Neste exemplo mostramos o poder da IA, especificadamente o uso de modelos de Machine Learning de Séries Temporais, para prever os valores da Curva de Carga Horária de Energia Elétrica do Sudeste disponibilizada pela ONS. Para realizar as previsões, além dos modelos, empregamos métodos de machine learning já conhecidos, como cross-validation, usando a biblioteca MlForecast do Python.
Introdução
Algumas séries temporais são geradas a partir de dados de frequência muito baixa. Esses dados geralmente exibem múltiplas sazonalidades. Por exemplo, dados horários podem exibir padrões repetidos a cada hora (a cada 24 observações) ou a cada dia (a cada 24 * 7, horas por dia, observações). Esse é o caso da carga elétrica. A carga elétrica pode variar por hora, por exemplo, durante as noites, no Brasil, espera-se uma queda no consumo de eletricidade. Mas também, a carga elétrica varia por semana. Talvez no caso brasileiro, fins de semana haja uma queda na atividade elétrica.
Outro aspecto crucial a ser observado em séries temporais de carga de energia é a tendência. No contexto brasileiro, observa-se claramente uma tendência ascendente, em grande parte devido ao contínuo crescimento econômico do país.
Quando lidamos com séries temporais que exibem tais padrões, torna-se imperativo empregar modelos capazes de identificá-los com precisão. Modelos de Machine Learning voltados para análise de Séries Temporais, como LightGBM ou até mesmo Prophet, destacam-se como as opções mais adequadas para abordar esses cenários complexos.
Portanto, neste exercício criamos diferentes modelos com a biblioteca MLForecast, usando como features valores da própria série para prever a carga de energia elétrica.
Para obter o código e o tutorial deste exercício faça parte do Clube AM e receba toda semana os códigos em R/Python, vídeos, tutoriais e suporte completo para dúvidas.
Bibliotecas
Neste exemplo, utilizaremos as seguintes bibliotecas:
- mlforecast. Previsões precisas e rápidas com modelos clássicos de aprendizado de máquina.
- utilsforecast. Biblioteca com diferentes funções para avaliação de previsões.
Dados
Utilizamos os dados de Carga Horária de Eletricidade Nacional do Sudeste medido pela ONS (em MW). Os valores estão em periodicidade horária, de Jan/2000 até Dez/2023.
Código
| ds | unique_id | y | |
|---|---|---|---|
| 0 | 2000-01-01 00:00:00 | SUDESTE | 21183.000 |
| 1 | 2000-01-01 01:00:00 | SUDESTE | 20409.900 |
| 2 | 2000-01-01 02:00:00 | SUDESTE | 19787.400 |
| 3 | 2000-01-01 03:00:00 | SUDESTE | 19089.000 |
| 4 | 2000-01-01 04:00:00 | SUDESTE | 18589.100 |
| ... | ... | ... | ... |
| 210365 | 2023-12-31 19:00:00 | SUDESTE | 45826.886 |
| 210366 | 2023-12-31 20:00:00 | SUDESTE | 44883.742 |
| 210367 | 2023-12-31 21:00:00 | SUDESTE | 41328.082 |
| 210368 | 2023-12-31 22:00:00 | SUDESTE | 38135.522 |
| 210369 | 2023-12-31 23:00:00 | SUDESTE | 36060.076 |
210370 rows × 3 columns

Observamos claramente que a série temporal exibe padrão sazonal, bem com há também um claro padrão de tendência. A série possui 210370 observações.
Vamos dividir nossa série para criar um conjunto de treinamento e teste. O modelo será testado usando as últimas 24 horas da série temporal.
Analisando Tendência e Sazonalidades
Primeiro, devemos visualizar a tendência e as sazonalidades do modelo. Como mencionado anteriormente, a carga elétrica apresenta sazonalidades a cada 24 horas (por hora) e a cada 24 * 7 (diariamente) horas. Portanto, usaremos [24, 24 * 7] como as sazonalidades para o modelo. No caso da tendência, supomos que possamos lidar com esse componente através da primeira diferença.
