O Índice de Preços por Atacado-Oferta Global (IPA-OG), no seu corte restrito aos produtos agrícolas, tem avançado de forma bastante pronunciada nos últimos meses. Em setembro, por exemplo, o índice variou 8,57%, o que no acumulado em 12 meses gerou uma variação de 46,2%. Dada a sua relação com os índices ao consumidor, não é de se estranhar que a última edição do Relatório de Inflação do Banco Central tenha contido um box sobre o assunto. Nesse Comentário de Conjuntura, vamos mostrar como coletar os dados do IPA e da Inflação no Domicílio a partir do Sistema de Séries Temporais do Banco Central e do SIDRA/IBGE. São assuntos, diga-se, que eu ensino no nosso Curso de Análise de Conjuntura usando o R.
O script começa carregando alguns pacotes de R:
########################################################### ################## IPA vs. IPCA ########################## library(sidrar) library(tidyverse) library(tstools) library(BETS)
Uma vez carregados os pacotes, podemos usar o pacote sidrar para coletar os dados da alimentação no domícilio dentro do Índice de Preços ao Consumidor Amplo (IPCA).
alim_dom_01 = get_sidra(api='/t/1419/n1/all/v/63/p/all/c315/7171/d/v63%202') alim_dom_02 = get_sidra(api='/t/7060/n1/all/v/63/p/all/c315/7171/d/v63%202') alim_dom = full_join(alim_dom_01, alim_dom_02) %>% mutate(date = parse_date(`Mês (Código)`, format="%Y%m")) %>% mutate(alim_12m = acum_p(Valor,12)) %>% select(date, Valor, alim_12m)
Podemos na sequência pegar o IPA Agro diretamente do site do Banco Central usando para isso o pacote BETS.
ipa_agro = BETSget(7460, data.frame = TRUE) %>% mutate(ipa_12m = acum_p(value,12))
Observe que nos códigos acima, eu já crio uma nova variável com a função mutate que acumula os dados em 12 meses. Uma vez tratados os dados, podemos gerar um gráfico como abaixo.
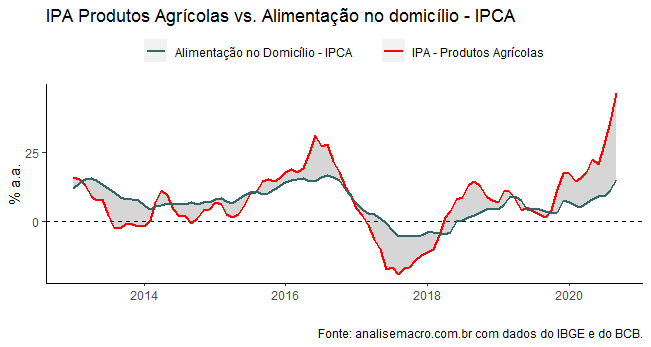
Observe que ao longo da série histórica é comum haver discrepâncias entre um e outro índice. Na margem, contudo, o IPA Agro tem experimentado uma subida bastante expressiva, o que abre a boca de jacaré entre as séries.
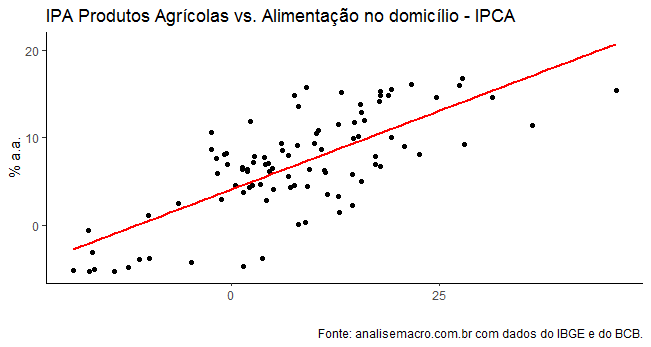
Dada a correlação entre as séries, que também nesse caso implica em causalidade - ver estudo a ser publicado no Clube do Código - existe uma expectativa de repasse da alta do IPA Agro para o consumidor. Isso, por óbvio, irá pressionar a inflação cheia. A conferir, apenas, se o suficiente para gerar alguma pressão sobre a política monetária.
Sempre lembrando que o Banco Central opera a política monetária de modo a conter efeitos secundários de um choque temporário como esse. Isto é, efeitos sobre outros preços, o que caracterizaria uma pressão inflacionária.
_____________________
(*) Para ter acesso aos códigos completos dos nossos exercícios, cadastre-se na nossa Lista VIP aqui.
(**) Inscrições para as Turmas de Verão começam no próximo dia 27/10. Seja avisado por e-mail clicando aqui.

