Introdução
Mineração de texto, ou text mining, é um tópico muito interessante, pois há um potencial enorme de aplicações para obtenção de insights através dessa técnica envolvendo análise textual. Com a finalidade de demonstrar seu uso, neste post faremos uma breve e introdutória análise das atas do Comitê de Política Monetária - COPOM usando text mining com o auxílio do pacote tidytext.
As atas do COPOM são um caminho natural para qualquer economista em busca de uma fonte de dados para exercitar o text mining, já que a autoridade monetária realiza ajustes (mudanças) no texto a cada reunião, realizada a cada 45 dias. As atas são disponibilizadas publicamente neste link em arquivos PDFs (atualmente há 238 reuniões realizadas). Inicialmente vamos pegar o arquivo da última reunião publicada e importar os dados para o R, fazendo tratamentos e posterior análise. Por fim, vamos coletar os dados de todo o histórico de atas para refazer a análise de forma a incorporar o componente temporal.
Um ponto importante é que utilizaremos as versões em inglês das atas, apesar de o COPOM disponibilizar também em português. Isso se deve ao fato de que as ferramentas aqui utilizadas, para aplicar a técnica de text mining, funcionarem melhor com textos na língua inglesa.
Pacotes
Os pacotes utilizados neste exercício podem ser instalados/carregados com o gerenciador pacman, todos provenientes do CRAN:
# Instalar/carregar pacotes
if(!require("pacman")) install.packages("pacman")
pacman::p_load(
"tidytext",
"pdftools",
"stopwords",
"textdata",
"dplyr",
"tidyr",
"lubridate",
"magrittr",
"knitr",
"ggplot2",
"ggthemes",
"jsonlite",
"purrr",
"stringr",
"scales",
"forcats"
)
Text mining de uma ata do COPOM
Vamos importar a última ata do COPOM para o R. Primeiro criamos um objeto para armazenar o link para o arquivo e, na sequência, usamos a função pdf_text do pacote pdftools para ler cada página do arquivo PDF e transformar os dados em um vetor de caracteres de tamanho igual ao número de páginas.
# URL da última ata do COPOM www <- "https://www.bcb.gov.br/content/copom/copomminutes/MINUTES%20238.pdf" # Ler arquivo PDF convertendo para caracter raw_copom_last <- pdftools::pdf_text(www)
Tratamento de dados
Um primeiro olhar sobre os dados mostrará que há uma série de caracteres especiais "\n" e "\r" que indicam quebras de linhas. Portanto, vamos tratar de forma a obter um objeto tibble com uma coluna (text) com os dados do texto de cada página da ata, outra coluna (meeting) indicando o mês da reunião e a última coluna (page) que informará a página referente ao texto.
# Tratamento de dados
copom_last_clean <- dplyr::tibble(
text = unlist(strsplit(raw_copom_last, "\r"))
) %>%
dplyr::mutate(
meeting = "May 2021",
page = dplyr::row_number(),
text = gsub("\n", "", text)
)
Text mining
Agora estamos com os dados quase prontos para uma análise! O que faremos agora é começar a aplicar algumas das técnicas de text mining provenientes do livro Text Mining with R escrito pela Julia Silge e David Robinson.
O primeiro passo é "tokenizar" nossos dados, de forma a obter "unidades do texto" que servirão para a análise. Isso facilitará para realizarmos a contagem de palavras frequentes, filtrar palavras em específico, etc. O processo de "tokenizar" é definido no livro como:
"A token is a meaningful unit of text, most often a word, that we are interested in using for further analysis, and tokenization is the process of splitting text into tokens."
