Uma dúvida comum para iniciantes e até mesmo intermediários no estudo de Análise de dados é: como juntar diferentes data frames? quais os métodos que são possíveis de utilizar? No post de hoje, pretendemos responder estas dúvidas, mostrando as formas de realizar esse processo utilizando a biblioteca pandas do Python.
Devemos separar alguns pontos antes de entender como juntar data frames no Python.
Juntar dados pode ser realizado de duas formas: junção por meio de linhas (é como colocar um data frame encima do outro, empilhando as linhas) e junção de data frames por meio de dados relacionais, isto é, juntar os data frames que possuem uma coluna "chave" (com os mesmos valores). Usuários da linguagem SQL podem aprender rápido nesse caso, devido as similares dos métodos.
Concatenar
Concatenar permite juntar os data frames por meio das linhas, empilhando um data frame sobre o outro, utilizando os índices como localização. Vejamos o exemplo abaixo. Criamos dois data frames que possuem as mesmas colunas, porém, com valores diferentes.
A função cocat() permite fazer a junção das linhas passando uma lista de data frames como argumento. Como a localização do índice é quem manuseio os lugares, veja que como não havíamos identificado na criação dos data frame a ordem, acaba gerando um índice totalmente desorganizado, com valores 0,1,2,3,0,1,2,3.
Para evitar esse problema, utiliza-se o argumento ignore_index = True. Veja a diferença abaixo.
Juntar os dados
Para juntar os dados de forma relacional, podemos utilizar as funções merge() e join().
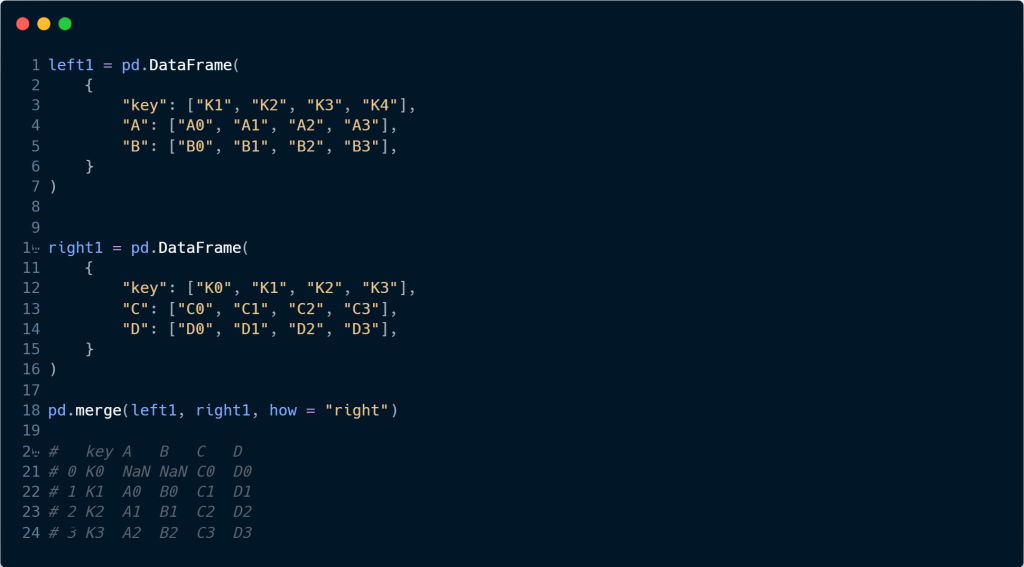
Veja o exemplo abaixo, construímos dois data frames possuindo dados diferentes, porém, com uma coluna "key" (chave) idênticas para que seja possível juntar os data frames.
Por meio da função merge(), inserimos os dois data frames como argumento, e especificamos qual a coluna que irá ser a chave por meio do argumento on = "key".
E se as colunas chave não forem totalmente idênticas? Podemos especificar se queremos juntar com o argumento how = . Entre as 3 mais comuns: left permite juntar com base na chave do data frame da "esquerda" (a primeira utilizada no argumento da função); right permite juntar com base na chave do data frame da "direita"; inner permite juntar com base na chave comum, retirando todos os possíveis NAs.
Vejamos o exemplo abaixo, com a função merge(), especificamos que os data frames abaixo (que possuem chaves diferentes) se juntem pela chave do data frame da direita (right1).
Repetimos o processo novamente, entretanto, especificando o data frame da esquerda com how = "left". Veja a diferença do resultado.
E se ao invés de colunas, quisermos juntar por meio dos valores do índices do data frame? Isto é, o índice como chave.
De forma simples e rápida, utiliza-se join(), que aplica como um método do data frame e utiliza o outro data frame como argumento. Veja que a escolha de left ou right é automática para left.
Apesar de automático, podemos ainda alterar a forma de junção por meio do argumento how = .
Com a função merge() também podemos especificar que queremos juntar com o índice como chave. Para isso, devemos identificar os argumentos right_index e left_index igual a True.
Por fim, podemos resolver um problema com dados reais. Abaixo importamos dados de preços da ação ITUB4 e da Ibovespa e data frames separados. Queremos juntar os dois data frames. Como fazemos isso?
No caso, ambos data frames possuem o índice em comum, que neste caso, possuem os valores da data, referentes ao dia de cada preço da ação. Escolhemos juntar por meio a função merge(), identificando os índices com left_index e right_index e a forma de junção como "inner".
Ainda existem muitas ferramentas que podem auxiliar neste processo de junção de dados no Python, mas espero que essa introdução seja suficiente para aqueles que possuem dúvidas.
Quer saber mais?
Veja nossos cursos de R e Python aplicados para a Análise de Dados e Economia
- R para Análise de Dados
- Python para Análise de Dados
- Gráficos com ggplot2
- Estatística usando R e Python
___________________
Referências
Pandas User Guide: Merge, join, concatenate and compare.

