[et_pb_section admin_label="section"][et_pb_row admin_label="row"][et_pb_column type="4_4"][et_pb_text admin_label="Texto" background_layout="light" text_orientation="justified" text_font="Verdana||||" text_font_size="18" use_border_color="off" border_color="#ffffff" border_style="solid"]
O fundo do poço, enfim, parece estar ficando para trás no mercado de trabalho brasileiro. Os dados do Cadastro Geral de Empregados e Desempregados (CAGED) do Ministério do Trabalho e da Pesquisa Nacional por Amostragem de Domicílios (PNAD) Contínua, do IBGE, sinalizam a esperança em dias melhores. As duas pesquisas, a propósito, contam com scripts automáticos no âmbito do Clube do Código. Nesse post, fazemos um resumo desses scripts. O código completo está disponível no Clube.
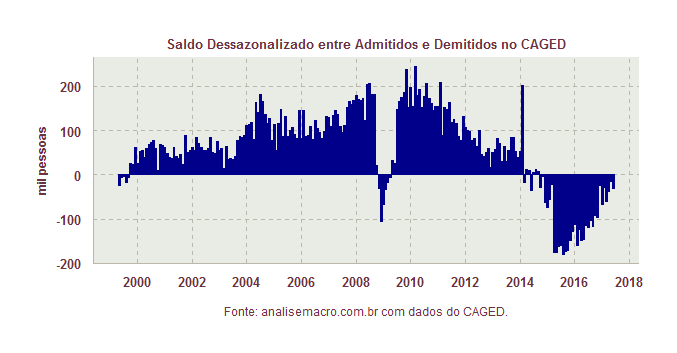
Lentamente, como mostra o gráfico acima, o saldo entre admitidos e demitidos do CAGED tem melhorado, já retirados os efeitos sazonais. Isso pode ser interpretado como um sinal de que o pior ficou para trás no mercado de trabalho brasileiro. O gráfico acima pode ser, a propósito, aberto por setores, com início em 2004, como abaixo.

A despeito do saldo total ainda ser negativo na ponta, retirados os efeitos sazonais, a tendência mostrada pelos dados é de clara recuperação. Uma outra forma de ver essa lenta melhora é pela comparação entre os salários de admitidos e demitidos, como mostra o terceiro gráfico abaixo.
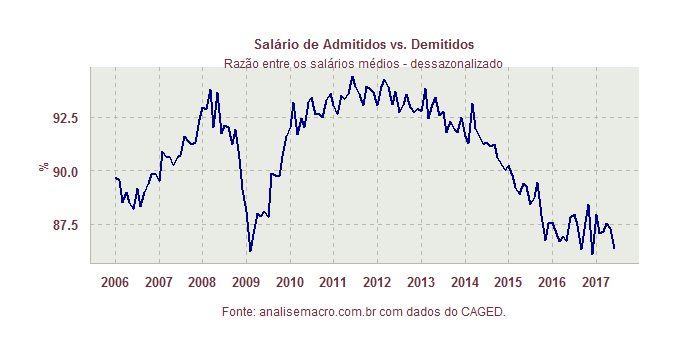
O gráfico mostra, em termos percentuais, o quanto o salário médio dos admitidos representa do salário médio dos demitidos, também feito o ajuste sazonal. Observe que a tendência de queda parece ter sido interrompida na ponta, o que também sinaliza alguma melhora no mercado de trabalho.
Os dados do CAGED, naturalmente, representam apenas uma parcela do mercado de trabalho, já que fazem referência aos fluxos de trabalhadores com carteira assinada. Para aumentar nossa compreensão sobre o mercado, por suposto, podemos analisar agora os dados da PNAD Contínua, que cobre tanto o emprego formal quanto o informal, além de outras subdivisões. Abaixo, duas tabelas com um resumo da pesquisa referente a junho último.