Para utilizar a técnica, usamos a função unnest_tokens do pacote tidytext e na sequência realizamos a contagem das palavras encontradas:
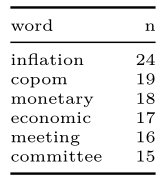
# Text mining - Criar tokens copom_last <- copom_last_clean %>% tidytext::unnest_tokens(word, text) # Contar palavras copom_last %>% dplyr::count(word, sort = TRUE) %>% dplyr::slice_head(n = 6) %>% knitr::kable()

Como podemos observar, as palavras mais frequentes são palavras comuns como "the", "of", "in", etc. que não servirão muito para nossa análise. Essas palavras são chamadas de "stop words" no mundo do text mining. Vamos fazer uma tratativa para remover essas palavras usando como base o objeto stop_words proveniente do pacote tidytext e, antes, removemos também números que foram apontados como "palavras":
copom_last_sw <- copom_last %>%
# Remover palavras comuns (stop words)
dplyr::anti_join(stop_words)%>%
# Remover números
dplyr::mutate(word = gsub("[^A-Za-z ]", "", word)) %>%
# Contar palavras
dplyr::count(word, sort = TRUE) %>%
dplyr::filter(word != "")
copom_last_sw %>%
dplyr::slice_head(n = 6) %>%
knitr::kable()
Agora sim temos os dados prontos para uma análise de sentimento!
Análise de sentimento
Nosso foco agora é usar ferramentas de análise para tirar informação desses dados, ou seja, queremos saber o que as palavras das atas do COPOM podem indicar com base na tentativa de apontarmos um "score" para cada uma delas, usando datasets e bibliotecas de "sentimento do texto" do tidytext para isso.
Vamos ver quais são as palavras negativas e positivas usadas com mais frequência. A função get_sentiments do tidytext fará isso pra gente, bastando apontar um lexicon, que pode ser "bing", "afinn", "loughran" ou "nrc".
# Obter análise de sentimento das palavras com base em uma biblioteca
copom_last_sw %>%
dplyr::inner_join(tidytext::get_sentiments("bing")) %>%
dplyr::slice_head(n = 10) %>%
knitr::kable()
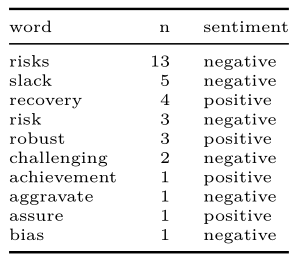 Como resultado, "risks" é a palavra negativa que aparece mais vezes (13 no total) nessa ata do COPOM, e "recovery", uma palavra positiva, é usada 4 vezes no total. Um segundo olhar sobre esse resultado pode levantar uma suspeita, pois "recovery" é apontada como uma palavra positiva (recuperação), no entanto, é razoável supor que pode estar também associada com uma situação anterior negativa. Isso é um possível problema da análise que o leitor pode investigar.
Como resultado, "risks" é a palavra negativa que aparece mais vezes (13 no total) nessa ata do COPOM, e "recovery", uma palavra positiva, é usada 4 vezes no total. Um segundo olhar sobre esse resultado pode levantar uma suspeita, pois "recovery" é apontada como uma palavra positiva (recuperação), no entanto, é razoável supor que pode estar também associada com uma situação anterior negativa. Isso é um possível problema da análise que o leitor pode investigar.
Agora vamos explorar a análise graficamente:
# Análise de sentimento final da ata de Maio/2021
copom_sentiment <- copom_last %>%
dplyr::inner_join(tidytext::get_sentiments("bing")) %>%
dplyr::count(meeting, page, sentiment) %>%
tidyr::pivot_wider(
id_cols = c(meeting, page),
names_from = sentiment,
values_from = n,
values_fill = 0
) %>%
dplyr::mutate(sentiment = positive - negative)
# Gerar gráfico
copom_sentiment %>%
ggplot2::ggplot(ggplot2::aes(page, sentiment, fill = sentiment > 0)) +
ggplot2::geom_col(show.legend = FALSE) +
ggplot2::scale_fill_manual(values = c("#b22200", "#282f6b")) +
ggplot2::labs(
x = "Página da ata",
y = "Sentimento",
title = "Análise de sentimento da Ata do COPOM - Maio/2021",
subtitle = "Bing lexicon",
caption = paste0("Elaboração: analisemacro.com.br\nDados: ", www)
)
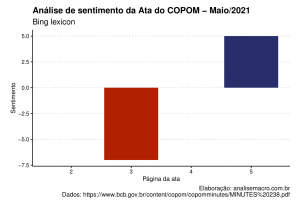
O gráfico conta uma história interessante. O texto começou negativo na página 3 (sobre atualização de conjuntura, cenário e riscos), mas depois foi "neutro" na página 4 (sentimento positivo - negativo = 0) - onde é discutido a condução da política monetária e -, por fim, na última página o texto fica positivo com a decisão da reunião do COPOM.
