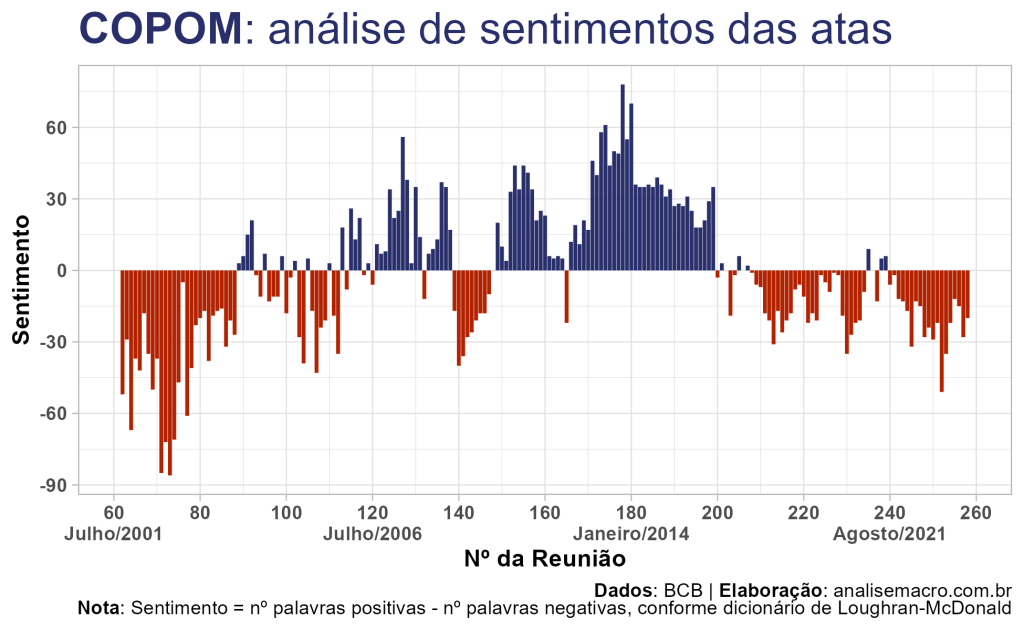
Neste exercício construiremos um indicador que busca quantificar o sentimento proveniente das decisões de política monetária no Brasil. Usando técnicas de mineração de texto (text mining, no inglês), implementamos todas as etapas necessárias, desde web scraping e pré-processamento das atas do Comitê de Política Monetária do Banco Central (COPOM), até a criação de tokens e a classificação do sentimento implícito nos textos. A síntese do exercício é plotada no gráfico de colunas abaixo:
Mineração de texto
Se textos pudessem falar, o que eles diriam? Essa é a ideia central por trás das técnicas de mineração de texto existentes, que buscam extrair insights de dados textuais (i.e. notícias, atas, comunicados, livros, etc.). Quando lemos um texto, usamos naturalmente nossa compreensão individual sobre o sentido emocional das palavras para inferir o sentimento/emoção de um trecho do texto (por exemplo: recessão = negativo, crescimento = positivo).
Dessa forma, as técnicas de mineração de texto se propõem a realizar essa mesma "inferência" de maneira quantitativa, superando limitações de uma análise qualitativa. Em outras palavras, nós podemos escrever um código que "lê" um texto e informa em números, com base em classificações prévias ou por modelos estatísticos/machine learning, o sentimento do mesmo.
Como isso funciona? Abordamos a seguir um dos métodos mais simples disponíveis.
Métodos
A técnica de mineração de texto mais simples é a que contabiliza o número de palavras positivas/negativas de um dado texto e, a partir disso, calcula um indicador de sentimentos como1:
Sentimento = nº positivas - nº negativas
Valores positivos indicam sentimos positivos, valores negativos indicam sentimentos negativos e valor igual a zero indica neutralidade. Essa não é a única técnica de analisar sentimentos de um texto — ela não leva em consideração, por exemplo, o contexto das palavras —, mas é comumente utilizada e configura um ponto de partida para estudos.
Mas como definir se uma palavra de um texto é positiva ou negativa?
Dicionários de sentimento
A análise de sentimento é uma grande área de pesquisa — muitas vezes vista como uma subárea do Processamento de Linguagem Natural (NLP, no inglês) — que, ao longo dos anos, vem possibilitando a pesquisadores e profissionais de mercado o uso de dicionários de sentimento, também chamados de "léxicos". Estes dicionários classificam um grande conjunto de palavras comumente usadas em documentos em categorias como "positiva", "negativa", etc.
