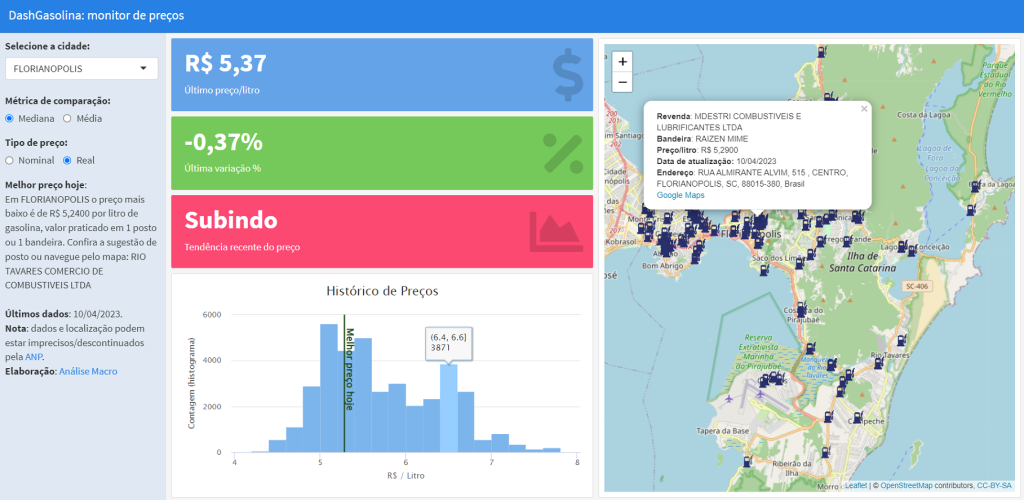
O ciclo de análise de dados é uma poderosa metodologia de trabalho para resolver problemas através de dados. Com ela podemos ter uma visão geral sobre as etapas do processo, o que é fundamental para não se perder no caminho. Mas apenas ter essa compreensão não é suficiente, é preciso dar o próximo passo: colocar em prática uma análise de dados.
É trabalhando na execução de um projeto de análise de dados que conseguimos aprender ou fixar o conhecimento sobre conceitos, métodos, ferramentas e etc. que são, as vezes, um tanto quanto abstratos. Neste artigo vamos colocar em prática o ciclo de análise de dados, de ponta a ponta, do início ao fim, para tornar mais tangível esse mundo através de exemplos que podem servir de base para outros projetos.
Recapitulando, o ciclo de análise de dados possui, em resumo, as 6 etapas ilustradas na imagem abaixo: definição de problema/objetivo; identificação e coleta de dados; pré-processamento e análise exploratória de dados; proposta de solução com modelos, previsão, etc.; validação da solução; e implantação da solução ou tomada de decisão.
Tomaremos esse ciclo como o caminho a ser percorrido para implementar uma análise de dados, que pode ser muito simples ou bastante complexa. A experiência de especialistas da área nos diz que se algo está ficando muito complexo, pode ser que tenha sido tomado um caminho desnecessário. Acreditamos que esse é um conselho valioso e tentaremos manter este exercício o mais simples possível, ao mesmo tempo que prezaremos por uma boa qualidade de análise de dados. Sinta-se livre para aperfeiçoar esse projeto, se você achar que está muito simples.
Boa leitura!
Definição de problema e objetivos
Estamos no início de um projeto de análise de dados, portanto precisamos definir o pilar sobre o qual desenvolveremos todo o trabalho: um problema a ser resolvido e/ou objetivos a serem alcançados. É necessário ter esse norte para entregar valor em uma análise de dados.
Vamos fugir do "tradicional" e evitar o uso de projetos e conjuntos de dados já saturados (titanic, iris e seus irmãos). Afinal, você quer que seu trabalho se destaque na multidão, certo? Então vale mais a pena focar em resolver problemas reais e presentes no cotidiano da nossa sociedade, assim podemos "unir o útil ao agradável".
Olhando hoje para o Brasil e sua sociedade, quais problemas são mais evidentes e que poderíamos desenvolver uma solução, ao menos em partes, baseada em dados? Bom, podemos listar vários desafios interessantes de diversos contextos e magnitudes no Brasil, dentre eles alguns da área econômica:
- O novo "arcabouço fiscal" e o controle das contas públicas
- O nível de taxa de juros e o crescimento da economia
- A movimentação do dólar e o impacto na inflação
- Os preços de combustíveis e o orçamento das famílias
São temas atuais e relevantes para trabalhar em uma análise de dados. Tomando como base o princípio da simplicidade destacado anteriormente, vamos escolher o tema "Os preços de combustíveis e o orçamento das famílias" para este projeto de análise de dados. Mas qual seria o problema a ser resolvido ou objetivos a serem alcançados?
