Há um burburinho no mundinho dos economistas com respeito às diferenças entre o CAGED e a PNAD Contínua. Para muita gente dentro do mercado, o CAGED não estaria sinalizando de forma clara, por diversos problemas metodológicos, a ociosidade na economia. Já a PNAD Contínua retrataria melhor o fundo do poço pelo qual passa no país.
Instigado por esse fato, eu resolvi dar uma aula gratuita na próxima terça-feira, às 21h, sobre como analisar as duas pesquisas com o R. Se você tiver interesse, se inscreve lá no nosso Canal do youtube e ativa o lembrete da aula aqui.
A análise de ambas as pesquisas é ensinada, diga-se, no nosso Curso de Análise de Conjuntura usando o R.
A coleta dos dados é feita via o SIDRA/IBGE e via o IPEADATA. Os dados são devidamente tratados de forma a poderem ser comparados, uma vez que o CAGED se refere a um fluxo e a PNAD se refere a um estoque.
Feito isso, chegamos ao gráfico abaixo.
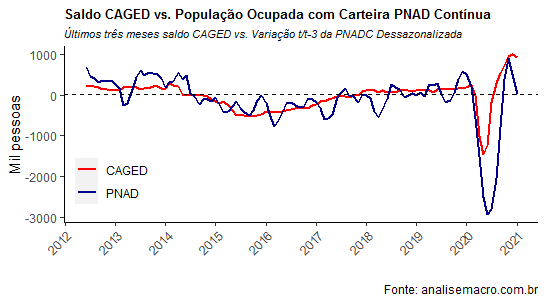
As séries devidamente tratadas mostram uma situação interessante. A PNAD Contínua acabou por sinalizar mais o tombo em 2020 do que o CAGED. Ademais, em exercício anterior feito no âmbito do antigo Clube do Código, os resultados encontrados sugeriam que o CAGED tinha precedência temporal sobre a população ocupada com carteira da PNAD. Essa precedência parece ter mudado, ao incorporar os novos dados do CAGED: há, agora, uma "causalidade" nos dois sentidos. Tanto a população ocupada da PNAD influencia o CAGED, quanto o contrário.
A decomposição de variância entre as séries também mudou bastante. Antes, a variância do CAGED era explicada basicamente pela própria série (quando incluíamos as duas séries em um modelo VEC), hoje cerca de 44% da variância é explicada pela PNAD Contínua. Já a PNAD, antes 44% da variância era explicada pelo CAGEd e o restante pela própria série. Agora, 75% da variância é explicada pela própria série.
Os resultados encontrados sugerem, diga-se, que houve uma mudança significativa na relação entre as duas séries, de modo que a PNAD Contínua pode ter se tornado um sinalizador melhor do que está ocorrendo com o mercado de trabalho.
Uma possível explicação para isso está, claro, na mudança metodológica feita no CAGED em janeiro de 2020, que passou a ter como fonte dos seus dados o eSocial.
O novo exercício será publicado no Clube AM na próxima semana.
Membros do Clube AM, por suposto, têm acesso a todos os códigos de ambos os exercícios.
____________________________