Exemplos de dicionários/léxicos para análise de sentimentos:
- Loughran-McDonald sentiment lexicon (muito usado em textos de finanças);
- Bing sentiment lexicon (de uso geral);
- AFINN-111 dataset (mede o sentimento em uma escala de -5 a 5).
Mas na prática, como esses dicionários se parecem? Abaixo apresentamos 12 palavras aleatórias (de um total de 4.150) do dicionário Loughran-McDonald e a classificação de sentimento correspondente:
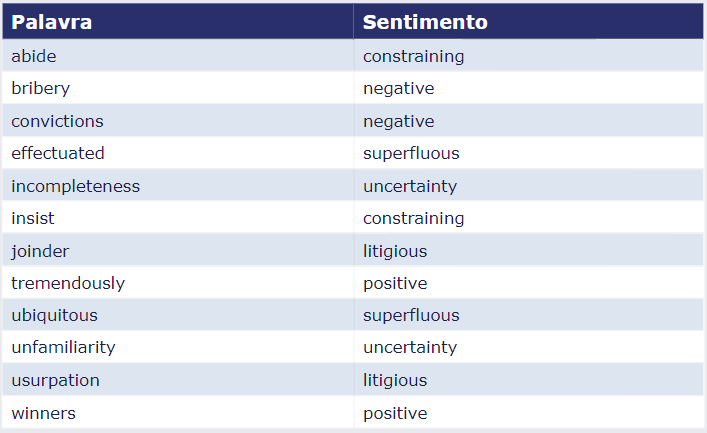
Observe que o dicionário apresenta 7 possíveis classificações de sentimentos para as palavras: "negative", "positive", "uncertainty", "litigious", "constraining" e "superfluous". Entretanto, na prática o mais comum e simples é analisar o sentimento de um texto no "modo binário", ou seja, usando apenas as classificações de positivo/negativo.
Portanto, como podemos utilizar este dicionário na prática? Vamos entender como funciona um fluxo de trabalho para desenvolver um indicador de sentimentos, unindo dados textuais e dicionários de sentimentos.
Guia prático de análise de sentimentos
Em resumo, uma análise de sentimentos pode ser desenvolvida em 4 etapas:
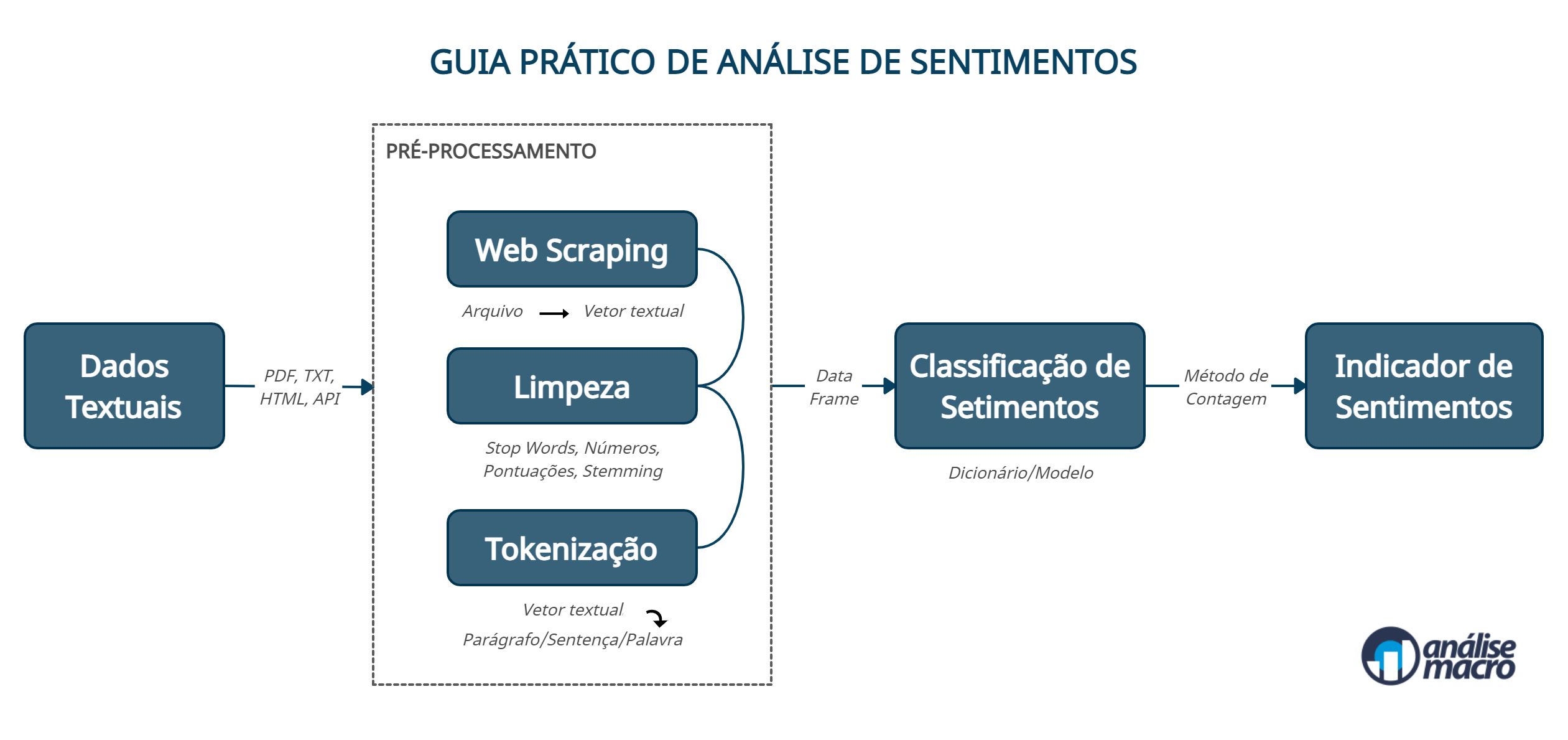
- Dados textuais: definir quais dados textuais serão alvo da análise, assim como identificar sua localização (online/offline);
- Pré-processamento: são rotinas de coleta e tratamento dos dados textuais, onde o objetivo é converter os arquivos de textos em uma representação textual (usualmente, em um vetor de strings) no ambiente de programação. Isso envolve a aplicação de técnicas de web scraping (veja um tutorial aqui), remoção de stops words, números, pontuações, etc. e de manipulação de strings em geral, além de tokenização (veja um tutorial aqui);
- Classificação de Sentimentos: cruza os dados textuais tratados, já representados na unidade (token) de palavras, com um dicionário/léxico de sentimentos (ou usando modelos) e contabiliza o nº palavras positivas/negativas no texto;
- Indicador de Sentimentos: calcula o indicador conforme a expressão matemática apresentada acima.
