[et_pb_section admin_label="section"][et_pb_row admin_label="row"][et_pb_column type="4_4"][et_pb_text admin_label="Texto" background_layout="light" text_orientation="justified" text_font="Verdana||||" text_font_size="18" use_border_color="off" border_color="#ffffff" border_style="solid"]
A partir da adoção do regime de metas em 1999, tornou-se necessária a criação de modelos de previsão no âmbito do Banco Central do Brasil, para projetar o comportamento de variáveis macroeconômicas, em particular, naturalmente, a inflação. Essa necessidade deriva, por óbvio, de se tentar antecipar a correção da inflação frente à meta em um determinado ano, bem como da existência de defasagens entre as decisões de política monetária e seus efeitos sobre os preços, não sem antes passar por diversos canais de transmissão. De modo a divulgar a área de Central Banking da Análise Macro, que será anunciada em julho, estamos escrevendo alguns posts sobre detalhes desses modelos no Blog (ver o primeiro post aqui). Nesse post, vamos mostrar as previsões de dois modelos VAR e VEC adotados pelo Banco Central. Os códigos completos, a propósito, estão disponíveis na edição 34 do Clube do Código.
Coletando os dados
Antes de mais nada, vamos pegar os dados no próprio Banco Central, utilizando para isso o pacote BETS. O código abaixo ilustra.
### Coletar os dados inflacao = BETS.get(433) selic = BETS.get(4189) cambio = BETS.get(3697) industria = BETS.get(21940)
De posse desses dados, precisamos fazer algumas transformações. O código abaixo ilustra.
# Transformações dselic = diff(selic) dcambio = diff(cambio) # Criar e projetar hiato t+1 hp = hpfilter(industria, freq=14400, type='lambda') hiato = ts(hpmean hiato = ts(c(hiato, hiatof), start=start(industria), freq=12) # Criar dummies sazonais dummies = window(ts(seasonaldummy(inflacao), start=start(inflacao), freq=12), start=c(2007,01)) # Juntar séries data = window(ts.intersect(inflacao, dselic, dcambio, hiato), start=c(2007,01)) colnames(data) = c('inflacao', 'dselic', 'dcambio', 'hiato')
 mean
hiato = ts(c(hiato, hiatof), start=start(industria), freq=12)
# Criar dummies sazonais
dummies = window(ts(seasonaldummy(inflacao),
start=start(inflacao), freq=12), start=c(2007,01))
# Juntar séries
data = window(ts.intersect(inflacao, dselic, dcambio, hiato),
start=c(2007,01))
colnames(data) = c('inflacao', 'dselic', 'dcambio', 'hiato')
mean
hiato = ts(c(hiato, hiatof), start=start(industria), freq=12)
# Criar dummies sazonais
dummies = window(ts(seasonaldummy(inflacao),
start=start(inflacao), freq=12), start=c(2007,01))
# Juntar séries
data = window(ts.intersect(inflacao, dselic, dcambio, hiato),
start=c(2007,01))
colnames(data) = c('inflacao', 'dselic', 'dcambio', 'hiato')
Observe que optamos nesse exercício por criar o hiato do produto a partir da produção industrial. Feitos os demais ajustes, o que temos são as séries abaixo.
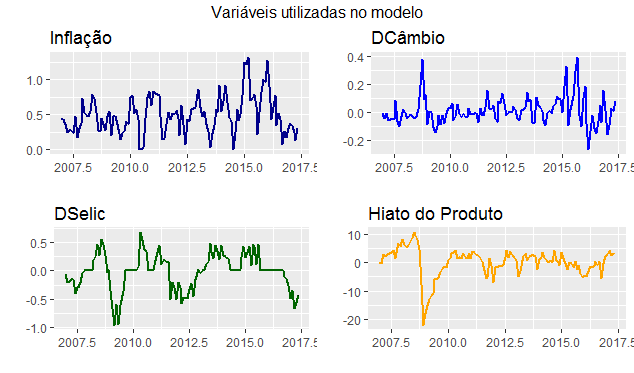
Modelo VAR
Com essas séries, então, podemos estimar o modelo VAR. O código abaixo ilustra.
lag = VARselect(data, lag.max=12, type='trend', season = 12) var = VAR(data, min(lag$selection), type='both', exogen = dummies)
Com o primeiro comando, nós definimos a defasagem e com o segundo estimamos o VAR, tomando o cuidado de colocar as dummies sazonais como variáveis exógenas. Uma vez feito isso, nós podemos gerar as previsões do modelo com o código abaixo.
h = 7 fvar = predict(var, n.ahead=h, ci=.4, dumvar=head(dummies,h))
Agora, com as previsões em mãos, podemos acumular a inflação em 12 meses e gerar um gráfico como abaixo.