Vale enfatizar que a primeira página, referente a capa, não é considerada na análise. Já a página 2, da contracapa, possui igual número de palavras negativas e positivas.
Text mining com todas as atas do COPOM
Agora vamos aplicar a técnica apresentada acima para um conjunto maior de dados, desta vez vamos pegar todas as atas disponíveis no site do Banco Central do Brasil - BCB através deste link.
Vamos expandir nossa análise capturando o texto de cada Ata do COPOM desde sua 42ª reunião, totalizando 198 atas para nossa análise. Faremos a comparação da frequência relativa de palavras e tópicos e veremos como o sentimento (conforme explorado acima) varia entre os relatórios.
Dados
Infelizmente, os links para as atas em PDF seguem um padrão irregular, mas felizmente para você, preparei um web-scrapping que automatizará o processo de captura dos links e dados. O código a seguir coletará os arquivos PDF e os deixará prontos para a mineração com o tidytext.
# URL para página com JSON dos links das atas
www_all <- "https://www.bcb.gov.br/api/servico/sitebcb/copomminutes/ultimas?quantidade=2000&filtro="
# Raspagem de dados
raw_copom <- jsonlite::fromJSON(www_all)[["conteudo"]] %>%
dplyr::as_tibble() %>%
dplyr::select(meeting = "Titulo", url = "Url") %>%
dplyr::mutate(url = paste0("https://www.bcb.gov.br", url)) %>%
dplyr::mutate(text = purrr::map(url, pdftools::pdf_text))
# Tratamento de dados
copom_clean <- raw_copom %>%
tidyr::unnest(text) %>%
dplyr::filter(!meeting == "Changes in Copom meetings") %>%
dplyr::group_by(meeting) %>%
dplyr::mutate(
page = dplyr::row_number(),
text = strsplit(text, "\r") %>% gsub("\n", "", .),
meeting = stringr::str_sub(meeting, 1, 3) %>%
stringr::str_remove("[:alpha:]") %>%
as.numeric()
) %>%
dplyr::ungroup() %>%
tidyr::unnest(text) %>%
dplyr::arrange(meeting)
Estatística básica dos dados
Vamos ver o que conseguimos obter calculando algumas estatísticas básicas dos textos.
Número de palavras por ata
# Frequência de palavras por ata copom_words <- copom_clean %>% tidytext::unnest_tokens(word, text) %>% dplyr::count(meeting, word, sort = TRUE) %>% dplyr::ungroup() # Total de palavras por ata total_words <- copom_words %>% dplyr::group_by(meeting) %>% dplyr::summarize(total = sum(n)) # Gerar gráfico total_words %>% ggplot2::ggplot(ggplot2::aes(x = meeting, y = total)) + ggplot2::geom_line(color = "#282f6b", size = 0.8)+ ggplot2::geom_point( shape = 21, fill = "white", color = "#282f6b", size = 1.6, stroke = 1.1 ) + ggplot2::scale_y_continuous(labels = scales::number_format()) + ggplot2::labs( x = "Reunião (nº da ata)", y = "Número de palavras", title = "Número de palavras nas atas do COPOM", subtitle = "42ª até 238ª reunião", caption = "Elaboração: analisemacro.com.br\nDados: BCB" )
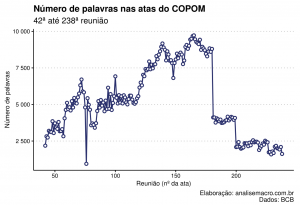
Percebe-se algumas mudanças ao longo do tempo, especialmente entre as reuniões número 180 e 181, onde houve remoção considerável de seções do comunicado na gestão Tombini. No mesmo sentido, de redução do total de palavras por comunicado, o início da gestão de Illan Goldfajn marcou mudança no layout e estrutura das seções da ata, alterações essas que permanecem em vigor até hoje.