Pontua-se que estes procedimentos não são universais, dependem do contexto da sua análise. Para o propósito do exercício simples a seguir, serão suficientes. A etapa mais difícil para iniciantes se refere a coleta de dados (web scraping) e a sua manipulação no ambiente de programação. A boa notícia é que a linguagem R possui pacotes de fácil utilização, que fazem grande parte do trabalho por nós, em uma sintaxe quase que natural de se ler.
A seguir apresentamos algumas informações úteis sobre o procedimento de análise de sentimentos aplicado às atas do COPOM. Todo o código de R necessário para replicação está disponibilizado para membros do Clube AM.
Dados textuais
As atas do COPOM são um caminho natural para qualquer economista ou analista em busca de uma fonte de dados para exercitar a mineração de textos, já que informam a condução e as decisões da política monetária. A cada reunião (cerca de 45 dias) o COPOM realiza ajustes (mudanças) no texto, além de os mesmos possuírem um padrão (quase) comum ao longo do tempo. Isso nos permite avaliar mudanças de sentimento dos diretores do BCB de uma reunião para outra, por exemplo.
As atas são disponibilizadas neste link2 em arquivos PDFs (atualmente há 249 reuniões realizadas). Ao abrir uma ata, com quais informações nos deparamos? Normalmente, haverá uma capa, uma contracapa e as demais páginas da ata descrevem a atualização do cenário econômico do COPOM, balanço de riscos, condução da política monetária e decisão em relação a taxa básica de juros (Selic).

Fonte: COPOM/BCB (30/07/2001), destaques pelo autor.
Então, em resumo, nosso alvo de análise de sentimentos serão as atas do COPOM e sabemos que:
- Período: as atas estão disponíveis no site do BCB referentes às reuniões 42ª a 247ª, na versão em inglês;
- Formato: os textos das atas estão em formato PDF;
- Estrutura: a estrutura do documento pode variar de reunião para reunião e conforme o mandato da diretoria.
Portanto, um algoritmo para analisar o sentimento das atas deve levar tudo isso em consideração. Aqui focaremos em procedimentos simples e isso pode influenciar nos resultados da análise (i.e. a conversão de PDF para texto é delicada).