A definição do problema a ser resolvido requer o conhecimento ou expertise na área de atuação. No caso dos preços de combustíveis sabemos que, com base na teoria econômica, pode existir o problema da informação assimétrica. Esse problema se refere a quando, em uma transação, uma das partes possui mais ou melhor informação do que a outra, o que pode criar um desequilíbro no poder de negociação.
No caso do preço dos combustíveis, o dono do posto provavelmente possui mais e melhor informação do que o cliente que apenas vai abastecer seu veículo. O dono do posto define o preço do combustível com base em diversas variáveis e o preço na concorrência pode ser uma delas. O cliente, geralmente, abastece seu veículo no posto mais próximo e não possui conhecimento sobre o preço praticado no próximo posto. Assim, o dono de um posto pode praticar preços maiores do que a concorrência explorando a assimetria de informação do cliente. Essa é uma situação do cotidiano do brasileiro: o carro acusa que está na reserva, o motorista para no posto A e abastece, roda mais alguns quilômetros e descobre que no posto B o preço era menor. ?
Então vamos tentar resolver esse problema: reduzir a assimetria de informação referente ao preço de combustíveis. E utilizaremos a análise de dados com o objetivo de que haja menos surpresas no orçamento familiar do motorista e cliente de posto. Isso é extremamente relevante pois, por exemplo, a gasolina representa 4,7% do orçamento mensal das famílias brasileiras, conforme dados do IPCA/IBGE de março/2023, constituindo o subitem de maior peso dentro da cesta de produtos e serviços considerados na pesquisa.
Identificação e coleta de dados
Existem dados sobre o problema que queremos analisar? Onde os dados estão disponibilizados? Como os dados podem ser coletados? Os dados são confiáveis?
Essas são apenas algumas das perguntas pertinentes nesta etapa do ciclo de análise de dados. Felizmente, os dados de preços de combustíveis existem no Brasil e são disponibilizados publicamente para livre acesso pela ANP. No site é possível encontrar arquivos de dados sobre combustíveis de automotivos e gás de botijão, agregados por semestre, mês ou semana. Além disso a agência ainda disponibiliza o metadados, que é uma boa prática e ajuda a entender os dados.
Agora que identificamos os dados, vamos definir o que precisamos para a análise e prosseguir para a coleta de dados. Para simplificar, vamos restringir a nossa análise aos dados do combustível gasolina comum e somente para um estado, vamos escolher Santa Catarina como exemplo.
Para coletar os dados, e para as demais etapas do projeto, vamos utilizar a linguagem de programação R. Na prática, é possível utilizar qualquer linguagem moderna para ciência de dados, como R e Python, pois independentemente da escolha é possível atingir o mesmo resultado, ou algo muito semelhante.
Abaixo estão os arquivos de dados coletados (preços nas últimas 4 semanas, preços históricos até o semestre anterior ao atual e preços no semestre atual, conforme a página da ANP disponibiliza):
Código
# Listar arquivos
list.files("dados/bruto", full.names = TRUE) [1] "dados/bruto/ca-2004-01.csv"
[2] "dados/bruto/ca-2004-02.csv"
[3] "dados/bruto/ca-2005-01.csv"
[4] "dados/bruto/ca-2005-02.csv"
[5] "dados/bruto/ca-2006-01.csv"
[6] "dados/bruto/ca-2006-02.csv"
[7] "dados/bruto/ca-2007-01.csv"
[8] "dados/bruto/ca-2007-02.csv"
[9] "dados/bruto/ca-2008-01.csv"
[10] "dados/bruto/ca-2008-02.csv"
[11] "dados/bruto/ca-2009-01.csv"
[12] "dados/bruto/ca-2009-02.csv"
[13] "dados/bruto/ca-2010-01.csv"
[14] "dados/bruto/ca-2010-02.csv"
[15] "dados/bruto/ca-2011-01.csv"
[16] "dados/bruto/ca-2011-02.csv"
[17] "dados/bruto/ca-2012-01.csv"
[18] "dados/bruto/ca-2012-02.csv"
[19] "dados/bruto/ca-2013-01.csv"
[20] "dados/bruto/ca-2013-02.csv"
[21] "dados/bruto/ca-2014-01.csv"
[22] "dados/bruto/ca-2014-02.csv"
