Modelos de Volatilidade foram criados na década de 1980 com o objetivo de refinar o tratamento do risco e da incerteza em um modelo empírico, algo que os modelos de precificação até então tinham dificuldades em lidar. Modelos do tipo ARCH e GARCH fundamentam-se na variância condicional, levando em consideração os eventos extremos das séries financeiras. No post de hoje, iremos demonstrar as aplicação de modelos do tipo GARCH (1.1) no mundo real.
Antes de começarmos com a aplicação e o código, devemos fazer aqui rapidamente algumas considerações sobre os modelos. Para introduzir melhor sobre o assunto, temos um post aqui na Análise Macro explicando os modelos ARCH e GARCH , bem como possuímos o curso de Econometria Financeira usando o R, que ajuda a entender melhor sobre modelagem de séries financeiras.
Consideramos que a previsão média dos retornos dado a informação disponível no tempo  de uma série é calculada como:
de uma série é calculada como:
![$$\mu_t = E[R_t | I_{t-1}]$$](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-c34837c7fc5271c5f7c5db5656f1e760_l3.png "Rendered by QuickLaTeX.com")
Com os erros da previsão sendo

Com base nas informações no tempo  , também é possível calcular a variância:
, também é possível calcular a variância:
![$$\sigma^2 = E[(R_t - \mu_t)^2 | I_{t-1}]$$](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-3a3886349da339216983f61a81db4e8f_l3.png "Rendered by QuickLaTeX.com")
![$$ = E[e^2_t |I_{t_1}]$$](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-b5cef7ef9509a346edcc56f13905cfa5_l3.png "Rendered by QuickLaTeX.com")
Ao realizar a estimação da previsão média dos retornos, podemos realizá-la tanto através de média móvel dos retornos, calculada a partir de:

quanto a partir de um processo ARMA.
O que nos permitirá ter os modelos:
ARCH:

GARCH(1,1)

Estimar a volatilidade do Ibovespa
Podemos aplicar o modelo GARCH(1,1) no índice bovespa, de forma a comparar os diferentes períodos de volatilidade da série. Antes da modelagem, porém, realizamos uma análise de dados dos retornos do índice bovespa. No código abaixo, importamos os pacotes e a série da Ibovespa, transformando os seus preços de fechamentos ajustados em log retornos.
Com os retornos em mãos, realizamos uma análise para ajudar a entender melhor a questão da heterocedasticidade condicional. O gráfico de Q-Q permite avaliar a distribuição empíricas dos quantiles e relação a distribuição teórica, sendo assim, é útil para saber se a distribuição dos retornos segue como normal. Como é interessante de ver, apesar da forma retilínea da distribuição, há valores discrepantes, que chamamos de eventos extremos, o que causa problemas na nossa série. Significa que há momentos dos quais o valores se tornam eventos extremos, afetando a variância (volatilidade) em determinados períodos.
 Um forma interessante de visualizar esses momentos de heterocedasticidade condicional, é visualizando a série do retorno, bem como seu gráfico de autocorrelação, e comparar com os erros ao quadrado (como na equação acima, demonstrando ser a variância da série).
Um forma interessante de visualizar esses momentos de heterocedasticidade condicional, é visualizando a série do retorno, bem como seu gráfico de autocorrelação, e comparar com os erros ao quadrado (como na equação acima, demonstrando ser a variância da série).