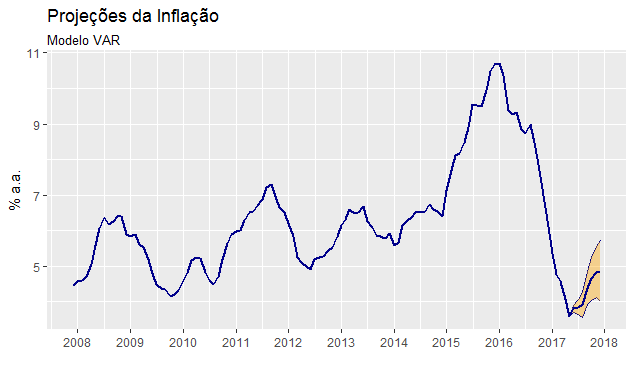
As projeções geradas pelo modelo não são boas. A inflação acumulada em 12 meses terminaria 2017 em 4,85%, bem distante das previsões médias do mercado. Com efeito, vamos avançar um pouco mais, criando agora um vetor de correção de erros.
Modelo VEC
Para estimar o modelo VEC, vamos considerar todas as variáveis acima em nível. Precisamos também verificar se existe, de fato, cointegração entre as variáveis. Os códigos completos estão, a propósito, disponíveis na edição 34 do Clube do Código. Uma vez confirmado isso, podemos estimar o modelo, gerar as previsões e acumular a inflação prevista em 12 meses. O gráfico abaixo ilustra a trajetória da variável.
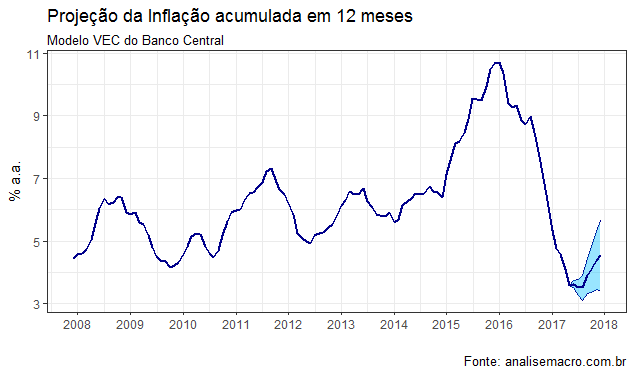
Com esse modelo, a inflação média prevista para o fim de 2017 vai para 4,53%, ainda bastante elevada se considerarmos as previsões médias do mercado. Desse modo, é preciso continuar melhorando o nosso modelo, incorporando outras variáveis, bem como gerando uma combinação das previsões entre os diversos modelos estimados. Os modelos do Banco Central, a propósito, não fazem uso da inflação cheia, mas sim da inflação de preços livres e de preços administrados, dado que os dois grupos possuem dinâmicas bastante distintas.
O objetivo do post, a propósito, foi o de mostrar como o R pode facilitar a estimação desse tipo de modelo, haja vista que para uma previsão com acurácia razoável, é necessário a estimação de diversos modelos, com pequenas modificações entre eles. Sem programação, imagine o trabalho que isso daria?
Por fim, cabe dizer que a área de Central Banking da Análise Macro, que será divulgada na próxima semana, irá contar, inicialmente, com três cursos. O primeiro a abrir inscrições será o curso de Teoria de Política Monetária, cujo objetivo será apresentar a teoria por trás da moderna condução da política monetária. Esse curso terá início em agosto. O segundo curso da área será o de Modelos do Banco Central com foco nos diversos modelos VAR/VEC e no modelo semi-estrutural de pequeno porte da autoridade monetária. Esse curso terá início em outubro. O último curso dessa saga será o de Modelos DSGE, com início previsto para dezembro.
Os pré-requisitos para esses cursos são um bom conhecimento da linguagem R, que pode ser alcançado com o nosso curso de Introdução ao R e conhecimentos de econometria e séries temporais, que também podem ser alcançados em nossos cursos na área de Econometria. Ah, sim, falando nisso, temos turmas abertas começando na próxima semana, clique abaixo para conhecer...
[/et_pb_text][et_pb_button admin_label="Botão" button_url="https://analisemacro.com.br/cursos/ultimas-vagas-para-os-cursos-aplicados-de-r-com-inicio-em-0307/" url_new_window="off" button_text="Conhecer os Cursos com Inscrições abertas" button_alignment="center" background_layout="light" custom_button="off" button_letter_spacing="0" button_use_icon="default" button_icon_placement="right" button_on_hover="on" button_letter_spacing_hover="0"] [/et_pb_button][/et_pb_column][/et_pb_row][/et_pb_section]