[23] "dados/bruto/ca-2015-01.csv"
[24] "dados/bruto/ca-2015-02.csv"
[25] "dados/bruto/ca-2016-01.csv"
[26] "dados/bruto/ca-2016-02.csv"
[27] "dados/bruto/ca-2017-01.csv"
[28] "dados/bruto/ca-2017-02.csv"
[29] "dados/bruto/ca-2018-01.csv"
[30] "dados/bruto/ca-2018-02.csv"
[31] "dados/bruto/ca-2019-01.csv"
[32] "dados/bruto/ca-2019-02.csv"
[33] "dados/bruto/ca-2020-01.csv"
[34] "dados/bruto/ca-2020-02.csv"
[35] "dados/bruto/ca-2021-01.csv"
[36] "dados/bruto/ca-2021-02.csv"
[37] "dados/bruto/ca-2022-02.csv"
[38] "dados/bruto/ca-2022-02.zip"
[39] "dados/bruto/precos-gasolina-etanol-01.csv"
[40] "dados/bruto/precos-gasolina-etanol-02.csv"
[41] "dados/bruto/precos-gasolina-etanol-03.csv"
[42] "dados/bruto/precos-semestrais-ca-2022-01.csv"
[43] "dados/bruto/precos-semestrais-ca.zip"
[44] "dados/bruto/ultimas-4-semanas-gasolina-etanol.csv"Pré-processamento e análise exploratória de dados
Como pode ser visto, os dados da ANP são disponibilizados em formato CSV, sendo alguns arquivos compactados como ZIP. No total os arquivos ocupam cerca de 4GB de armazenamento local e há, possivelmente, milhões de linhas e 16 colunas (conforme os metadados) no total. Por que essas informações são importantes? Porque o tamanho dos dados que estamos lidando determina diretamente a abordagem utilizada para processar e analisar estes dados, que é o objetivo desta etapa do ciclo. Se tivéssemos alguns milhares ou centenas de milhares de linhas nesses arquivos tabulares, a solução de processamento de dados mais simples já seria o suficiente, como as utilidades disponíveis no tidyverse ou data.table, mas não é esse o caso.
Para processar esses dados vamos utilizar, dentre várias opções, uma ferramenta moderna chamada Apache Spark, que possui uma integração no R. É uma ferramenta para processar Big Data de maneira eficiente e distribuída, sem que precisamos ter um super computador ou pagar por um serviço de computação na nuvem. Podemos fazer tudo localmente, ao menos para a quantidade de dados que temos até o momento neste projeto. Em computadores com 8GB de memória RAM o procedimento a seguir deve ser executado sem problemas!
Abaixo realizamos o pré-processamento de dados com o Apache Spark no R, resultando em uma tabela filtrada com os dados de interesse (preço da gasolina em postos de Santa Catarina):
Código
Rows: ??
Columns: 12
Database: spark_connection
$ municipio <chr> "PINHALZINHO", "APIUNA", "ARARANGUA", "ARARANGUA"…
$ revenda_nome <chr> "BONETTI COMERCIO DE COMBUSTIVEIS LTDA", "POSTO A…
$ revenda_cnpj <chr> " 02.574.558/0001-06", " 83.488.882/0009-60", " 0…
$ endereco_logradouro <chr> "AVENIDA BRASILIA", "AVENIDA QUINTINO BOCAIUVA", …
$ endereco_numero <chr> "160", "269", "707", "21", "8150", "SN", "S/N", "…
$ endereco_complemento <chr> NA, NA, NA, "SALA 01", NA, "ESQ. RODOVIA SC 499",…
$ endereco_bairro <chr> "EFACIP", "CENTRO", "ALTO FELIZ", "CENTRO", "MORR…
$ endereco_cep <chr> "89870-000", "89135-000", "88905-090", "88900-000…
$ data_coleta <date> 2004-07-06, 2004-07-06, 2004-07-06, 2004-07-06, …
$ valor_venda <chr> "2,09", "2,169", "2,239", "2,24", "2,23", "2,22",…
$ unidade_medida <chr> "R$ / litro", "R$ / litro", "R$ / litro", "R$ / l…
$ bandeira <chr> "BRANCA", "CBPI", "LIQUIGÁS", "BRANCA", "IPIRANGA… Como resultado, agora temos uma tabela de dados praticamente prontos para serem analisados. Além disso, os dados estão salvos em um formato bem compacto (Parquet).Após processar os dados, podemos prosseguir com a análise exploratória. O objetivo é ter uma visão geral sobre os dados, visando conhecer as principais características das variáveis que estamos trabalhando. Isso inclui, por exemplo, dentre várias outras análises que podem ser feitas:
- Analisar a distribuição das variáveis
- Verificar a presença de observações rotuladas como dados faltantes
- Verificar padrões de tendência, sazonalidade, etc.
