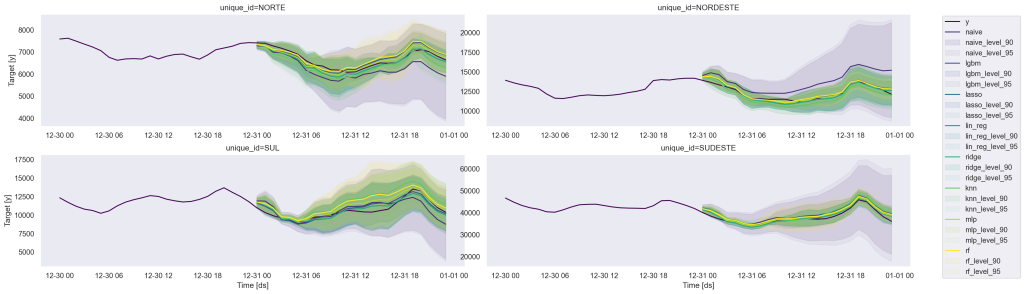
Como podemos realizar previsões para várias séries temporais simultaneamente? Para abordar essa questão, empregamos a biblioteca MLForecastdo Python. Esta biblioteca disponibiliza uma variedade de modelos e funcionalidades para realizar previsões em séries temporais utilizando técnicas de aprendizado de máquina. Demonstramos sua aplicação ao prever as curvas de energia horária em quatro regiões distintas do Brasil.
- Econometria e Machine Learning
Prevendo múltiplas séries usando IA no Python
Como podemos realizar previsões para várias séries temporais simultaneamente? Para abordar essa questão, empregamos a biblioteca MLForecastdo Python. Esta biblioteca disponibiliza uma variedade de modelos e funcionalidades para realizar previsões em séries temporais utilizando técnicas de aprendizado de máquina. Demonstramos sua aplicação ao prever as curvas de energia horária em quatro regiões distintas do Brasil.
Esse exercício é uma continuação do exercício “Usando IA para prever o consumo de energia no Brasil com Python”.
- Luiz Henrique Barbosa Filho
- 25 de março de 2024
- 09:00
Compartilhe esse artigo
Facebook
Twitter
LinkedIn
WhatsApp
Telegram
Email
Print
Boletim AM

Encontre o seu conteúdo
Categorias
- Comentário de Conjuntura
- Cursos da Análise Macro
- Indicadores
- Artigos de Economia
- Hackeando o R
- Data Science
- Política Monetária
- Macroeconometria
- Inflação
- PIB
- Eventos
- Indicação de Leitura Econômica
- Clube AM
- Dados Macroeconômicos
- Mercado financeiro
- Mercado de Trabalho
- Política Fiscal
- Resenhas de Conjuntura Econômica
Artigos mais acessados
Análise Macro © 2011 / 2026
comercial@analisemacro.com.br – Rua Visconde de Pirajá, 414, Sala 718
Ipanema, Rio de Janeiro – RJ – CEP: 22410-002