[/et_pb_text][/et_pb_column][/et_pb_row][et_pb_row admin_label="row"][et_pb_column type="1_2"][et_pb_code admin_label="Código"]<!-- html table generated in R 3.2.3 by xtable 1.8-2 package --> <!-- Sun Jul 30 14:53:11 2017 --> <table border=1> <tr> <th> </th> <th> Jun/17 </th> <th> Jun/16 </th> <th> Variação (%) </th> </tr> <tr> <td align="right"> População </td> <td align="right"> 206883.0 </td> <td align="right"> 205301.0 </td> <td align="right"> 0.8 </td> </tr> <tr> <td align="right"> PIA </td> <td align="right"> 168136.0 </td> <td align="right"> 166270.0 </td> <td align="right"> 1.1 </td> </tr> <tr> <td align="right"> PEA </td> <td align="right"> 103722.0 </td> <td align="right"> 102384.0 </td> <td align="right"> 1.3 </td> </tr> <tr> <td align="right"> PNEA </td> <td align="right"> 13486.0 </td> <td align="right"> 11586.0 </td> <td align="right"> 16.4 </td> </tr> <tr> <td align="right"> PO </td> <td align="right"> 90236.0 </td> <td align="right"> 90798.0 </td> <td align="right"> -0.6 </td> </tr> <tr> <td align="right"> PD </td> <td align="right"> 13486.0 </td> <td align="right"> 11586.0 </td> <td align="right"> 16.4 </td> </tr> <tr> <td align="right"> Desemprego </td> <td align="right"> 13.0 </td> <td align="right"> 11.3 </td> <td align="right"> 14.9 </td> </tr> <tr> <td align="right"> Renda Nominal </td> <td align="right"> 2104.0 </td> <td align="right"> 1972.0 </td> <td align="right"> 6.7 </td> </tr> <tr> <td align="right"> Renda Real </td> <td align="right"> 2104.0 </td> <td align="right"> 2015.0 </td> <td align="right"> 4.4 </td> </tr> <tr> <td align="right"> PIA/Pop </td> <td align="right"> 81.3 </td> <td align="right"> 81.0 </td> <td align="right"> 0.3 </td> </tr> <tr> <td align="right"> Participação </td> <td align="right"> 61.7 </td> <td align="right"> 61.6 </td> <td align="right"> 0.2 </td> </tr> <tr> <td align="right"> PO/PIA </td> <td align="right"> 53.7 </td> <td align="right"> 54.6 </td> <td align="right"> -1.7 </td> </tr> </table>[/et_pb_code][/et_pb_column][et_pb_column type="1_2"][et_pb_code admin_label="Código"]<!-- html table generated in R 3.2.3 by xtable 1.8-2 package --> <!-- Sun Jul 30 14:54:01 2017 --> <table border=1> <tr> <th> </th> <th> Jun/17 </th> <th> Jun/16 </th> </tr> <tr> <td align="right"> População </td> <td align="right"> 130.0 </td> <td align="right"> 134.0 </td> </tr> <tr> <td align="right"> PIA </td> <td align="right"> 266.0 </td> <td align="right"> 139.0 </td> </tr> <tr> <td align="right"> PEA </td> <td align="right"> 263.0 </td> <td align="right"> 95.0 </td> </tr> <tr> <td align="right"> PNEA </td> <td align="right"> -286.0 </td> <td align="right"> 146.0 </td> </tr> <tr> <td align="right"> PO </td> <td align="right"> 549.0 </td> <td align="right"> -51.0 </td> </tr> <tr> <td align="right"> PD </td> <td align="right"> -285.0 </td> <td align="right"> 146.0 </td> </tr> <tr> <td align="right"> Desemprego </td> <td align="right"> -0.3 </td> <td align="right"> 0.1 </td> </tr> <tr> <td align="right"> Renda Nominal </td> <td align="right"> -5.0 </td> <td align="right"> -10.0 </td> </tr> <tr> <td align="right"> Renda Real </td> <td align="right"> -12.0 </td> <td align="right"> -25.0 </td> </tr> <tr> <td align="right"> PIA/Pop </td> <td align="right"> 0.1 </td> <td align="right"> 0.0 </td> </tr> <tr> <td align="right"> Participação </td> <td align="right"> 0.1 </td> <td align="right"> 0.0 </td> </tr> <tr> <td align="right"> PO/PIA </td> <td align="right"> 0.2 </td> <td align="right"> -0.1 </td> </tr> </table>[/et_pb_code][/et_pb_column][/et_pb_row][et_pb_row admin_label="row"][et_pb_column type="4_4"][et_pb_text admin_label="Texto" background_layout="light" text_orientation="justified" text_font="Verdana||||" text_font_size="18" use_border_color="off" border_color="#ffffff" border_style="solid"]
A primeira tabela traz o estoque das variáveis, enquanto a segunda mostra a dinâmica em relação ao mês anterior. Em junho, para uma população total de cerca de 207 milhões de pessoas, participavam da população economicamente ativa (PEA), 103,7 milhões de pessoas. Dessas, 13,5 milhões encontravam-se desempregadas. Em termos percentuais, 13% da PEA. Esse valor de desempregados é, a propósito, menor em 285 mil pessoas, se comparado a maio.