Pré-processamento
A coleta de dados para uma análise de sentimentos, usualmente, envolve empregar técnicas de web scraping (raspagem de dados). Em termos simples, é um procedimento que envolve criar um código que instrua o computador a acessar um determinado site na internet e baixar determinado conteúdo/arquivo do mesmo para o computador.
O procedimento de web scraping das atas do COPOM no site do BCB envolve, em resumo:
- Identificar na URL base (https://www.bcb.gov.br/en/publications/copomminutes) o link para uma API que disponibiliza um arquivo JSON com links para todas as atas (usando o Google Chrome);
- Importar o arquivo JSON para o ambiente da linguagem de programação;
- Utilizar a tabela/lista com links para as atas para baixá-las/importá-las em formato de texto/string para o ambiente da linguagem de programação.
Demonstraremos passo a passo como realizar estes procedimentos e os detalhes pertinentes (códigos disponíveis para membros do Clube AM). Para um tutorial introdutório sobre web scraping no R veja este link.
Importante: procedimentos de web scraping tendem a falhar no longo prazo, pois as estruturas dos sites mudam e isso impacta diretamente a funcionalidade do código. Em outras palavras, não existe almoço grátis e alguma manutenção de código é necessária de tempos em tempos.
Uma vez que você tenha os textos das atas importados para o ambiente da linguagem de programação, deve-se prosseguir com os tratamentos dos dados brutos. Em resumo, isso envolve:
- Remoção de stop words: são as palavras comuns da língua, que não trazem, necessariamente, emoção/sentimento ao texto. No caso do inglês alguns exemplos são "and", "the", "of", "in", "that", etc;
- Remoção de pontuações e números: por também "não" expressarem sentimentos, usualmente removemos pontuações como ‘! " # $ % & ' ( ) , - . / : ; < = > ? @ [\ \ ] ~’, além de números;
- Stemming: é a redução das palavras ao seu radical/raiz, para facilitar e simplificar a classificação dos sentimentos. Por exemplo, as palavras "increasing", "increased" e "increases" são reduzidas para "increas";
- Tokenização: é o processo de desagregar um texto em "unidades de textos" — geralmente em palavras, frases, parágrafos, etc. —, permitindo diferentes análises e contabilização do sentimento dessas unidades (tokens).
Classificação de sentimentos
Após a etapa de pré-processamento dos dados textuais, realizamos um cruzamento (join) da tabela de tokens com uma tabela de dicionário de sentimentos. Dessa forma, agrupando a tabela resultante por um identificador do texto em que o token/sentimento aparece, podemos contabilizar o número de palavras (tokens) positivas e negativas em cada texto.
Por fim, utilizamos a contagem de palavras positivas e negativas para calcular o indicador de sentimentos, conforme a expressão exposta no início.
Explanados estes procedimentos, agora vamos ver o resultado final!
Para mais informações sobre o indicador, interpretações, uso e relação com outras variáveis macroeconômicas, confira os exercícios das próximas semanas (sexta-feira).
Código de replicação (R)
O código completo para replicação do exercício está disponível para membros do Clube AM. O procedimento de web scraping no site do BCB está automatizado, não havendo garantias de funcionamento se houverem mudanças no site. Além disso, você pode obter resultados diferentes dos aqui expostos conforme a amostra de textos extraídos do site for crescendo ao longo do tempo.
Quer aprender mais?
Clique aqui para fazer seu cadastro no Boletim AM e baixar o código que produziu este exercício, além de receber novos exercícios com exemplos reais de análise de dados envolvendo as áreas de Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas diretamente em seu e-mail.
Referências
Hu, M., & Liu, B. (2004). Mining and summarizing customer reviews. In Proceedings of the tenth ACM SIGKDD international conference on Knowledge discovery and data mining (pp. 168-177).
Loughran, T., & McDonald, B. (2011). When is a liability not a liability? Textual analysis, dictionaries, and 10‐Ks. The Journal of finance, 66(1), 35-65.
Nielsen, F. Å. (2011). A new ANEW: Evaluation of a word list for sentiment analysis in microblogs. arXiv preprint arXiv:1103.2903.
Silge, J., & Robinson, D. (2017). Text mining with R: A tidy approach. O'Reilly Media, Inc.
1 Essa é uma fórmula simplificada, há variações da chamada polaridade do texto. Como exemplo, pode-se normalizar os termos pelo total de palavras, ou seja, Polaridade = (nº positivas - nº negativas) / (nº positivas + nº negativas).
2 O link direciona para a versão em inglês das atas, mas há também a versão em português no site da instituição. Usaremos a versão em inglês por conta do idioma usado nos principais dicionários de sentimentos.

