No Brasil, é comum acompanhar preços de commodities, afinal, qualquer mudança desses ativos afeta a vida dos brasileiros, seja diretamente ou indiretamente, mesmo para quem não atue no mercado financeiro. No post de hoje, vamos mostrar como é possível coletar dados de commodities e visualizá-los no R.
library(quantmod) library(tidyverse) library(timetk)
Após o carregamento dos pacotes, iremos criar os vetores com os tickers dos ativos que iremos coletar. Utilizaremos como fonte o Yahoo Finance, portanto, devemos encontrar os símbolos para a coleta no site.
# Define os tickers que iremos coletar
tickers <- c("KC=F", "NG=F", "CL=F", "SB=F")
Com os símbolos em mãos, podemos retirar os preços a partir do ano de interesse (aqui a partir de 2019), utilizando a função getSymbols(). Em seguida, podemos tratar os dados pegando somente os dados de fechamento e juntando em um só tibble os preços das quatro commodities.
Após isso, transformamos nosso conjunto de dados no formato long, de forma que fique mais fácil utilizar o ggplot para a visualiza-los.
# Retira os preços do Yahoo Finance e realiza o tratamento
prices <- getSymbols(tickers, src = "yahoo",
from = "2019-01-01") %>%
map(~Cl(get(.))) %>%
reduce(merge) %>%
`colnames<-` (c("Coffee Mar 22", "Natural Gas Dec 21", "Crude Oil", "Sugar #11 Mar 22")) %>%
tk_tbl(preserve_index = TRUE,
rename_index = "date") %>%
drop_na()
# Transforma em formato long
prices_long <- prices %>%
pivot_longer(cols = -date,
values_to = "price")
# Plota os preços
prices_long %>%
ggplot(aes(x = date, y = price, colour = name))+
geom_line()+
labs(title = "Preços de Commodities em US$",
x = "$",
y = "",
caption = "Fonte: Yahoo Finance")
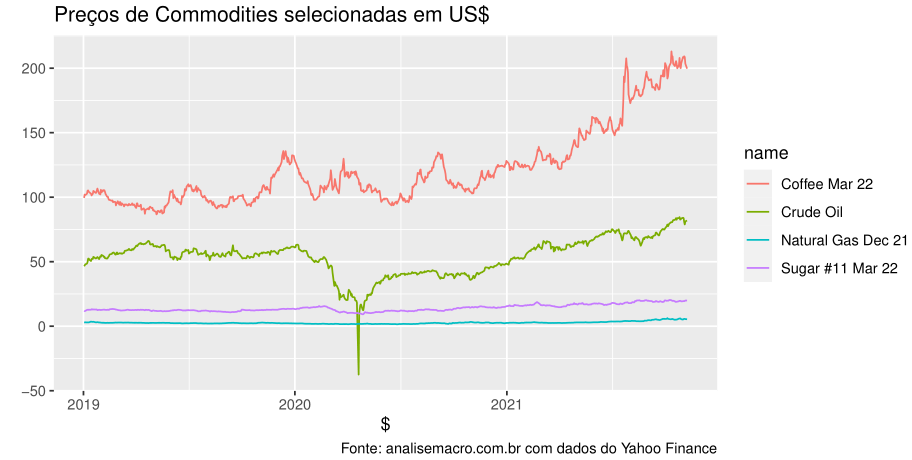
Como podemos ver, houve uma escalada de preços do café no ano de 2021. Também é possível notar o momento em que o preço do petróleo cru ficou negativo em abril de 2020.
________________________
(*) Para entender mais sobre Mercado Financeiro e aprender como realizar a coleta, tratamento e visualização de dados financeiros, confira nosso curso R para o Mercado Financeiro.