Ao investigar os dados conseguimos levantar informações relevantes que podem ser úteis nas análises que se seguirão. Dessa forma, um olhar geral sobre a distribuição das variáveis é apresentado na tabela e nos gráficos abaixo:
| Name | dados |
| Number of rows | 323824 |
| Number of columns | 13 |
| _______________________ | |
| Column type frequency: | |
| character | 9 |
| Date | 2 |
| numeric | 2 |
| ________________________ | |
| Group variables | None |
Variable type: character
| skim_variable | n_missing | complete_rate | min | max | empty | n_unique | whitespace |
|---|---|---|---|---|---|---|---|
| municipio | 0 | 1.00 | 5 | 19 | 0 | 33 | 0 |
| revenda_nome | 0 | 1.00 | 12 | 92 | 0 | 1265 | 0 |
| revenda_cnpj | 0 | 1.00 | 19 | 19 | 0 | 1495 | 0 |
| endereco_logradouro | 0 | 1.00 | 8 | 59 | 0 | 767 | 0 |
| endereco_numero | 0 | 1.00 | 1 | 8 | 0 | 739 | 375 |
| endereco_complemento | 238154 | 0.26 | 1 | 84 | 0 | 223 | 4372 |
| endereco_bairro | 521 | 1.00 | 3 | 33 | 0 | 440 | 0 |
| endereco_cep | 0 | 1.00 | 9 | 9 | 0 | 809 | 0 |
| bandeira | 0 | 1.00 | 3 | 28 | 0 | 60 | 0 |
Variable type: Date
| skim_variable | n_missing | complete_rate | min | max | median | n_unique |
|---|---|---|---|---|---|---|
| data_coleta | 0 | 1 | 2004-05-10 | 2023-04-13 | 2011-07-13 | 3632 |
| mes_coleta | 0 | 1 | 2004-05-01 | 2023-04-01 | 2011-07-01 | 226 |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| valor_venda | 0 | 1 | 3.09 | 0.95 | 1.77 | 2.55 | 2.70 | 3.38 | 7.89 | ▇▂▁▁▁ |
| valor_real | 379 | 1 | 5.70 | 0.67 | 3.94 | 5.15 | 5.56 | 6.27 | 8.15 | ▁▇▅▂▁ |
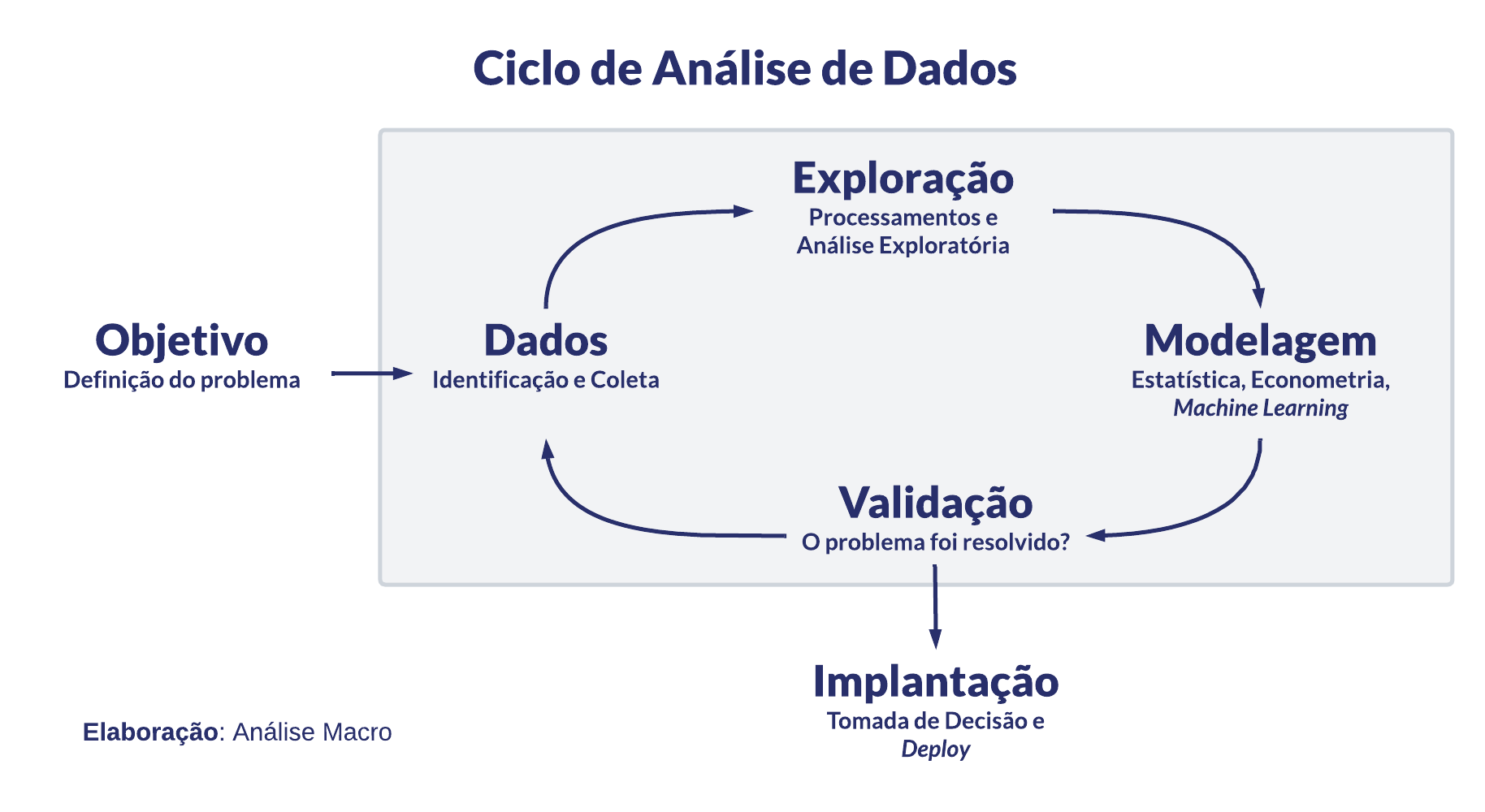
Os dados nos dizem que há mais de 1 mil postos de combustíveis distribuídos em cerca de 33 municípios no estado de Santa Catarina em que a ANP realiza o levantamento de preços de gasolina. O histórico de preços começa em 2004 e é atualizado, em geral, até a semana anterior à data atual.
Em termos nominais, a gasolina foi comercializada nesse período a cerca de R$ 3,1 por litro; já em termos reais, usando o índice de preços IPCA com último valor como data-base, foi comercializada a cerca de R$ 5,7 por litro. Ambos valores são médias do período, que é uma medida bastante sensível na presença de valores extremos na distribuição, como é o caso dos dados nominais.