A redução do tamanho dos comunicados, de forma geral, é certamente um ponto interessante que merece investigação em se tratando de qualidade de comunicação da política monetária.
Sobre o que os diretores discutiram nas reuniões?
Vamos compilar uma lista das palavras usadas com maior frequência em cada ata. Como antes, vamos omitir as "stop words".
# Palavras por ata
copom_text <- copom_clean %>%
dplyr::select(meeting, page, text) %>%
tidytext::unnest_tokens(word, text)
# Gerar gráfico
copom_text %>%
dplyr::mutate(word = gsub("[^A-Za-z ]", "", word)) %>%
dplyr::filter(word != "") %>%
dplyr::anti_join(stop_words) %>%
dplyr::group_by(meeting) %>%
dplyr::count(word, sort = TRUE) %>%
dplyr::mutate(rank = dplyr::row_number()) %>%
dplyr::ungroup() %>%
dplyr::arrange(rank, meeting) %>%
dplyr::filter(rank < 9, meeting > 230) %>%
ggplot2::ggplot(ggplot2::aes(y = n, x = forcats::fct_reorder(word, n))) +
ggplot2::geom_col(fill = "#282f6b") +
ggplot2::facet_wrap(~meeting, scales = "free", ncol = 4) +
ggplot2::coord_flip() +
ggplot2::labs(
x = "",
y = "",
title = "Palavras mais frequentes nas atas do COPOM",
subtitle = "Excluídas palavras comuns (stop words) e números.",
caption = "Elaboração: analisemacro.com.br\nDados: BCB"
)
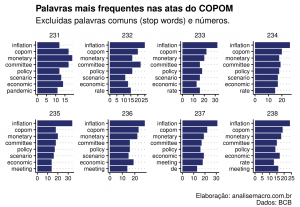
Como esperado, muitas discussões sobre inflação. Vamos tentar encontrar algo mais informativo com esses dados.
Conforme Silge e Robinson, podemos usar a função bind_tf_idf para juntar a frequência do termo (tf) e a frequência inversa do documento (idf) ao nosso conjunto de dados. Essa estatística diminuirá o peso em palavras muito comuns e aumentará o peso em palavras que só aparecem em algumas atas. Em essência, extrairemos o que há de especial em cada ata. As atas do COPOM sempre falarão muito sobre inflação e juros, e a estatística "tf-idf" pode nos dizer algo sobre o que é diferente em cada ata.
Também limparemos alguns termos adicionais que o pdftools captou (abreviações e palavras estranhas ou fragmentadas), aumentando nossa lista de "stop words".
# Stop words personalizadas
custom_stop_words <- dplyr::bind_rows(
dplyr::tibble(
word = c(
tolower(month.abb),
tolower(month.name),
"one","two","three","four","five","six","seven","eight","nine","ten",
"eleven","twelve", "wkh", "ri", "lq", "month", "wr", "dqg",
"hdu", "jurzwk", "zlwk", "zlwk", "hfhpehu", "dqxdu", "kh", "sulfh", "dv",
"kh", "prqwk", "hdu", "shulrg", "dv", "jurzwk", "wkdw", "zdv", "iru", "dw",
"wkdw", "jrrgv", "xqh", "eloolrq", "eloolrq", "iluvw", "dq", "frqvxphu",
"prqwk", "udwh", "sulo", "rq", "txduwhu", "vhfwru", "pandemic",
"dffxpxodwhg", "hg", "kdyh", "sdqghg", "sulfhv", "rq", "sdqvlrq",
"percent", "forvhg", "frpsduhg", "lqgh", "ryhpehu", "wklv", "kdv", "prqwkv",
"bcbgovbr", "banco", "head"
),
lexicon = c("custom")
),
stop_words
)
# Palavras por ata
copom_text_refined <- copom_text %>%
dplyr::mutate(word = gsub("[^A-Za-z ]", "", word)) %>%
dplyr::filter(word != "") %>%
dplyr::group_by(meeting) %>%
dplyr::count(word, sort = TRUE) %>%
tidytext::bind_tf_idf(word, meeting, n) %>%
dplyr::arrange(desc(tf_idf))
