A Política Fiscal possui papel significativo na política econômica de um país, atuando na provisão de bens públicos, na minimização de recessões econômicas e como fonte de redistribuição de renda. Portanto, é necessário a compreensão dos principais indicadores fiscais do país, realizando uma análise de dados dessas estatísticas de forma a entender a conjuntura econômica. Neste post de hoje, ensinaremos a capturar os dados do resultado nominal, juros nominal e do resultado primário do Brasil utilizando o Python.
Para exercer uma politica fiscal, um governo necessita de instrumentos do lado da despesa (gasto público) e da receita (arrecadação tributária). Do confronto entre esses dois indicadores, é possível entender se um país, em determinado período, incorreu de superávits ou déficits, cada qual possuindo uma implicação e efeitos em outras variáveis macroeconômicas de curto e longo prazo.
Para averiguar os resultados fiscais do Brasil, podemos buscar as Estatísticas Fiscais disponibilizadas pelo Banco Central. É através do banco de dados da entidade que obteremos os resultados do Setor Público Consolidado (governo central, isto é, formado pelo governo federal, estados, munícipios e estatais). Dentre os indicadores que buscaremos, serão:
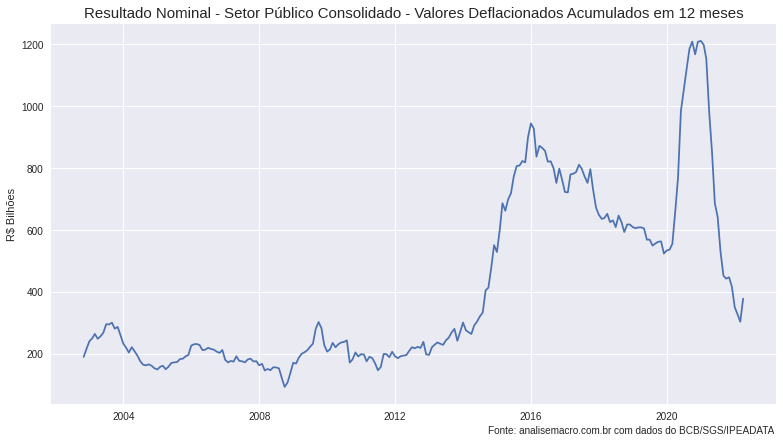
- Resultado nominal - Total - Setor público consolidado (sem desvalorização cambial): representa a variação nominal dos saldos da dívida liquida, fornecendo também informações sobre o confronto entre receitas e despesas totais, ou seja, se houve superávit ou déficit.
- Juros Nominais - Total - Setor público consolidado (sem desvalorização cambial): representa o fluxo de juros, incidentes sobre a dívida interna e externa do pais,. É determinado pelo nível da taxa de juros nominal e pela dimensão do estoque da dívida.
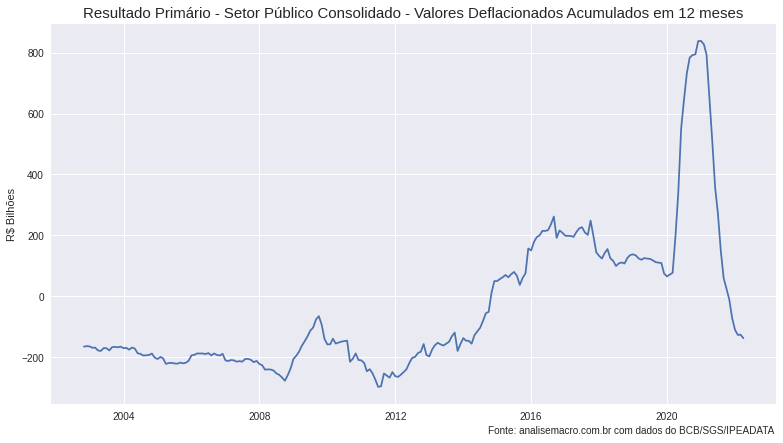
- Resultado Primário - Total - Setor público consolidado (sem desvalorização cambial): corresponde ao resultado nominal menos o juros nominais. É equivalente também da diferença entre as receitas primárias e despesas primárias.
Para capturar os indicadores, utilizaremos a biblioteca python-bcb, que nos fornecerá o módulo sgs, que nos permitirá buscar dados do Sistema Gerenciador de Séries Temporais. É através do códigos fornecidos pelo Sistema que poderemos importar os dados direto no python. Para aprender como é possível utilizar a biblioteca, veja o post Coletando dados do Banco Central com Python.
Uma vez coletados os dados das Estatísticas Fiscais, poderíamos utilizados para realizar a análise e tomar interpretações econômicas, entretanto, os dados estão a preços de mercado, portanto, é interessante antes de qualquer estudo deflacionar os dados e entender como as séries foram representadas ao longo do tempo.
Para tanto, podemos buscar a série do IPCA para que possamos deflacionar os dados. Utilizamos a biblioteca ipeadatapy para capturar os dados do IPCA. Para entender mais sobre a biblioteca, veja o post Coletando dados do IPEADATA com Python .
Com os dados em mãos, aplicamos o cálculo de deflacionamento na série das Estatísticas Fiscais. É possível entender mais sobre esta questão no post Deflacionando dados no Python. Após a construção do deflator, o multiplicamos com os valores dos dados utilizando o método mult().
Por fim, utilizamos o método rolling() e sum() para criar uma janela móvel de 12 meses para que seja feito a soma dos valores. Essa acumulação é útil para que possamos interpretar os caminhos dos resultados fiscais em um período de tempo maior, ao invés de nos ater a períodos de curto prazo.
Podemos enfim analisar os resultados das estatísticas fiscais por meio de gráficos, abaixo, plotamos as séries utilizando o seaborn e o matplolib.

________________________________________
Quer saber mais?
Veja nossos cursos de Macroeconomia através da nossa trilha de Macroeconomia Aplicada.

