Em posts anteriores nesse espaço (ver aqui e aqui), comecei a analisar os dados de focos de queimadas no Brasil disponibilizados pelo INPE - ver dados aqui. Nessas oportunidades, chamei atenção para a sazonalidade da série, que é bastante pronunciada. Já aqui, vou fazer uma análise que antecede qualquer esforço de modelagem e previsão: verificar as estatísticas descritivas da série. Antes de continuar, contudo, quero salientar que meu objetivo com esses posts é meramente didático, isto é, quero mostrar como é possível utilizar o R e conhecimentos de estatística/econometria para analisar dados, seja ele qual for. Isso dito, vamos para o RStudio?
De forma a lembrar o que estamos fazendo, carrego no código abaixo os pacotes utilizados, bem como importo uma planilha Excel para o R.
## Pacotes
library(tidyverse)
library(readxl)
library(forecast)
library(scales)
library(gridExtra)
library(TStools)
library(strucchange)
library(seasonal)
Sys.setenv(X13_PATH = "C:/Séries Temporais/R/Pacotes/seas/x13ashtml")
## Coletar dados
data = read_excel('focos.xlsx')
date = seq(as.Date('2003-01-01'), as.Date('2019-08-01'), by='1 month')
data$obs = date
queimadas = ts(data$Focos, start=c(2003,01), freq=12)
Com o código acima, nós estamos importando os dados cedidos pelo Cristiano Oliveira e transformando em série temporal. Já aqui, ressalto, eu atualizei a planilha com os dados fechados de agosto, de modo que isso dá uma visão um pouco melhor sobre o ano de 2019. Fiquei curioso para ver como 2019 se comporta contra a média histórica dos meses, bem como com os máximos e mínimos de cada um desses meses. Para ver isso, eu utilizei o pacote TStools e gerei a tabelinha com o código abaixo.
seas <- seasplot(queimadas, trend=F, outplot = 3)
medias = colMeans(seas$season)
medias = medias[1:8]
matrix = matrix(NA, nrow=8, ncol=2)
for(i in 1:8){
matrix[i,1] = min(seas$season[,i])
matrix[i,2] = max(seas$season[,i])
}
time = seq(as.Date('2019-01-01'), as.Date('2019-08-01'), by='1 month')
table = data.frame(time, matrix[,1], round(medias,0),
tail(data$Focos,8), matrix[,2])
colnames(table) = c('meses', 'min', 'media', 'anoatual', 'max')
Uma vez criada a tabela, gerei o gráfico abaixo.
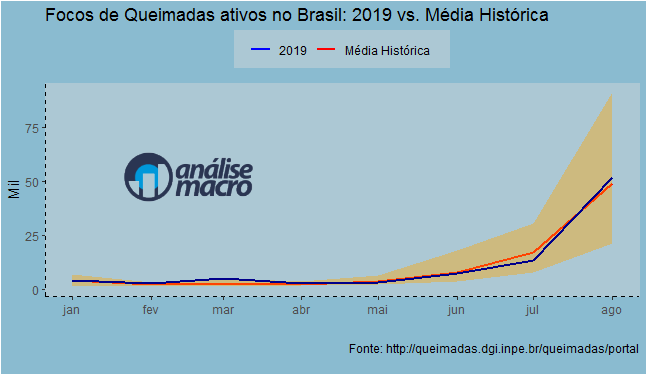
A linha azul representa o ano de 2019, enquanto a linha vermelha representa a média histórica de cada mês. Já a área laranja é composta pelos mínimos e máximos de cada um dos meses. O que se observa é que o foco de queimadas está em linha com a média histórica, dentro dos limites de cada mês. A exceção é o mês de março desse ano, que virou o máximo da amostra com 5.213 focos de queimadas. A média histórica desse mês é de 2.611 focos de queimadas ativos.
Isso feito, eu quis dar uma olhada no formato da distribuição dos focos de queimadas dessazonalizados (para detalhes sobre como dessazonalizar os dados, ver aqui). Para isso, primeiro, vi o boxplot da série com o código abaixo.
queimadas_sa <- final(seas(queimadas))
df = data.frame(date=date,
queimadas_sa=queimadas_sa)
ggplot(df, aes(date, queimadas_sa/1000))+
geom_boxplot(fill='#E69F00', color="black")+coord_flip()+
theme_classic()+xlab('')+ylab('')+
labs(title='Boxplot dos focos de queimadas no Brasil (2003-2019)',
subtitle='Dados dessazonalizados',
caption='Fonte: http://queimadas.dgi.inpe.br/queimadas/portal')
E o boxplot...
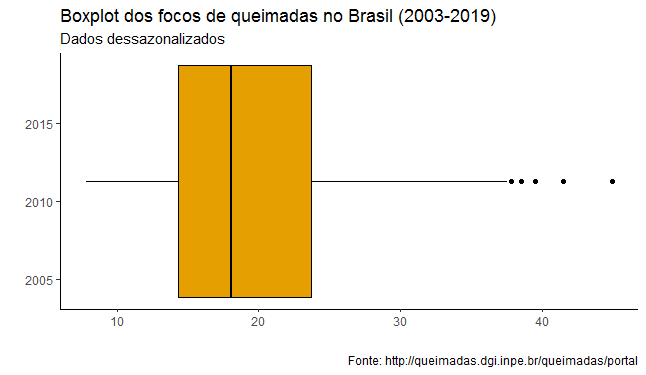
Novamente aqui, os dados referentes a 2019 estão em linha com a média histórica, à exceção de março, que está no último quartil da distribuição. Por fim, vi o histograma da série dessazonalizada com o código abaixo.
ggplot(df, aes(x=queimadas_sa/1000))+
geom_histogram(binwidth = 1, fill='#E69F00', colour='black')+
xlab('')+ylab('')+
labs(title='Histograma dos focos de queimadas no Brasil (2003-2019)',
subtitle='Dados dessazonalizados',
caption='Fonte: http://queimadas.dgi.inpe.br/queimadas/portal')
E o histograma...
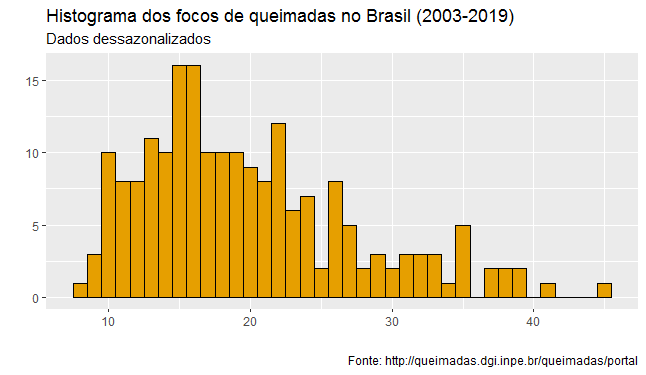
Como esperado, há uma assimetria no formato da distribuição da nossa série. Tudo isso feito, não me parece que 2019 esteja tendo um comportamento diferente dos demais anos.
Esse é, a propósito, o terceiro post dessa série. Um quarto post encerra a série e será publicado nos próximos dias, com um .Rmd completo disponível no Clube do Código. Será a 65ª edição do Clube. Até lá!
____________________
OBS: Para quem gostou da análise descritiva, temos um Curso de Introdução à Estatística usando o R que trata dessas questões.