Os preços de venda da gasolina variaram bastante nesse período, passando por diferentes tendências a depender do período em análise. Por ser um preço monitorado ou administrado pelo governo, a gasolina pode sofrer variações que não podem ser explicadas pela lei de oferta e demanda da teoria econômica. Essa é uma característica relevante para se levar em consideração, por exemplo, em modelos preditivos.
Poderíamos continuar explorando mais a fundo os dados, mas vamos tentar avançar para as próximas etapas e tentar desenvolver alguma solução para o problema que queremos resolver. Na prática, podemos ir e voltar entre uma ou outra etapa do ciclo de análise de dados conforme a necessidade. Como a imagem inicial sugere, não é um processo linear e podemos voltar nessa etapa para fazer ajustes e explorações adicionais.
Proposta de solução
Temos um problema definido para ser solucionado, temos os dados e sabemos um pouco sobre como eles se comportam. O que está faltando agora é desenvolver soluções baseadas nestes dados, usando, possivelmente, visualização de dados, estatística, econometria, machine learning e etc.
Queremos reduzir a assimetria de informação referente ao preço comercializado da gasolina no estado de Santa Catarina. Algumas primeiras ideias que podem vir a mente são:
- Um aplicativo web/dashboard para consultar indicadores de preço por localidade;
- Um modelo de previsão do preço futuro da gasolina por localidade;
- Um robô automatizado para consultar os preços por localidade;
- Um sistema de recomendação para a próxima abastecida do veículo.
Como pode ser visto, existem várias possibilidades a serem exploradas, todas elas interessantes e com potencial de serem boas soluções. Entretanto, o nosso foco é em desenvolver uma solução que seja a mais simples possível, conforme já mencionado, o que nos faz eliminar algumas possibilidades que são mais complexas e intensivas em recursos de tempo, hardware, conhecimento, etc.
