As ferramentas mais poderosas para a Análise de dados com o R estão contidas no pacote {dplyr}, parte da família do {tidyverse}, que proporciona verbs (funções), que ajudam o usuário a resolver problemas de manipulação de dados de forma extremamente simples. Neste post de hoje, mostraremos, através do principais verbs do pacote, como é possível agregar e juntar dados.
Agregação
Agregação de dados é basicamente agregar observações de categorias referenciadas em uma coluna, ou mesmo, agregar diversas colunas, para realizar operações, em geral matemáticas e estatísticas, de forma que possamos resumir informações.
Os dois verbos principais para agregar e realizar operações do {dplyr}, respectivamente, são o group_by() e summarise(). Com group_by(), agrupamos a coluna inserida dentro da função. Em seguida, utilizamos a função summarise(), para escolhermos o nome da nova coluna a ser criada e a referenciamos em conjunto com a função da operação matemática ou estatística que desejamos escolhendo a coluna que queremos aplicar o calculo. Abaixo, utilizamos o dataset iris, que contém amostras sobre tamanhos de sépalas e pétalas de três diferentes espécies de flores como exemplos.
Neste primeiro exemplo, agrupamos as observações da coluna Species, ou seja, agrupamos as três espécies diferentes (categorias das observações), em seguida, utilizamos summarise(), escolhendo o nome da nova coluna, que será mean_petal, e calculamos a média da coluna Petal.Length com mean(). O resultado será a média de Petal.Length para cada espécie.
Nem sempre é necessário utilizarmos summarise, como no exemplo abaixo, no qual a função count() permite calcular a contagem do número de observações do data frame, porém, agrupados pelas categorias de Species.
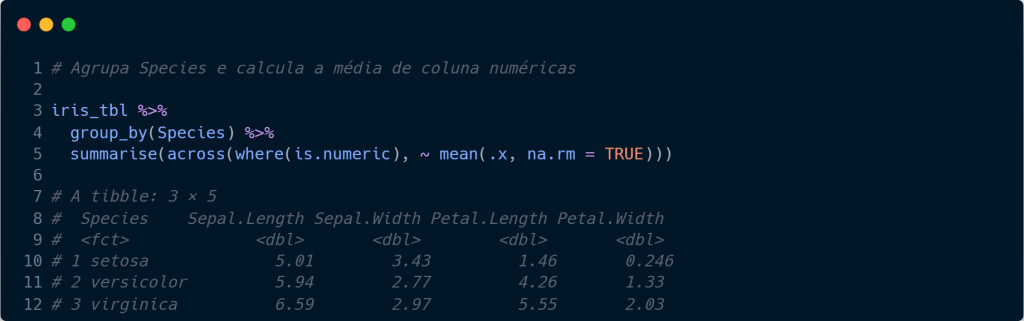
E se quisermos aplicar algum calcular para diversas colunas? Poderíamos nomear e realizar o cálculo dentro de summarise para cada uma, entretanto, não seria viável caso tivéssemos inúmeras colunas para calcular. Para tanto, podemos utilizar a função across(), que permite aplicar a função do cálculo para cada coluna do data frame que escolhermos. Abaixo, escolhemos a coluna Sepal.Length até Petal.Width, utilizando dois pontos (:).
A função across() também permite que sejam aplicadas condições para o cálculo de colunas em conjunto com outros verbs. Vejamos abaixo a utilização de where(), que permite utilizarmos uma condição para a aplicação da função. A condição colocada em where() é de que para toda coluna numérica (is.numeric()), seja aplicado o cálculo da média. O ~ em mean, significa que toda a operação à esquerda do operador seja em função do parte direita, isto é, será aplicado a média para toda a condição satisfeita.
Juntar dados
É quase certeza que ao trabalhar com dados, iremos nos deparar com a missão de juntar data frames. Por sorte, o pacote {dplyr} também nos fornece formas de juntar diferentes data frames. Os verbs utilizados para realizar esse procedimento são conhecidos como _joins(). Cada um com um nome diferente, possuindo um comportamento único.
A ideia principal do _joins é simples: a junção do data frame só pode ocorrer caso eles tenham colunas com observações em comum, de forma que eles sejam relacionais.
Utilizaremos os datasets do pacote {nycflights13}, contendo os datasets flights e airports.
Começaremos selecionando apenas algumas colunas do dataset flights para que possamos diminuir o seu tamanho.
Nosso objetivo aqui será juntar o data frame flights_r com o data frame airports, para que possamos encontrar os voos que se relacionam com os aeroportos através das transportadores aéreas (coluna carrier).
Para juntar as colunas em comum, podemos utilizar o left_join, como o nome diz, juntaremos as observações da coluna do data frame da esquerda, para encaixar na coluna em comum com o data frame da direita. Exemplificando: inner_join(x, y...) Temos que x é o data frame da esquerda, e y é o data frame da direita. Abaixo, juntamos as colunas de flights_r em airlines.
Veja que citamos também o argumento by = "carrier" no segundo exemplo. Esse procedimento é utilizado caso seja necessário especificar o nome da coluna para que a função reconhece qual desejamos juntar.
Caso quisermos realizar o procedimento contrário de left_join(), utilizamos o right_join(). Abaixo o exemplo possui um resultado similar, a diferença é que está sendo juntado as observações da direita na da esquerda.
E caso quisermos juntar os dados em comum de ambos os data frame, sem exceção? Podemos utilizar o verb inner_join(). Abaixo, utilizando os data sets band_members e band_instrument, juntamos a coluna name, para observações em comum de ambos os data frames.
E para juntar todos os dados? Podemos utilizar o verb full_join, abaixo, juntamos todos os dados de band_members e band_instruments2, veja que desta vez especificamos a coluna para ser juntada, devido ao fato de que band_instruments2 possui a coluna de nomes diferentes.
Quer saber mais?
Veja nossos cursos de R e Python aplicados para a Análise de Dados e Economia
- R para Análise de Dados
- Python para Análise de Dados
- Gráficos com ggplot2
- Estatística usando R e Python
- Machine Learning usando o R
_____________________________________________

