Neste exercício utilizaremos os statements do FOMC/FED para construir um índice de sentimentos, que busca quantificar sentimentos (i.e. positivo, negativo) através de informações textuais extraídas por técnicas de text mining. Em seguida, comparamos o índice com o principal instrumento de política monetária, a taxa de juros, e avaliamos sua utilidade em prever mudanças de política através do teste de causalidade de Granger.
Text mining
Se textos pudessem falar, o que eles diriam? Essa é a ideia central por trás das técnicas de text mining existentes, que buscam extrair insights de dados textuais (i.e. notícias, atas, comunicados, livros, etc.). Quando lemos um texto, usamos naturalmente nossa compreensão individual sobre o sentido emocional das palavras para inferir o sentimento/emoção de um trecho do texto (risco = negativo, ganho = positivo). Dessa forma, as técnicas de text mining se propõem a realizar essa mesma "inferência" de maneira quantitativa. Em outras palavras, nós escrevemos um código que "lê" um texto e informa em números, com base em classificações prévias ou por modelos, o sentimento do mesmo.
Para ter acesso a exercícios diários de análise de dados como esse, com vídeos, scripts, material complementar e suporte completo, conheça o Clube AM.
A técnica de text mining mais simples é a que contabiliza o número de palavras positivas/negativas em um dado texto e, a partir disso, calcula um índice de sentimentos como:
Sentimento = nº positivas - nº negativas
Valores positivos indicam sentimos positivos, valores negativos indicam sentimentos negativos e valor igual a zero indica neutralidade. Essa não é a única técnica de analisar sentimentos de um texto, mas é comumente a mais utilizada. Mas como definir se uma palavra de um texto é positiva ou negativa?
A análise de sentimento é uma grande área de pesquisa - muitas vezes vista como uma subárea do Processamento de Linguagem Natural (NLP, no inglês) - que, ao longo dos anos, vem possibilitando a pesquisadores e profissionais de mercado o uso de dicionários de sentimento, também chamados de "léxicos", que classificam um grande conjunto de palavras comumente usadas em documentos em positivas/negativas.
Exemplos de dicionários/léxicos para análise de sentimentos:
- Loughran-McDonald sentiment lexicon (muito usado em textos de finanças);
- Bing sentiment lexicon (de uso geral);
- AFINN-111 dataset (mede o sentimento em uma escala de -5 a 5)
Veja as referências para mais detalhes.
Mas na prática, como esses dicionários se parecem? Abaixo apresentamos 12 palavras aleatórias (de um total de 4.150) do dicionário Loughran-McDonald e a classificação de sentimento correspondente:
Observe que o dicionário apresenta 7 possíveis classificações de sentimentos para as palavras: "negative", "positive", "uncertainty", "litigious", "constraining" e "superfluous". Entretanto, na prática o mais comum e simples é analisar o sentimento de um texto no "modo binário", ou seja, usando apenas as classificações de positivo/negativo. Portanto, como podemos utilizar este dicionário de maneira prática?
Em resumo, uma análise de sentimentos pode ser desenvolvida em 4 etapas:
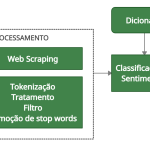
- Dados textuais: definir quais dados textuais serão alvo da análise, assim como identificar sua localização (online);
- Pré-processamento: são rotinas de coleta e tratamento dos dados textuais, o que envolve a aplicação de técnicas de web scraping (veja um tutorial aqui), de tokenização (veja um tutorial aqui) e de manipulação de strings em geral;
- Classificação de Sentimentos: cruza os dados textuais tratados, já representados na unidade (token) de palavras, com um dicionário/léxico de sentimentos e contabiliza o nº palavras positivas/negativas no texto;
- Índice de Sentimentos: calcula o índice conforme a expressão matemática apresentada acima.
Os procedimentos expostos não exigem o uso de nenhum método de estimação estatística, apesar de haverem outras técnicas de text mining para tal, portanto são acessíveis a maioria das pessoas. A parte mais difícil para iniciantes são as etapas de coleta de dados (web scraping), principalmente se o conjunto de textos alvo da análise é grande em volume e/ou quantidade. Nestes casos, procedimentos manuais de coleta de dados são inviáveis e você precisa sair da zona de conforto da sua área de pesquisa/trabalho e entender alguns jargões das linguagens de desenvolvimento web. A boa notícia é que usando o R não precisamos necessariamente entender sobre essas outras linguagens, dado que existem pacotes/funções que fazem o trabalho por nós, em uma sintaxe quase que natural de se ler.
A seguir apresentamos algumas informações úteis sobre o procedimento de análise de sentimentos aplicada aos comunicados do FOMC/FED. Todo o código necessário para replicação está disponibilizado ao final deste material.