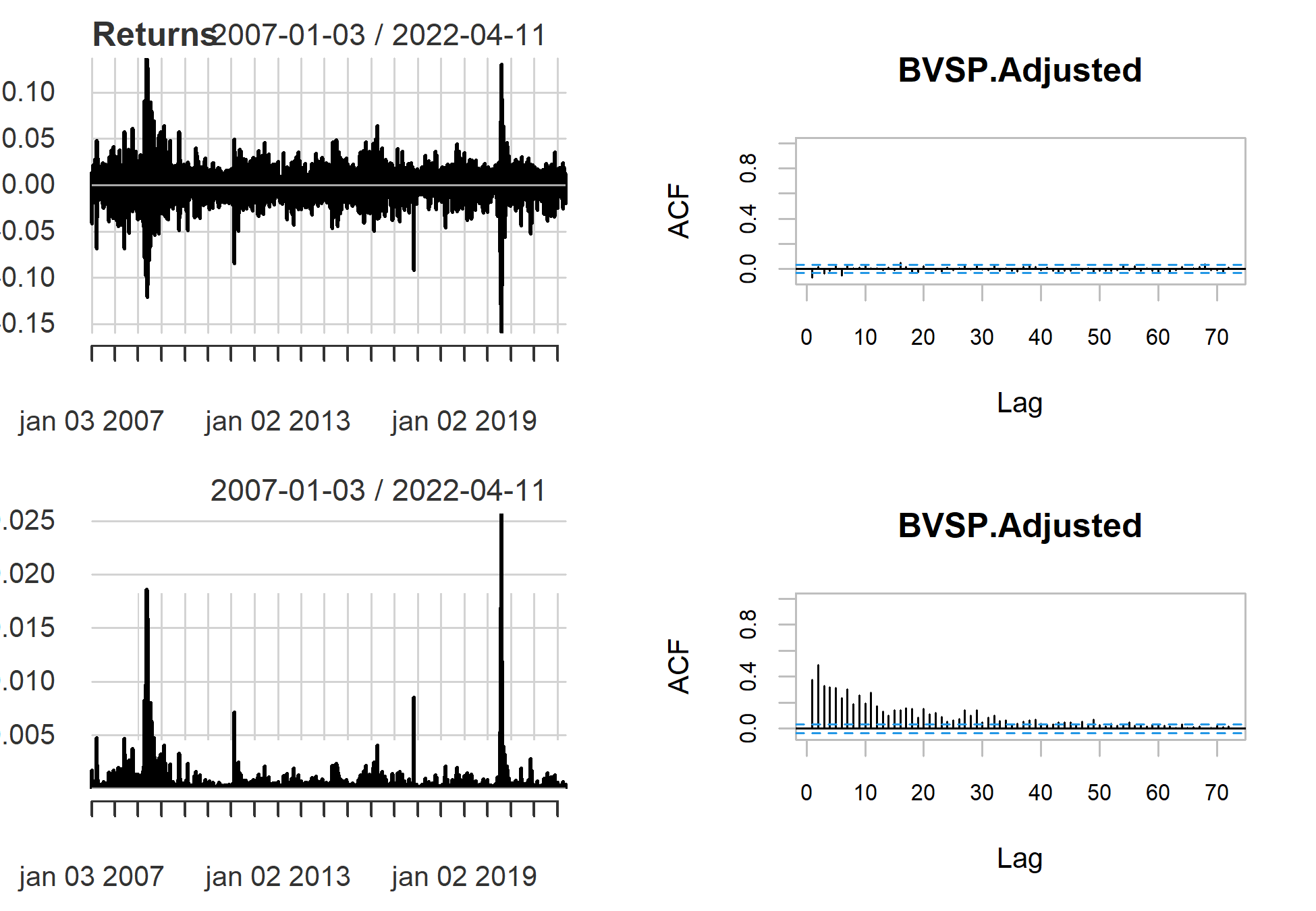
Vemos que há momentos que realmente houveram variações significativas, principalmente em períodos de crises, e que os valores dos erros ao quadrado mostram através do gráfico de autocorrelação, que elas não são independentes no tempo, ou seja, podemos modelar a variância através de seus valores passados.
Abaixo, criamos um gráfico mais sofisticado do desvio padrão anualizado móvel em períodos de 22 dias, de forma a comparar com os erros ao quadrado.

Por fim, é possível melhorar ainda mais a estimação da volatilidade, utilizando o modelo GARCH (1,1) para obter a estimação da variância e da média condicional utilizando o pacote {ugarch}.
O primeiro passo é a especificação o modelo com ugarchspec. Dentre as especificações, escolhemos que o valor previsto do retorno será estimado pela média amostral (armaOrder = c(0,0), lembrando que é possível utilizar modelos ARMA nesse caso). O modelo da variância será o "standard GARCH", e a distribuição será normal.
O segundo passo é calcular as estimativas com base na função ugarchfit, utilizando a especificação que criamos.
O terceiro passo, opcional, é realizar a previsão nos períodos futuros com a função ugarchforecast.
