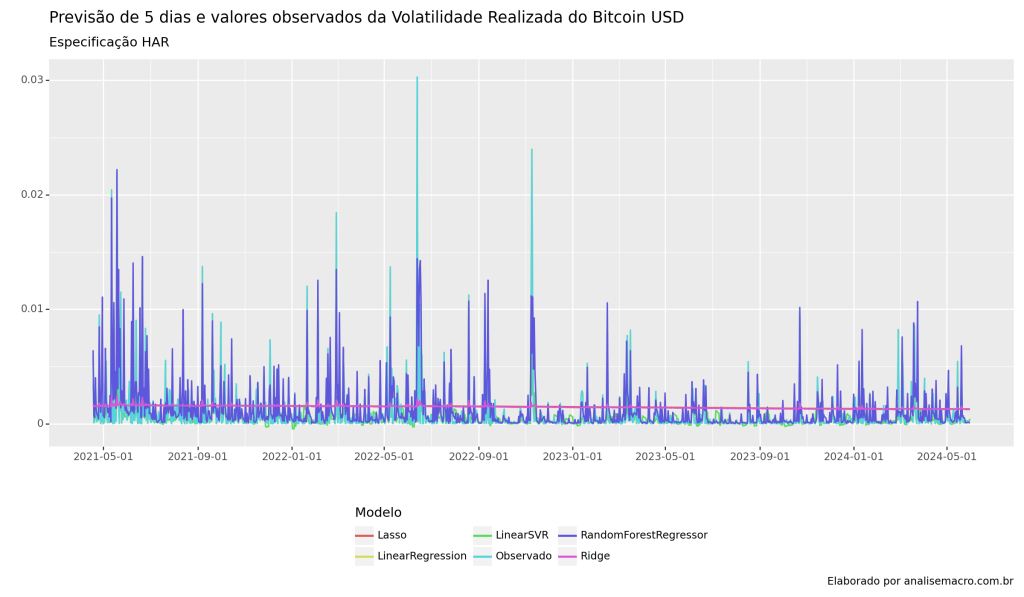
Previsões
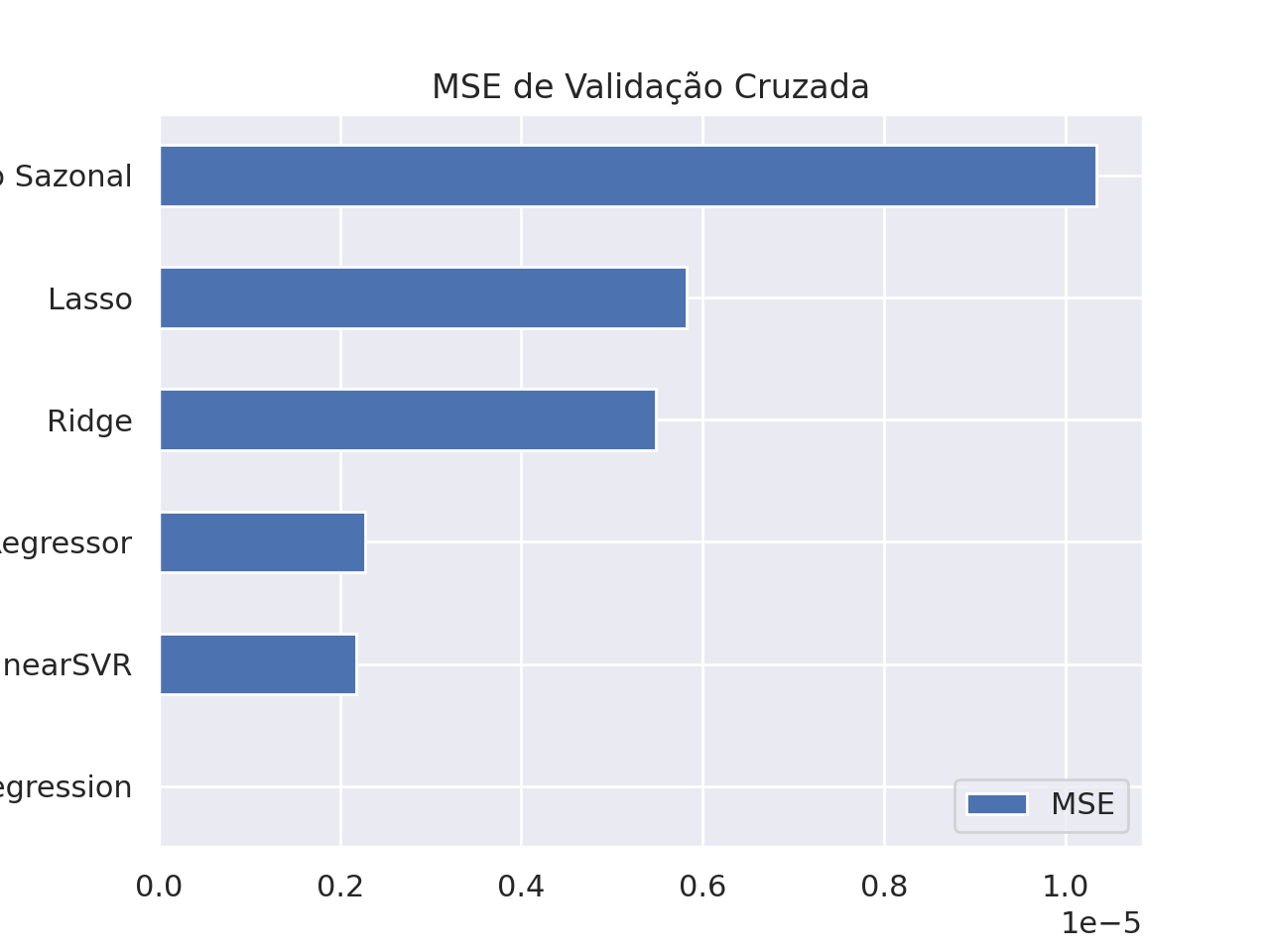
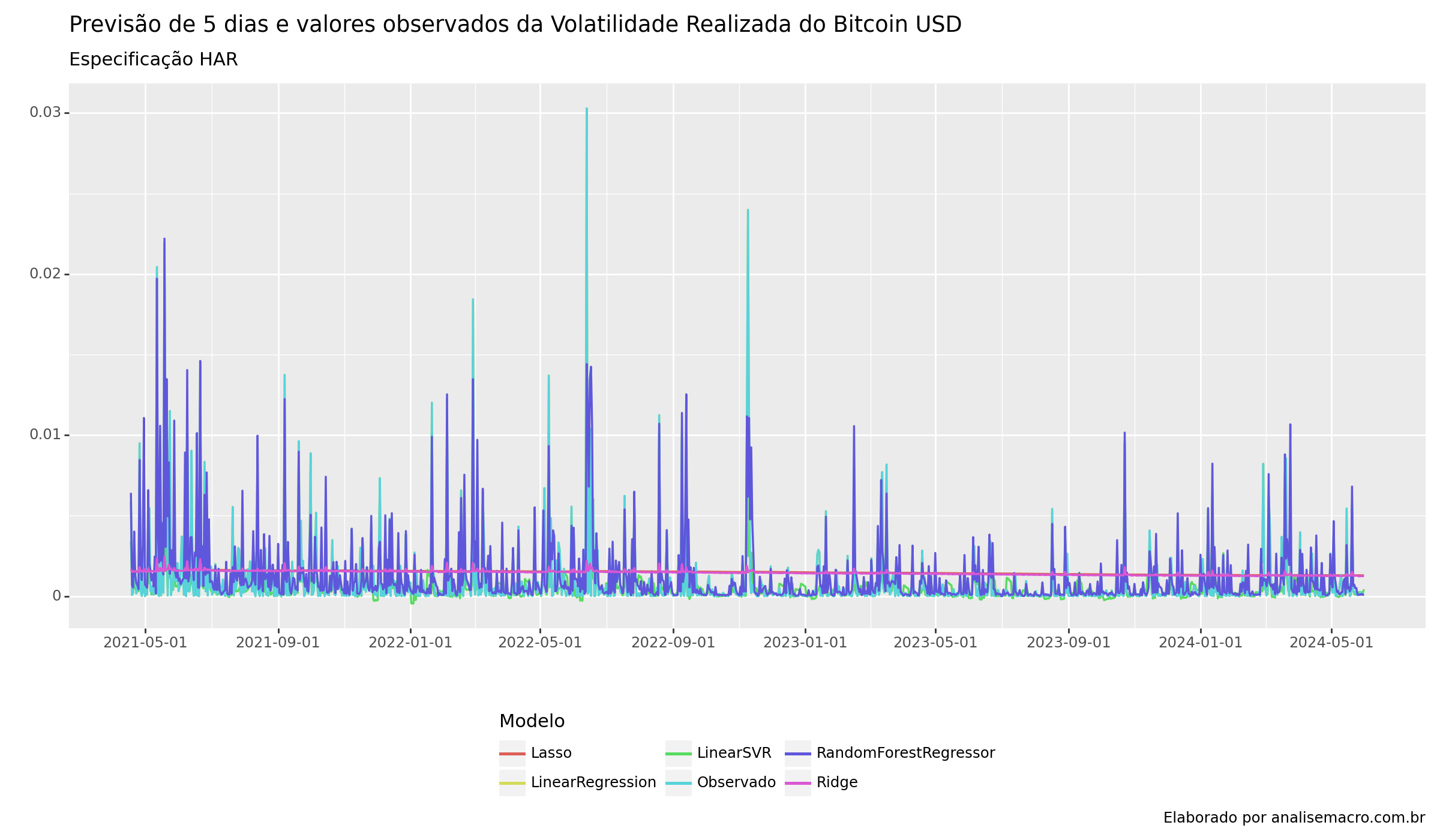
Abaixo, as métricas de MSE e as previsões dos modelos no período de teste da validação cruzada.
Quer aprender mais?
Clique aqui para fazer seu cadastro no Boletim AM e baixar o código que produziu este exercício, além de receber novos exercícios com exemplos reais de análise de dados envolvendo as áreas de Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas diretamente em seu e-mail.

