O pacote electionsbr oferece um conjunto de funções que possibilitam a extração de dados eleitorais diretamente da base de dados do Tribunal Superior Eleitoral (TSE). Com ele é possível obter dados de todas as eleições desde 1994 desagregados até por zona eleitoral. Além disso, é possível obter informações sobre filiação partidária, características dos eleitores de cada zona eleitoral e declaração patrimonial de todos os candidatos.
Para mostrar a funcionalidade do pacote, iremos utilizar os dados da última eleição federal, em 2018. Iremos separar apenas os votos para presidente e selecionar o partido - no caso a chapa - que recebeu mais votos em cada município.
elec_2018 = party_mun_zone_fed(2018, br_archive = TRUE) %>% filter(DESCRICAO_CARGO == "Presidente" & NUM_TURNO == 1) %>% group_by(CODIGO_MUNICIPIO) %>% top_n(1, QTDE_VOTOS_NOMINAIS) %>% mutate(CODIGO_MUNICIPIO = as.double(CODIGO_MUNICIPIO)) %>% select(CODIGO_MUNICIPIO, SIGLA_PARTIDO)
O código utilizado como identificador de cada município é específico do TSE e é diferente do código IBGE padrão. Por isso, como iremos colocar em um mapa utilizando o pacote geobr, precisamos de uma tabela para conversão.
</pre>
tse_ibge_id <- read_csv("https://raw.githubusercontent.com/betafcc/Municipios-Brasileiros-TSE/master/municipios_brasileiros_tse.csv")
elec_2018 = left_join(elec_2018, tse_ibge_id, by = c("CODIGO_MUNICIPIO" = "codigo_tse"))
<pre>
Assim, fazemos o download dos mapas por município e estado e juntamos com a nossa base.
</pre>
mapa_muni = read_municipality(showProgress = FALSE)
mapa_state = read_state(showProgress = FALSE)
df <- left_join(mapa_muni, elec_2018, by = c("code_muni" = "codigo_ibge"))
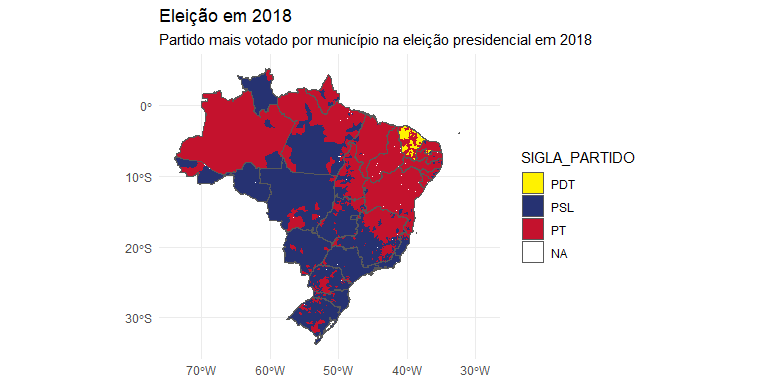
Agora, podemos fazer o mapa com os dados, que mostram grande concentração espacial do voto.
ggplot() + geom_sf(df, mapping = aes(fill = SIGLA_PARTIDO), colour = NA) + geom_sf(mapa_state, mapping = aes(fill = NA)) + scale_fill_manual(values=c( "#fff200", "#263272", "#c4122d")) + theme_minimal() + labs(title = "Eleição em 2018", subtitle = "Partido mais votado por município na eleição presidencial em 2018")