Web scraping
Em geral, as informações textuais estão disponíveis digitalmente, hospedadas em algum site na internet. Como exemplo deste exercício, utilizamos o site do FOMC/FED, que disponibiliza, dentre outros, os documentos referentes aos statements desde 1936. Estes documentos são divulgados logo após cada reunião da autoridade monetária e servem para comunicar sua decisão referente a taxa de juros da economia (FED Funds Target Rate).
Como exemplo, na imagem a seguir trazemos o primeiro statement que iremos utilizar no exercício:

No total, utilizamos uma amostra de 205 statements no período 1998 até 2022. O procedimento de web scraping destes documentos no site do FED pode ser desenvolvido de maneira automatizada usando o R, conforme o código ao final (para mais informações veja este tutorial).
Índice de Sentimentos
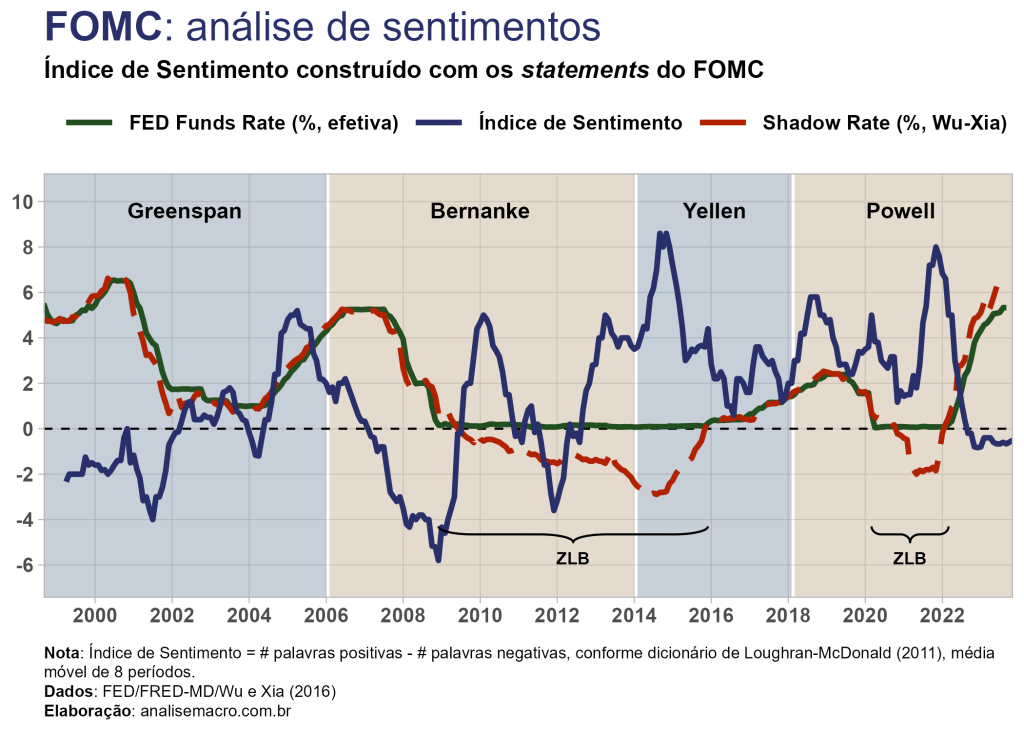
Na etapa de pré-processamento removemos as stop words comuns da língua inglesa ("the", "of", "in", etc.), pontuações e números. A tokenização é feita a nível de palavra por cada statement e, desse resultado, cruzamos os dados com a tabela do dicionário de Loughran-McDonald para contabilizar as palavras positivas/negativas. Por fim, o índice é calculado, conforme apresentado acima, e visualizações de dados como essa abaixo podem ser geradas:
No gráfico acima comparamos os movimentos da média móvel de 8 períodos do índice de sentimentos calculado, por ser uma série menos ruidosa, com a taxa de juros da economia norte-americana, ou seja, com os ciclos de expansão ou contração monetária. Podemos observar que o índice de sentimentos parece, em certa medida, "antecipar" os movimentos de política monetária. O período mais notório é o da crise financeira de 2008 (Grande Recessão), no qual o FED fez uso do instrumento denominado quantitative easing (QE) e reduziu a taxa de juros para o intervalo mínimo de 0% (Zero Lower Bound ou ZLB), enquanto que os sentimentos captados nos statements anteriores ao "estouro" da crise eram continuamente decrescentes, em sentido negativo.
Outra característica interessante que o índice de sentimentos traz é seu estado conforme os mandatos do FED. Nota-se que no último mandato (Yellen) e no atual (Powell) o índice não esteve uma única vez negativo, para qualquer dos statements analisados no período. Isso não significa que o sentimento não tenha variado no período. Por exemplo, observe que no mandato da Yellen o índice começa próximo ao pico do mandato anterior, atinge o pico da série histórica e cai até abaixo do seu início.