# Gerar gráfico
copom_text_refined %>%
dplyr::anti_join(custom_stop_words, by = "word") %>%
mutate(word = factor(word, levels = rev(unique(word)))) %>%
dplyr::group_by(meeting) %>%
dplyr::mutate(id = dplyr::row_number()) %>%
dplyr::ungroup() %>%
dplyr::filter(id < 9, meeting > 230) %>%
ggplot2::ggplot(ggplot2::aes(y = tf_idf, x = word, fill = meeting)) +
ggplot2::geom_col(show.legend = FALSE) +
ggplot2::facet_wrap(~meeting, scales = "free", ncol = 4) +
ggplot2::coord_flip() +
ggplot2::labs(
x = "",
y = "tf-idf",
title = "Palavras mais distintas nas atas do COPOM",
subtitle = "Estatística tf-idf do tidytext",
caption = "Elaboração: analisemacro.com.br\nDados: BCB"
) +
ggplot2::theme(axis.text.x = ggplot2::element_text(angle = 45, hjust = 1))
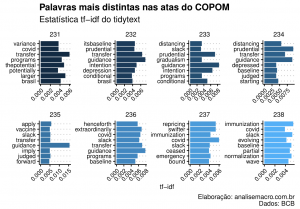
Esse gráfico já mostram uma história interessante dessa amostra que escolhemos. Podemos observar preocupações com o BREXIT, reformas e agenda econômica, o surgimento do termo "covid" a partir da ata nº 231 e subsequente adoção do forward guidance e, por fim, também como destaque, a mudança da política para uma "normalização parcial" (termos "partial" e "normalization").
Comparando o sentimento entre as atas
Como o sentimento variou entre as atas? Vamos usar a abordagem que usamos no início para a ata de maio/2021 e aplicá-la a cada ata.
# Análise de sentimento das atas
copom_sentiment_all <- copom_text %>%
dplyr::anti_join(stop_words) %>%
dplyr::inner_join(tidytext::get_sentiments("bing")) %>%
dplyr::count(meeting, page, sentiment) %>%
tidyr::pivot_wider(
id_cols = c(meeting, page),
names_from = sentiment,
values_from = n,
values_fill = 0
) %>%
dplyr::mutate(sentiment = positive - negative)
# Gerar gráfico
copom_sentiment_all %>%
dplyr::filter(meeting > 230) %>%
ggplot2::ggplot(ggplot2::aes(page, sentiment, fill = sentiment > 0)) +
ggplot2::geom_col(show.legend = FALSE) +
ggplot2::scale_fill_manual(values = c("#b22200", "#282f6b")) +
ggplot2::facet_wrap(~meeting, ncol = 4, scales = "free_x") +
ggplot2::annotate("segment", x = -Inf, xend = Inf, y = -Inf, yend = -Inf)+
ggplot2::annotate("segment", x = -Inf, xend = -Inf, y = -Inf, yend = Inf) +
ggplot2::labs(
x = "Página da ata",
y = "Sentimento",
title = "Análise de sentimento das Ata do COPOM",
subtitle = "Bing lexicon, amostra das últimas 8 atas",
caption = "Elaboração: analisemacro.com.br\nDados: BCB"
)
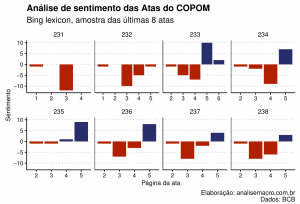
O resultado mostra que o sentimento mudou consideravelmente no texto das atas da amostra das últimas 8 reuniões, com forte predominância "negativa" desde o advento da pandemia da Covid-19.
Conclusão
Isso é tudo por hoje. Essas técnicas são muito interessantes e promissoras, merecendo exploração aprofundada. Certamente o exercício aqui apresentado possui falhas e pontos de melhoria, mas serve como uma introdução ao tema. Espero que goste, caro leitor!
Possui interesse no tema de política monetária? A Análise Macro disponibiliza o curso de Teoria da Política Monetária dentro da temática de Central Banking. Aproveite!
_____________