Como fica claro pelas tabelas, na comparação interanual, isto é, com o o mesmo mês do ano anterior, a recuperação não fica clara. Na margem, porém, quando se compara com o mês anterior, há sinais de melhora. Das 549 mil vagas criadas em junho, representando o aumento na população ocupada, 73 mil foram com carteira assinada, 152 mil vagas sem carteira, 134 mil no setor público, 73 mil como Empregador, 135 por Conta Própria e 11 mil como Trabalhador Familiar Auxiliar. Abaixo um gráfico sobre como têm evoluído algumas métricas selecionadas, na comparação interanual.
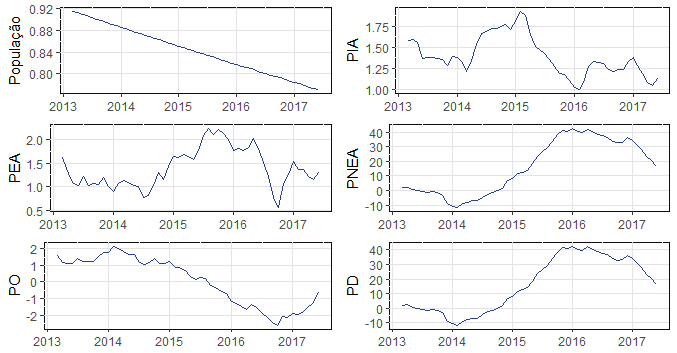
A população ocupada ensaia sair do terreno negativo, bem como a população desocupada tem cedido. Abaixo mais métricas, na mesma base de comparação.
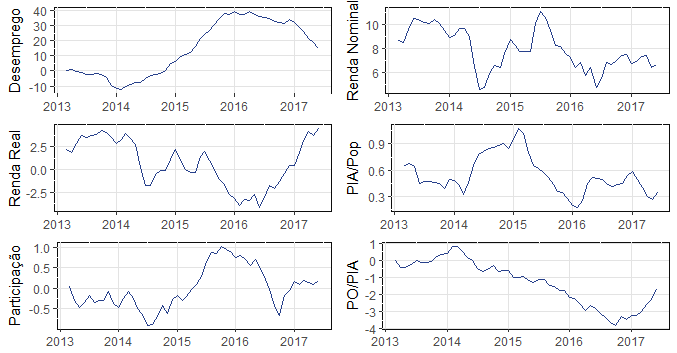
O quadro geral mostra alguma esperança no mercado de trabalho. Mas essa recuperação, como o CAGED indica acima, tem sido liderada pelo mercado informal. No mercado formal, o saldo entre contratações e demissões só agora no segundo semestre devem começar a entrar no terreno positivo. O gráfico abaixo ilustra, na mesma base de comparação anterior, a abertura da população ocupada.
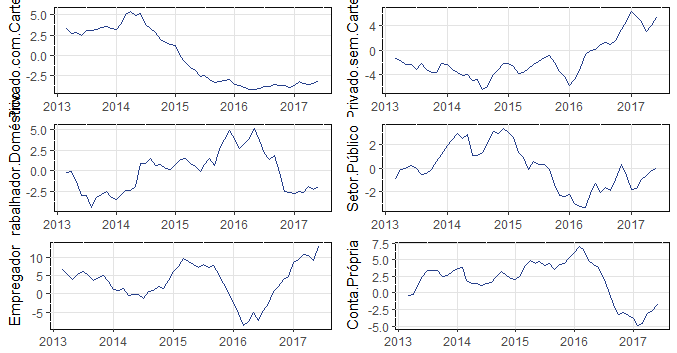
Para fechar nossa análise, chegamos ao desemprego propriamente dito. Abaixo ilustramos um gráfico que compara o desemprego em t com o desemprego em t-12, mostrando a evolução do mesmo em pontos percentuais, de forma a verificar alguma dinâmica dessa variável.
