Data wrangling é o processo de transformar e manipular dados em formatos "crus" para outro formato com a intenção de entregar as informações contidas no dados em informação útil, sendo o processo necessário para a construção de gráficos, estatísticas descritivas e também para a modelagem. O objetivo do processo é assegurar a qualidade e a usabilidade dos dados. Neste post, apresentaremos os principais métodos e funções de Data Wrangling com a linguagem.
Existem funções que facilitam o processo de data wrangling, permitindo que a partir de um data frame, o usuário o transforme em um formato útil. As principais funções estão contidas no pacote dplyr, também chamadas de verbs. Alguns verbs uteis são:
- filter() - permite que seja filtrado as linhas/observações de um data frame de acordo com uma condição;
- summarize() - sumariza uma ou mais colunas/variáveis, permitindo calcular uma estatísticas por meio de grupos;
- group_by() - agrupa as linhas de acordo com um mesmo grupo/categorias. É utilizado em conjunto com summarize() de forma que seja possível calcular as estatísticas de um grupo separadamente;
- mutate() - utiliza colunas existentes do data frame para criar novas colunas;
- arrange() - permite ordenar as linhas em ordem ascendente ou descendente;
- recode() - permite alterar o nome das observações de uma coluna;
- select() - seleciona as colunas especificadas (também permite alterar seus nomes).
Veja que os verbs são fáceis de lembrar por conta de que seus nomes remetem ao seu verdadeiro proposito. Há também a similaridade do nomes dos verbs com as funções da linguagem SQL.
Uma questão importante da utilização dos verbs são os operadores pipes (%>% ou |>). Estes operadores permite "acorrentar" o uso das funções e seus resultados, de forma que facilite o uso do código, bem como a leitura. O pipe é colocado a frente da linha do código de um determinada função e em seguida, "coloca" o resultado do código da linha no primeiro argumento da função da segunda linha. Veremos adiante nos exemplos melhor como funciona o pipe.
Para mostrar o uso destas funções, utilizaremos como exemplo os dados de mercado de trabalho do Brasil, coletando-os através do Sidra. O propósito será mostrar que a partir de um data frame importado em formato "cru" e "sujo", podemos utilizar as funções citadas para realizar a sua transformação.
Abaixo, os dois pacotes que iremos utilizar: {sidrar} para coletar os dados e {dplyr} para o data Data wrangling.
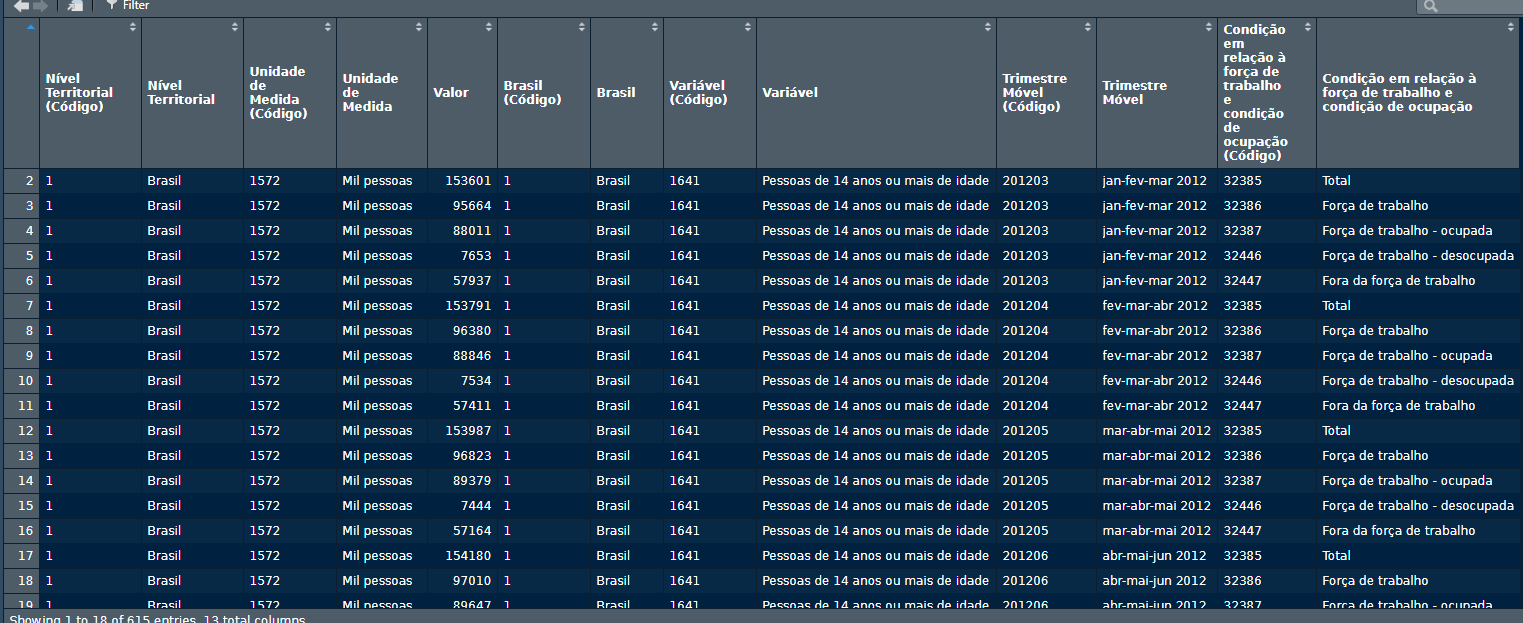
No código abaixo, importados os dados para demonstração. Não há necessidade de entender esse processo, apenas o resultado do data frame na imagem. Veja que o data frame está "sujo", com os tipos de dados reconhecidos de forma errada, colunas desnecessárias, observações com pouca informação útil.