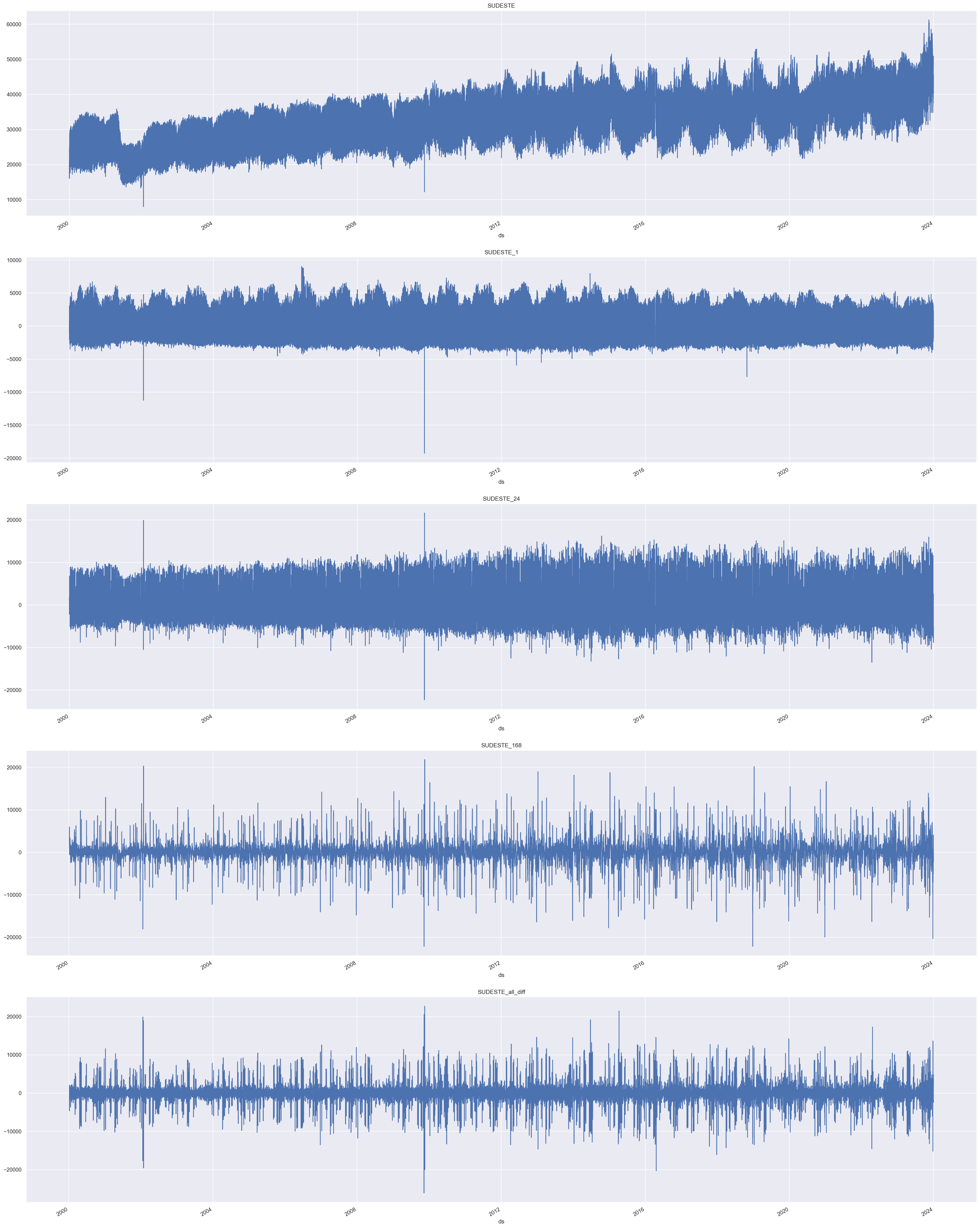
Como podemos ver, ao extrair a diferença de 1 em SUDESTE_1 a série parece estar limpa da tendência. Em relação a sazonalidade usamos 24 (diariamente) em SUDESTE_1_24, e a série parece estabilizar, pois os picos parecem mais uniformes em comparação com a série original SUDESTE.