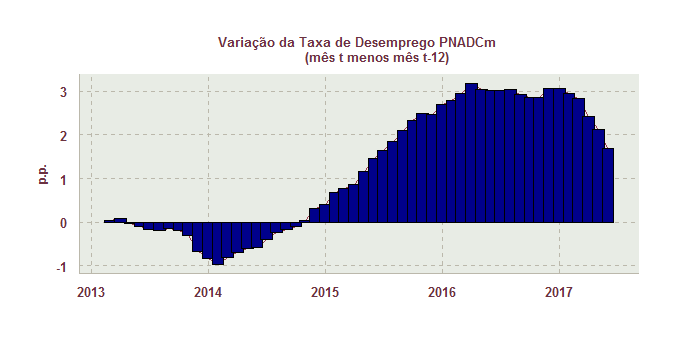
O dado na margem parece indicar que o desemprego começou a inverter a tendência de aumento fulminante verificada desde o início de 2014. Nosso modelo BVAR, a propósito, capturou essa queda nos próximos meses, como mostra o gráfico abaixo.
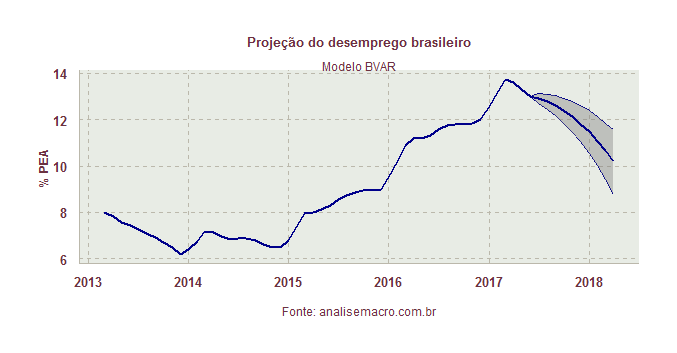
O que os dados parecem dizer é que, enfim, o pior já passou. Mas, infelizmente, a recuperação de empregos ainda será bastante lenta, dado o tamanho do estrago...
[/et_pb_text][/et_pb_column][/et_pb_row][et_pb_row admin_label="row"][et_pb_column type="4_4"][et_pb_team_member admin_label="Pessoa" saved_tabs="all" name="Vítor Wilher " position="Data Scientist" image_url="https://analisemacro.com.br/wp-content/uploads/2011/03/vitorwilhergnews.png" animation="left" background_layout="light" facebook_url="https://www.facebook.com/vitor.wilher.9" twitter_url="https://twitter.com/vitorwilherbr" linkedin_url="https://www.linkedin.com/in/v%C3%ADtor-wilher-78164024" use_border_color="off" border_color="#ffffff" border_style="solid"]
Vítor Wilher é Bacharel e Mestre em Economia, pela Universidade Federal Fluminense, tendo se especializado na construção de modelos macroeconométricos, política monetária e análise da conjuntura macroeconômica doméstica e internacional. Tem, ademais, especialização em Data Science pela Johns Hopkins University. Sua dissertação de mestrado foi na área de política monetária, titulada "Clareza da Comunicação do Banco Central e Expectativas de Inflação: evidências para o Brasil", defendida perante banca composta pelos professores Gustavo H. B. Franco (PUC-RJ), Gabriel Montes Caldas (UFF), Carlos Enrique Guanziroli (UFF) e Luciano Vereda Oliveira (UFF). Já trabalhou em grandes empresas, nas áreas de telecomunicações, energia elétrica, consultoria financeira e consultoria macroeconômica. É o criador da Análise Macro, startup especializada em treinamento e consultoria em linguagens de programação voltadas para data analysis, sócio da MacroLab Consultoria, empresa especializada em cenários e previsões e fundador do hoje extinto Grupo de Estudos sobre Conjuntura Econômica (GECE-UFF). É também Visiting Professor da Universidade Veiga de Almeida, onde dá aulas nos cursos de MBA da instituição, Conselheiro do Instituto Millenium e um dos grandes entusiastas do uso do R no ensino. Leia os posts de Vítor Wilher aqui. Caso queira, mande um e-mail para ele: vitorwilher@analisemacro.com.br
[/et_pb_team_member][/et_pb_column][/et_pb_row][/et_pb_section]