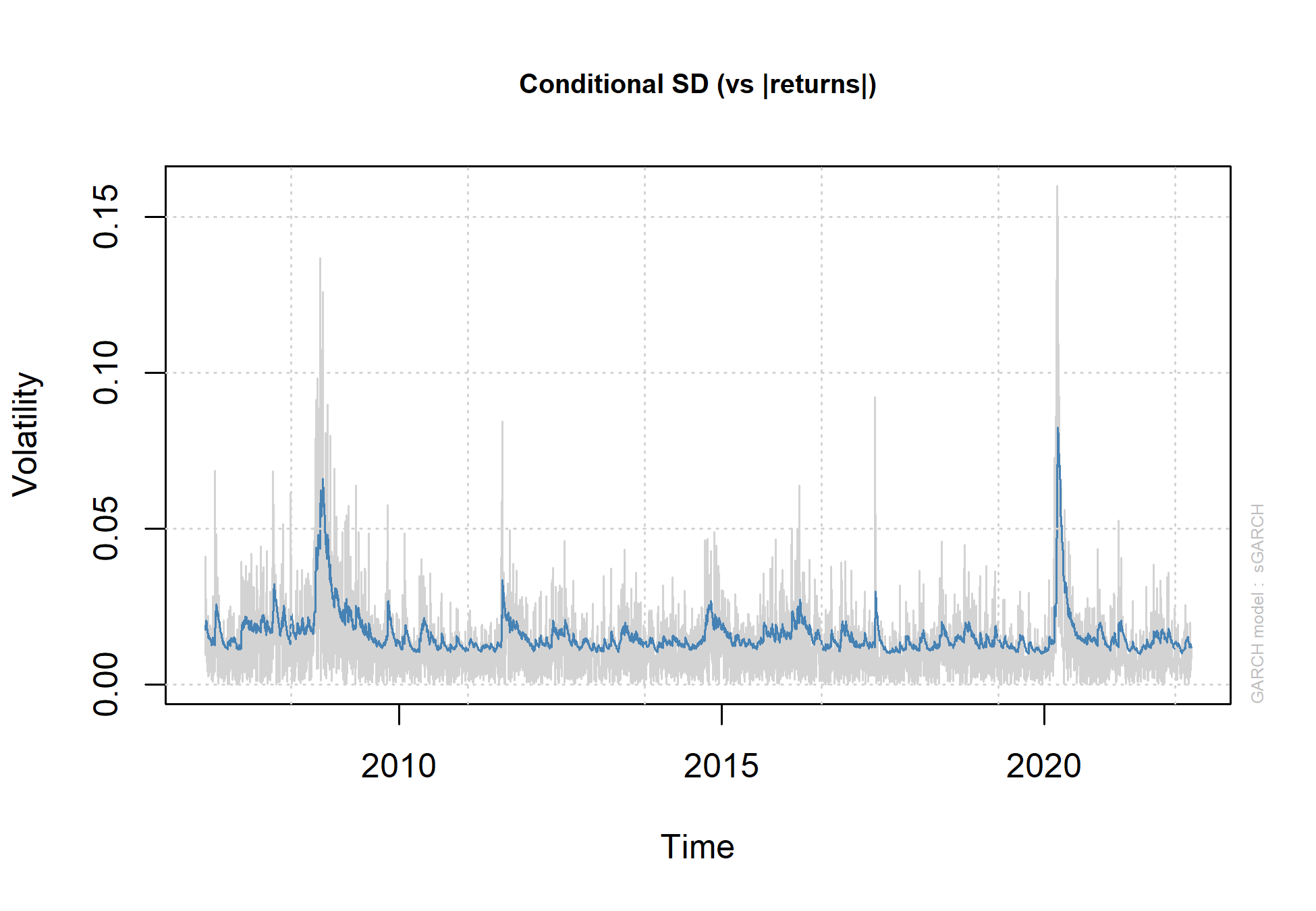
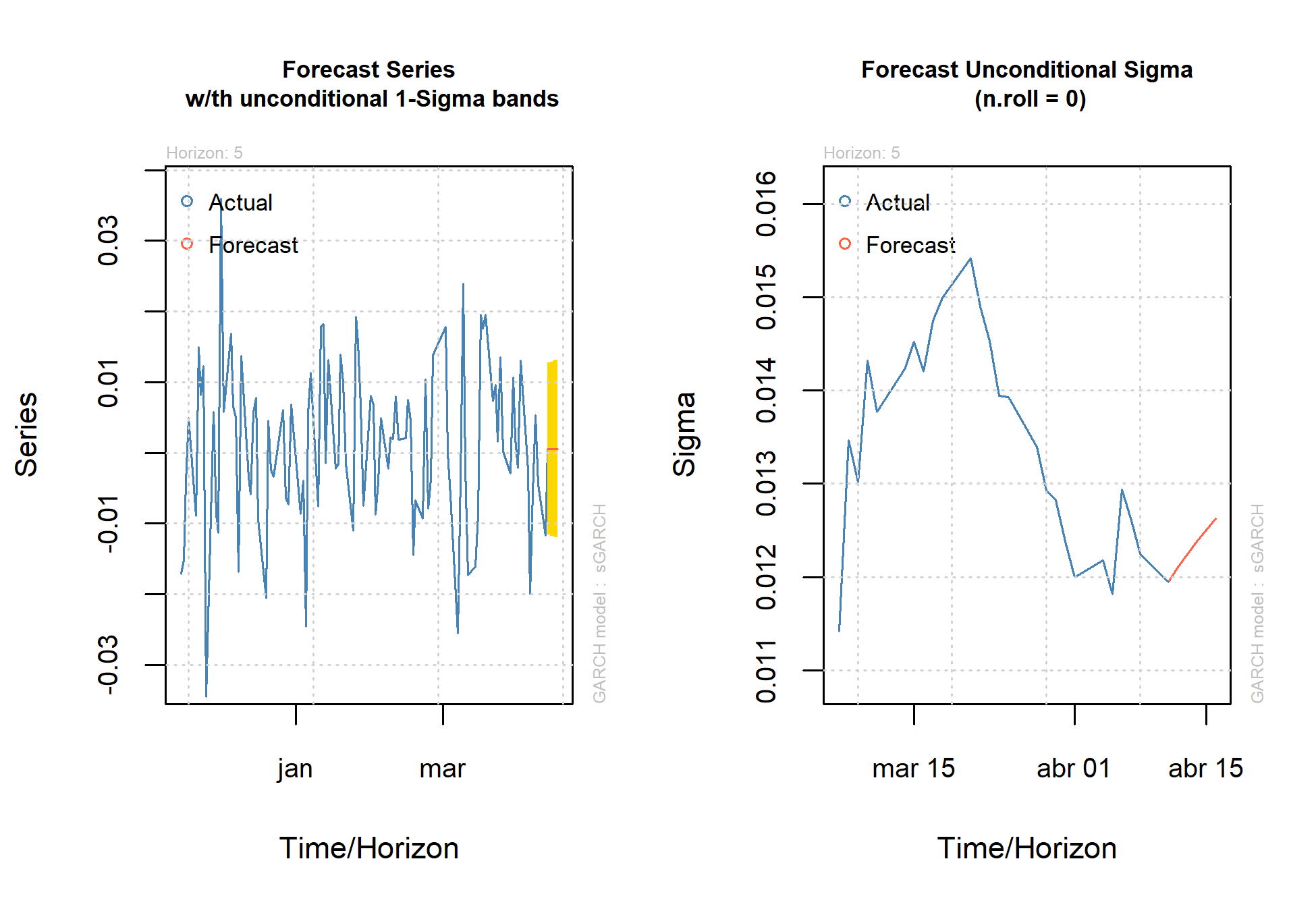
Aplicação da volatilidade: Teorema da separação de Tobin
Podemos utilizar como exemplo o teorema da separação de Tobin (1958), que a grosso modo, estabelece a carteira eficiente de ativos arriscados, e também determina a fração (peso) ótima para investir na carteira de ativos arriscado e no ativo livre de risco.