Para começar o processo de Data wrangling, iniciamos com a função select(), selecionando apenas as colunas de interesse, e de quebra, alterando os nomes das colunas para um mais simplificado. Veja a utilização do pipe (|>). O seu propósito nesse pedaço de código foi colocar o objeto "raw_ocupados_desocupados" dentro do primeiro argumento da função select(). Também é utilizado para colocar o resultado da função select() dentro da função as_tibble(), este alterando a classe do objeto para tibble.
Em seguida, iremos alterar o tipo do dado da coluna date, uma vez que o R não a reconheceu adequadamente, e utilizar a função recode() para alterar as observações da coluna variable. Para realizar estas alterações, utilizamos a função mutate(), renomeando as colunas para o seu mesmo nome (para não criar um nova coluna com formato diferente). Para alterar o tipo da coluna date, utilizamos a função ym() do pacote {lubridate}. Também dividimos o valor da coluna value por 1000.
Para alterar as linhas do data frama dada certa condição, utilizamos a função filter(). No caso, queremos apenas dados após a data de 01-01-2015. Utilizamos o operador > para dizer que queremos valores maiores que a data citada.
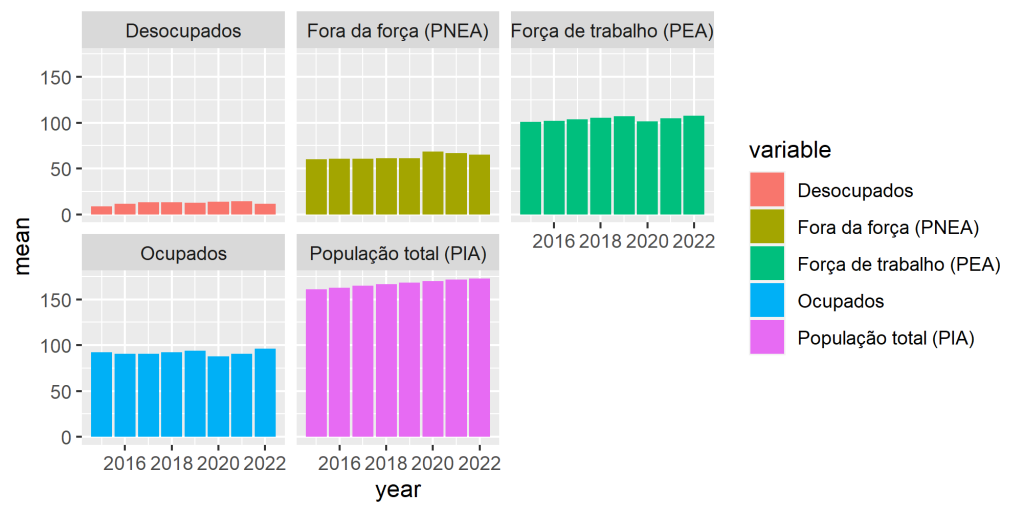
Por fim, podemos calcular a média de cada ano de acordo com cada categoria do data frame. Para isso, agrupados os dados com group_by. Veja que o agrupamento é feito transformando as data mensais em ano com a função year do pacote {lubridate} e identificando a coluna variable. Em seguida, a função summarize permite calcular a média da coluna value para esses linhas agrupadas.
O resultado pode ser visto abaixo, utilizando o pacote ggplot2 para criar um gráfico de forma a verificar o aumento dos valores ao longos dos anos.

______________________
Quer saber mais?
Veja nossos cursos de R e Python aplicados para a Análise de Dados e Economia