Quando extraímos a diferença de 24 * 7 (semanal) em SUDESTE_168, podemos ver que há mais periodicidade nos picos em comparação com a série original.
Finalmente, podemos ver o resultado combinado da subtração de todas as diferenças SUDESTE_all_diff.
Para a modelagem, vamos usar todas as diferenças para a previsão, portanto, estamos configurando o argumento target_transforms do objeto MLForecast igual a [Differences([1, 24, 24*7])].
Seleção de Modelo com cross-validation
Podemos testar vários modelos simultâneamente usando MLForecast com o método de cross_validation. Importamos diferentes modelos (Lasso, LinearRegression, Ridge, KNN, MLP e Random Forest, juntamente com o LightGBM) e realizamos a combinação deles, conjuntamente com diferentes transformações do variável resposta (tal como criamos anteriormente).
Podemos criar um modelo de referência ingênuo que utiliza a carga elétrica da última hora como atraso de previsão (lag1).
Como features adicionais, usamos a 1, 12 e 24 defasagens, medidas de suavização com média, e as datas.
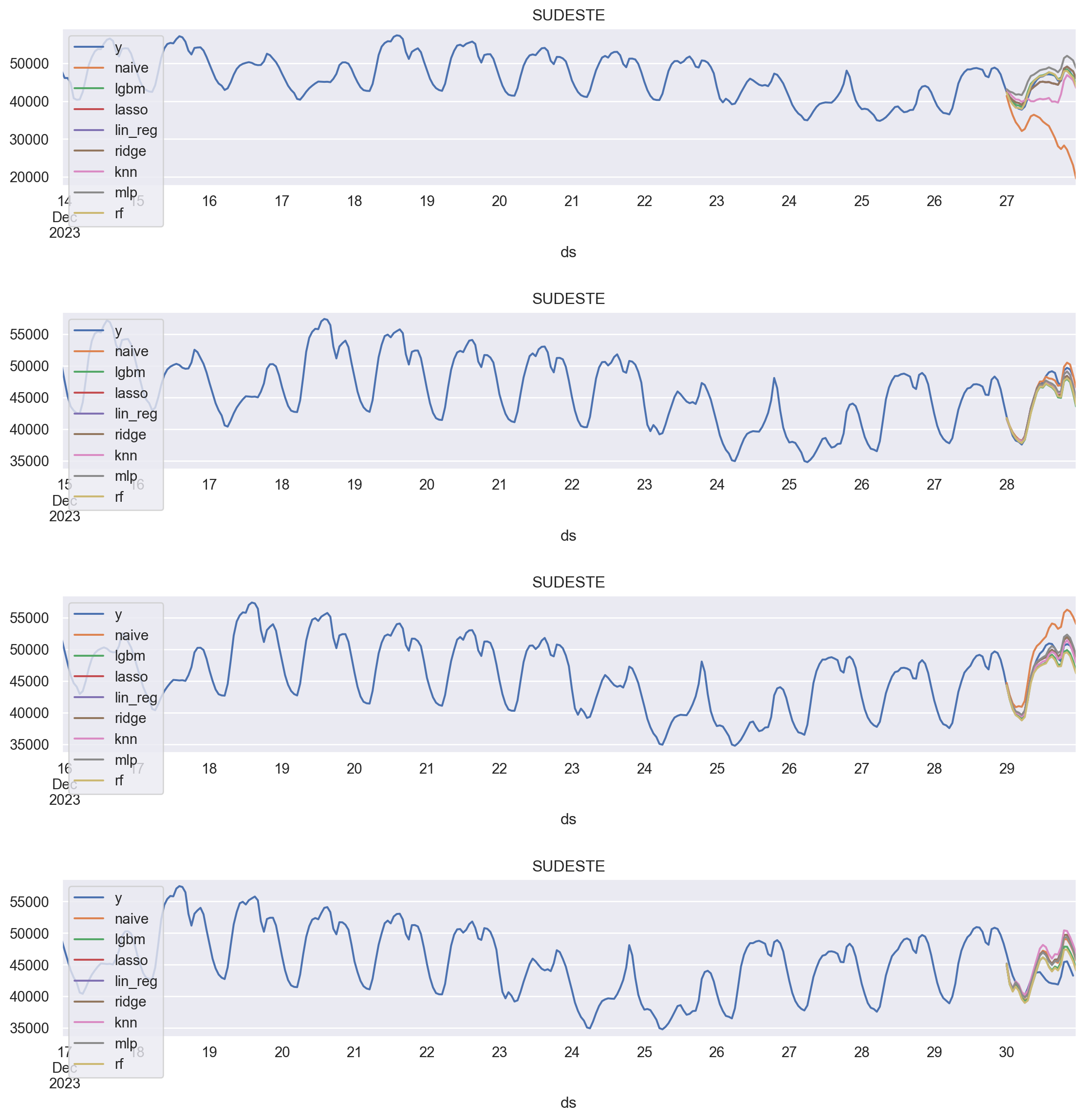
Agora plotamos cada modelo e a janela (fold do CV) para verificar os seus respectivos comportamentos.