Se um portfolio investe a porcentagem $w$ em um ativo de risco (com volatilidade  ) e mantêm
) e mantêm  no ativo livre de risco, obtemos uma volatilidade igual a:
no ativo livre de risco, obtemos uma volatilidade igual a:

Como definimos  ? É possível através do volatility targeting. O valor de será aquele que o valor previsto da volatilidade anualizada será igual ao valor do target, sendo então 5%, por exemplo:
? É possível através do volatility targeting. O valor de será aquele que o valor previsto da volatilidade anualizada será igual ao valor do target, sendo então 5%, por exemplo:

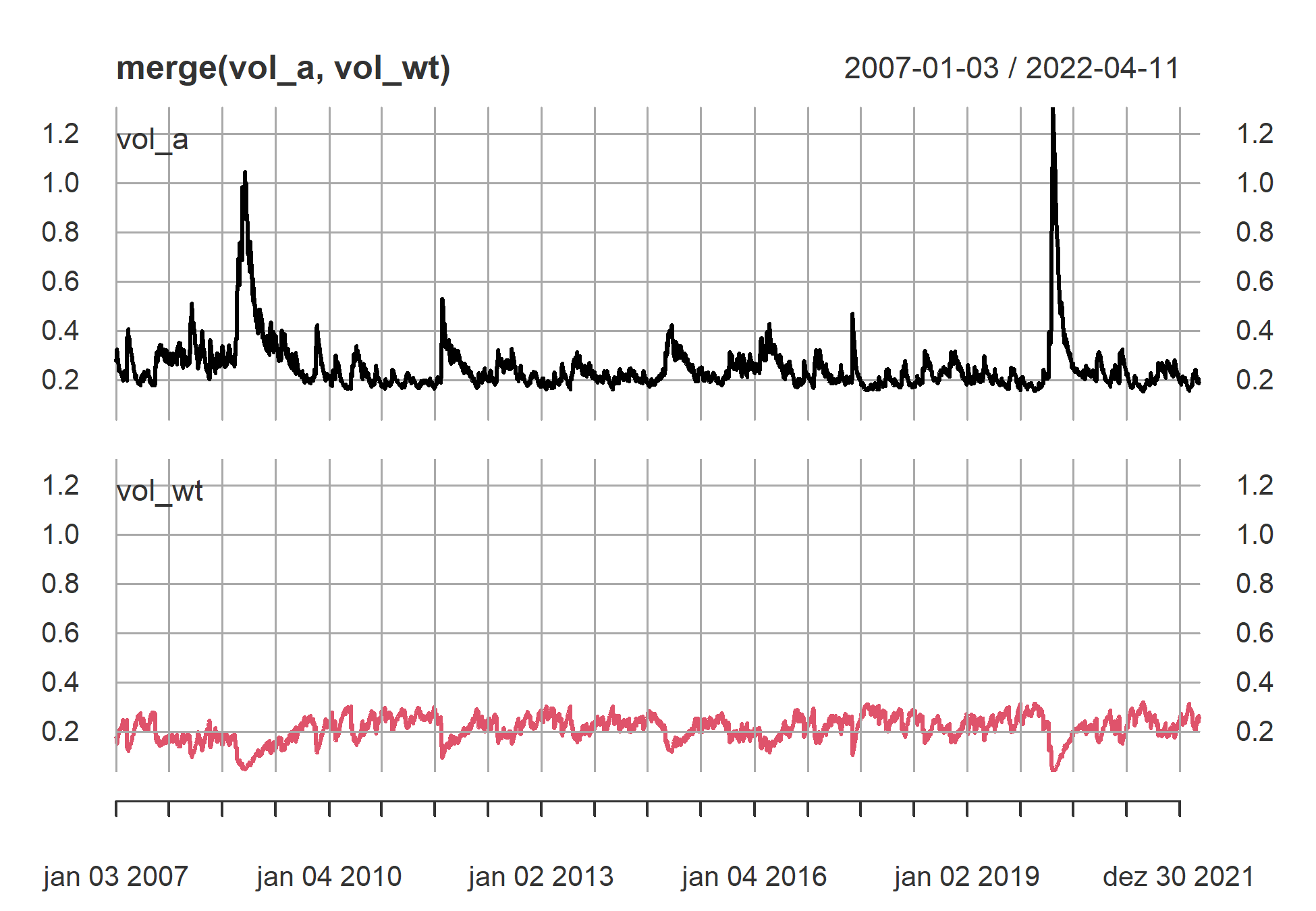
O gráfico demonstra a relação do portfolio e da variância, vemos que quanto maior o nível de volatilidade em certo períodos, menor será a fração no portfolio de ativos de risco.
Referências
James Tobin. Liquidity preference as behavior towards risk. Review of Economic Studies, XXV(2):65–86, February 1958.