Além disso, a decisão do tipo de solução que será experimentada também deve considerar a experiência do usuário, ou seja, o motorista que vai no posto abastecer e precisa de informações sobre os preços praticados. Não adianta criarmos um super modelo que usa inteligência artificial, treinado com otimização de parâmetros e com acurácia de 99% se a entrega dessa solução é uma API que o motorista não sabe ou não deseja utilizar. A entrega da solução precisa ser fácil para o usuário e aqui estamos trabalhando isoladamente, sem capital humano para desenvolver um aplicativo de celular, por exemplo, para consumir os dados de uma API na palma da mão do motorista. A este ponto deve estar ficando claro aonde queremos chegar.
Levando todos estes aspectos em consideração, além de outros não enumerados, vamos optar por experimentar a solução mais simples, que consideramos ser uma dashboard básica com indicadores de preço da gasolina para livre acesso pelos motoristas. Dashboards estão presentes em todo lugar atualmente, então não estamos inventando a roda e não precisaremos treinar o usuário para utilizar essa solução.
A ideia é fazer uma Prova de Conceito (PoC, na sigla em inglês), com a finalidade de entregar uma solução o mais rápido possível. Com isso feito, torna-se mais claro no projeto de análise de dados, com base em feedbacks e monitoramento, o que deu certo e o que precisa ser melhorado, assim como as próximas soluções analíticas que podem ser lançadas.
Partindo para a parte prática de desenvolvimento da solução, vamos utilizar o framework de dashboards em Shiny, que é uma ferramenta moderna e open source para desenvolver dashboard e aplicativos web interativos, seja em R ou Python.
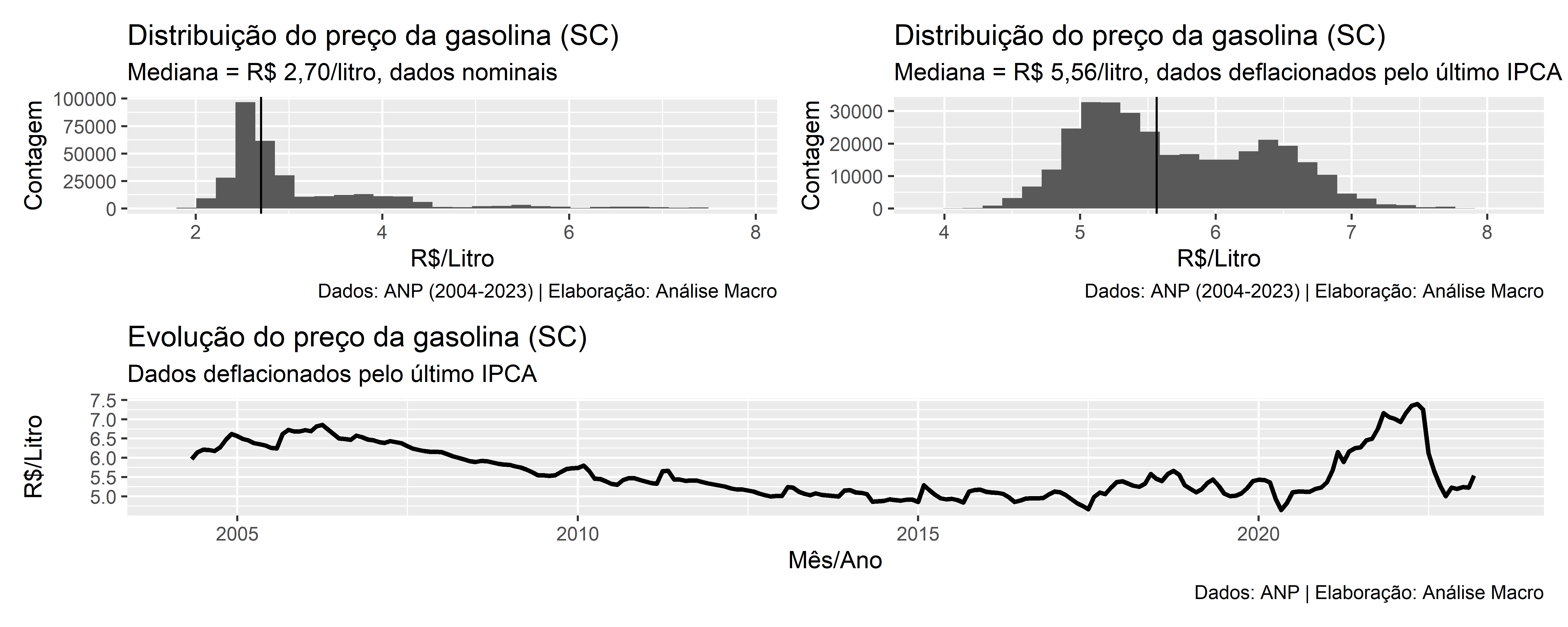
Abaixo expomos a implementação da dashboard analítica dos preços de gasolina praticados no estado de Santa Catarina:
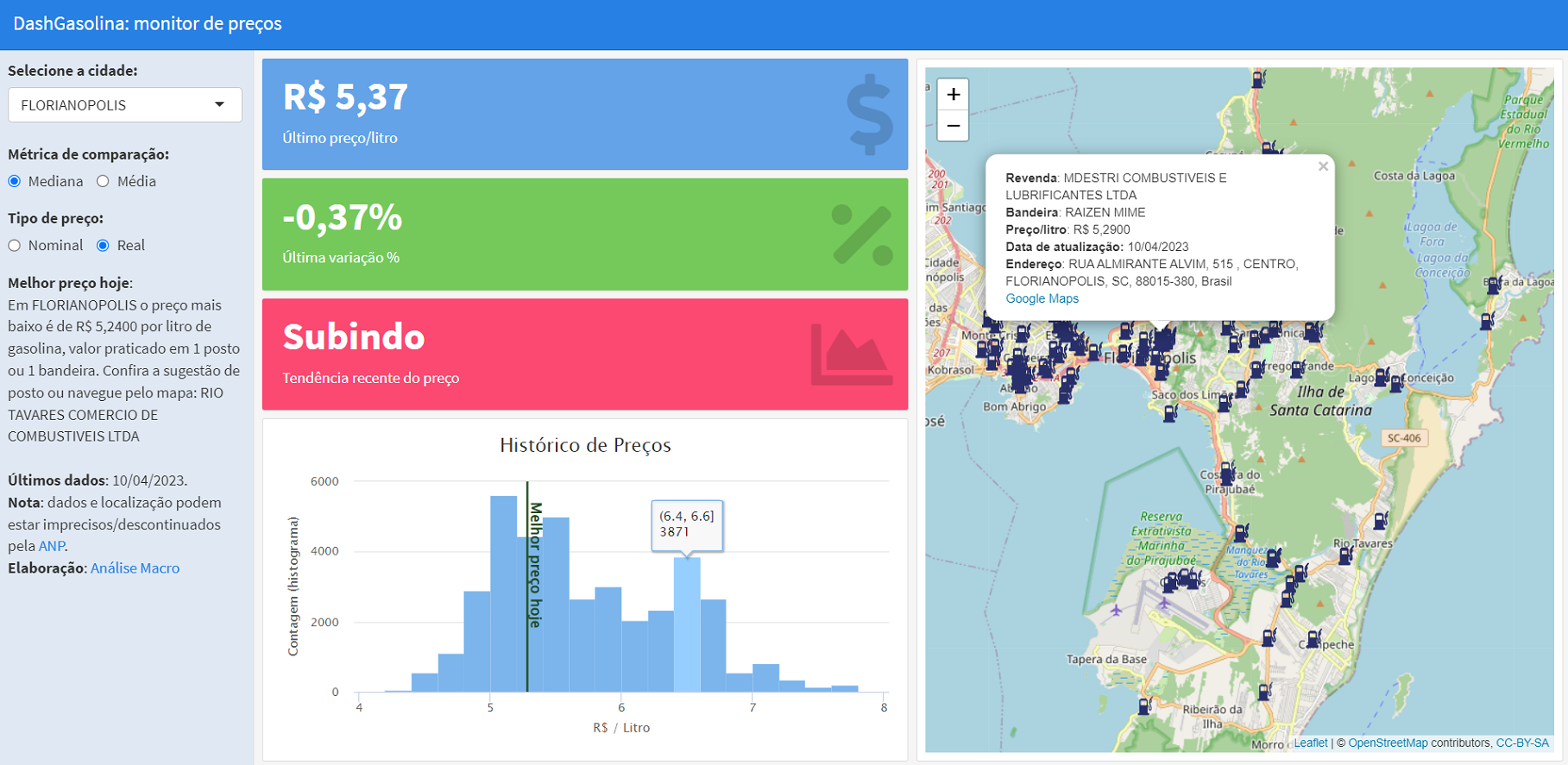
Acesse a dashboard pelo link: https://analisemacro.shinyapps.io/dashgasolina/
A aplicação desenvolvida é bastante simples e sem muito apelo visual, o que pode ser o próximo passo do projeto após finalizar esse primeiro PoC. A dashboard oferece algumas opções simples de interação e indicadores chave para o motorista acessar e tomar decisões rapidamente, dentre elas:
- Opção de filtrar dados por cidade;
- Opção de medida de centralidade para comparação;
- Opção de tipo de preço de venda da gasolina;
- Mapa interativo para navegação e consulta de preços.