Métricas de Acurácia
Examinar visualmente as previsões pode nos dar alguma ideia de como o modelo está se comportando, mas para avaliar o desempenho, precisamos avaliá-las por meio de métricas. Para isso, usamos a biblioteca utilsforecast, que contém muitas métricas úteis e uma função de avaliação.
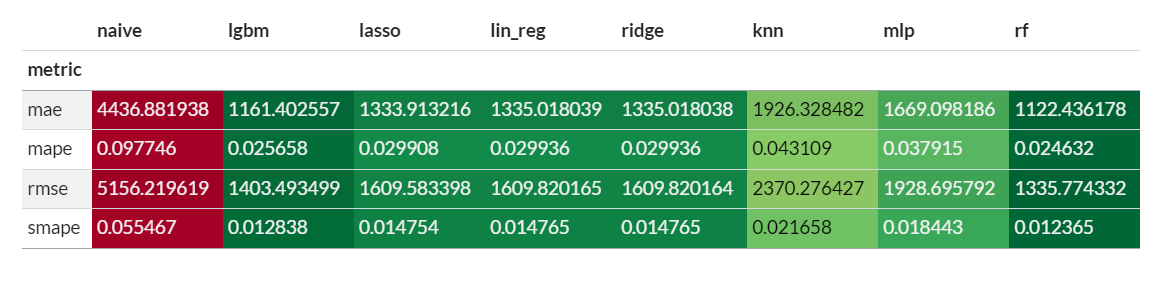
Verificamos que os melhores modelos nesse caso foram LGBM e RandomForest.
Conjunto de Teste
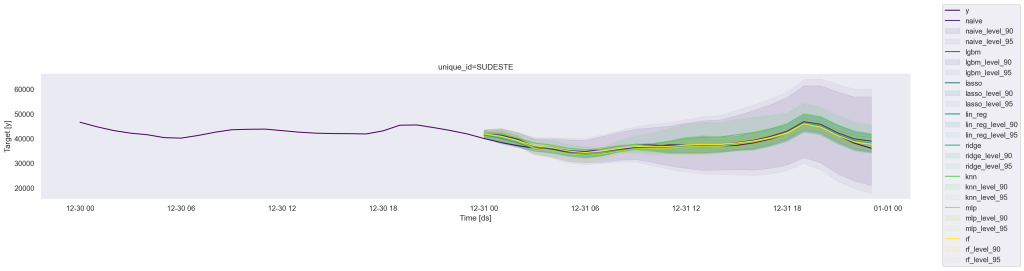
Agora vamos comparar os dados previsto do conjunto de treinamento no conjunto de teste, de forma a compreender qual modelo melhor realizou a previsão. Adicionamos intervalos de confiança para cada previsão.
Na matriz abaixo temos as métricas de erros para o conjunto de teste. Vemos que novamente LGBM e RandomForest apresentaram as melhores medidas de acurácia.
 O gráfico abaixo também auxilia na compreensão dos resultados.
O gráfico abaixo também auxilia na compreensão dos resultados.
Quer aprender mais?
Clique aqui para fazer seu cadastro no Boletim AM e baixar o código que produziu este exercício, além de receber novos exercícios com exemplos reais de análise de dados envolvendo as áreas de Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas diretamente em seu e-mail.