Note ainda que mesmo durante períodos de política de ZLB o índice capta a variação dos sentimentos expressos nos comunicados. Como exemplo recente, com a pressão inflacionária e o aumento da taxa de juros - e consequente saída do ZLB - os sentimentos estão se aproximando novamente da região negativa.
A questão que fica é: este humilde índice de sentimentos é capaz de antecipar as mudanças de política monetária?
Causalidade de Granger
De forma a testar estatisticamente se a interpretação gráfica que fiz acima faz algum sentido, agora eu aplico um teste de causalidade de Granger. O teste serve para verificar se uma série temporal é útil em termos de previsão de outra série temporal, ou seja, o termo "causalidade" deve ser pensado como "precedência temporal".
Intuitivamente, com a aplicação do teste podemos dizer que uma série temporal X Granger-causa outra série temporal Y se as previsões dos valores de Y com base em seus próprios valores defasados e nos valores defasados de X forem "melhores" do que as previsões de Y baseadas apenas nos próprios valores defasados de Y. Formalmente, o teste compara dois modelos de regressão linear:
- Modelo restrito → yt = α0 + α1yt−1 + ⋯ + αmyt−m + errot
- Modelo irrestrito → yt = α0 + α1yt−1 + ⋯ + αmyt−m + β1xt-1 + ⋯ + βmxt−m + errot
O número de defasagens m deve ser especificado pelo usuário. Dessa forma, testamos as hipóteses:
- Hipótese nula: a série temporal X não Granger-causa a série Y
- Hipótese alternativa: a série temporal X Granger-causa a série Y
Um teste F é então aplicado para determinar se os coeficientes dos valores passados de xt são conjuntamente iguais a zero (H0: β1 = ⋯ = βm = 0), produzindo um p-valor. Dessa forma, se o p-valor for menor que um determinado nível de significância (por exemplo, α = 0,05), podemos rejeitar a hipótese nula e dizer que a série temporal X Granger-causa a série Y. Isso significa que os valores de previstos para Y baseados em suas próprias defasagens e em defasagens de X são melhores do que valores previstos para Y baseados somente em defasagens de Y. Usualmente aplica-se o teste em ambas as direções, ou seja, de X → Y e de Y → X.
Aplicando o teste de causalidade de Granger sobre as séries do Índice de Sentimentos (IS, em nível, não a média móvel) e do FED Funds Rate (FFR, na primeira diferença), em ambas as direções, temos como resultado:
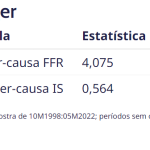
Analisando os resultados, na direção IS → FFR rejeitamos a hipótese nula ao nível de 5%, ou seja, podemos dizer que há precedência temporal ou, mais formalmente, a série temporal IS Granger-causa a série temporal FFR. Na direção oposta falha-se em rejeita a hipótese nula. Acredito que minha análise visual de antes está correta.
Código de replicação (R)
O código completo para replicação do exercício está disponível no Clube AM. Note que o procedimento de web scraping no site do FED está automatizado, não havendo garantias de funcionamento se houverem mudanças no mesmo. Além disso, você pode obter resultados diferentes dos aqui expostos conforme a amostra de textos extraídos do site for crescendo ao longo do tempo.
Para ter acesso a exercícios diários de análise de dados como esse, com vídeos, scripts, material complementar e suporte completo, conheça o Clube AM.
Quer aprender mais?
Clique aqui para fazer seu cadastro no Boletim AM e baixar o código que produziu este exercício, além de receber novos exercícios com exemplos reais de análise de dados envolvendo as áreas de Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas diretamente em seu e-mail.
Referências
Granger, C. W. (1969). Investigating causal relations by econometric models and cross-spectral methods. Econometrica: journal of the Econometric Society, 424-438.
Hu, M., & Liu, B. (2004). Mining and summarizing customer reviews. In Proceedings of the tenth ACM SIGKDD international conference on Knowledge discovery and data mining (pp. 168-177).
Loughran, T., & McDonald, B. (2011). When is a liability not a liability? Textual analysis, dictionaries, and 10‐Ks. The Journal of finance, 66(1), 35-65.
Nielsen, F. Å. (2011). A new ANEW: Evaluation of a word list for sentiment analysis in microblogs. arXiv preprint arXiv:1103.2903.
Silge, J., & Robinson, D. (2017). Text mining with R: A tidy approach. O'Reilly Media, Inc.
Shapiro, A. H., & Wilson, D. (2021). Taking the Fed at its word: A new approach to estimating central bank objectives using text analysis. Federal Reserve Bank of San Francisco.
Wu, J. C., & Xia, F. D. (2016). Measuring the macroeconomic impact of monetary policy at the zero lower bound. Journal of Money, Credit and Banking, 48(2-3), 253-291.