Outros recursos podem ser implementados e há bastante espaço para melhorar os existentes. Além disso, os dados da ANP para determinados pontos de coleta de preços podem ser descontinuados a qualquer momento, o que reque cuidado ao analisar os dados.
Validação da solução
Na etapa de validação dentro do ciclo de análise de dados o objetivo é verificar se o problema definido pode ser solucionado com a proposta de solução desenvolvida. Note que não desenvolvemos nenhum modelo que permita utilizar métricas tradicionais de avaliação, como RMSE, portanto precisaremos avaliar a solução de maneira subjetiva ou coletando feedback de usuários. A segunda opção só é possível após um certo tempo, então vamos prosseguir com a primeira.
O problema era a assimetria de informação: o motorista ia no posto A e abastecia e depois verificava que no posto B o preço era menor. A dashboard desenvolvida ajuda o motorista a evitar esse tipo de situação? Possivelmente sim! Com o mapa o motorista pode facilmente verificar os postos mais próximos de sua localização, assim como consultar os dados de preço praticado recentemente e historicamente.
Além disso, os cards da dashboard apresentam alguns indicadores para auxiliar o motorista da tomada de decisão, permitindo comparar se o preço no posto X está abaixo ou acima da média/mediana da cidade, além de haver a indicação da tendência do preço nos últimos períodos.
Em suma, acreditamos que essa primeira versão da dashboard soluciona em uma boa medida o problema de assimetria de informação.
Implantação da solução
Na última etapa do ciclo de análise de dados é preciso tomar uma decisão sobre como a solução, uma vez que tenha sido validada, será implementada e/ou comunicada para seus usuários. No caso de uma dashboard, a implementação pode se dar por meio do processo conhecido como deploy ou publicação, que compreende disponibilizar a dashboard, usualmente por um link, para livre acesso dos usuários.
Dashboard desenvolvidas no framework Shiny podem ser publicadas de diversas formas, desde as mais simples até as mais sofisticadas. Uma possibilidade é utilizar o serviço gratuito Shinyapps.io: basta cadastrar uma conta de usuário e gerar uma chave de token para fazer o deploy da dashboard. Ao final do processo é gerado um link, como esse da dashboard acima: https://analisemacro.shinyapps.io/dashgasolina/
Após a publicação da dashboard (ou durante o desenvolvimento do projeto) é importante documentar todo o projeto e organizar as informações relevantes para comunicar essa solução aos potenciais usuários. Essa etapa é crucial para o sucesso do projeto, afinal não queremos criar dashboards que ninguém irá acessar. Então é importar comunicar bem as informações, criar storytelling de dados, imagens, vídeos, etc. para que o usuário consiga rapidamente compreender como a solução analítica pode ajudar ele.
Conclusão
Chegamos ao final dessa jornada por dentro da implementação de um projeto de análise dados. O objetivo foi resolver um problema real com dados reais, visando explorar os desafios que podem ser encontrados no dia a dia de trabalho. Percorremos todas as etapas do ciclo analítico, desde a definição do problema até o deploy da solução desenvolvida, dando ênfase nos conceitos e possibilidades que se encontram no caminho. Escolhemos usar ferramentas modernas e práticas para projetos de dados, deixando claro que podem ser usadas outras alternativas, sem prejuízo dos resultados finais.
Se você se interessa por análise e ciência de dados e quiser adquirir os conhecimentos e habilidades destacados neste artigo, dê uma olhadinha nos nossos Cursos e no Clube AM, onde ficam disponíveis os vídeos e códigos de mais de 200 exercícios como esse:
Referências
Luraschi, J., Kuo, K., & Ruiz, E. (2019). Mastering Spark with R: the complete guide to large-scale analysis and modeling. O'Reilly Media, Inc.
Gonzaga, Sillas. Como usar o R para escolher um lugar para morar (3) - Converter CEP em coordenadas geográficas. Paixão por dados, 18, novembro, 2016. Disponível em: https://sillasgonzaga.github.io/2016-11-18-olx3/. Acesso em: 21/04/2023.
Gonzaga, Sillas. Como usar o R para escolher um lugar para morar (4) - Mapa interativo. Paixão por dados, 18, novembro, 2016. Disponível em: https://sillasgonzaga.github.io/2016-11-18-olx4/. Acesso em: 21/04/2023.
Wickham, H., & Grolemund, G. (2023). R for Data Science. Second edition. O'Reilly Media, Inc.

