O aumento do preço dos combustíveis tem sido um grande fardo para os brasileiros, impactando direta ou indiretamente o custo de vida. Em 2021, itens como gasolina e etanol contribuíram para grande parte da inflação anual, sendo a gasolina o produto de maior peso no índice. Apesar dessa dinâmica ter sido incorporada em nosso cotidiano e ser onipresente nos noticiários, pouco se fala sobre de onde esses dados saem e como são analisados. O texto de hoje explora uma forma simples de acesso aos microdados da ANP para analisar os preços de combustíveis ao longo do tempo.
Microdados da ANP
A Agência Nacional do Petróleo, Gás Natural e Biocombustíveis (ANP) acompanha e divulga periodicamente os preços praticados por revendedores de combustíveis automotivos e de gás em botijões, por meio de uma pesquisa semanal realizada por empresa contratada (saiba mais neste link). Os dados disponibilizados são desagregados por semestre/ano e possuem informações sobre os municípios, bairros, CEP, empresas de revenda, tipo de produto, unidade de medida e preços nominais de compra e de venda. Sendo assim, há um amplo conjunto de dados que pode ser utilizado para finalidades diversas.
Conforme mencionado, neste exercício acessaremos esses microdados da ANP para avaliar a evolução dos preços de revenda de combustíveis no Brasil, em termos reais.
Como acessar os dados?
Os dados brutos são disponibilizados na página da ANP (clique aqui), onde há informações sobre metadados e links de arquivos CSV para download. Como é frequente em bases de dados públicas, a ANP disponibiliza os dados em diversos arquivos separados (por semana, mês, semestre, ano, produto, etc.), o que torna a tarefa de baixar estes arquivos um tanto quanto tediosa — mesmo que por linguagem de programação —, sem mencionar os tratamentos que são necessários até finalmente poder utilizar os dados. E agora, o que fazer?
Como alternativa, existe o projeto Base dos Dados que, em resumo, já possui pronta uma infraestrutura de banco de dados com tabelas tratadas para acessar os microdados da ANP (e muitos outros). Sendo assim, não teremos nenhum trabalho "sujo" de baixar e tratar inúmeros arquivos CSV, tudo que será necessário é uma conta no Google e uma linguagem de programação de preferência (aqui utilizaremos o R). Graças ao projeto, com uma ou duas funções do pacote {basedosdados} já temos acesso aos microdados da ANP; e a partir daí é só fazer sua análise!
Acessando os dados
Partindo para a prática, precisaremos de dois dados para cumprir o proposto no exercício:
- Microdados de preços nominais praticados por revendedores de combustíveis (ANP);
- Índice de preços para deflacionamento (IPCA/IBGE).
No primeiro caso utilizaremos o pacote {basedosdados} para acessar e coletar os microdados, e no segundo usaremos o pacote {sidrar} para a coleta da tabela do IPCA no SIDRA. Caso precise, dê uma olhada nesse post para saber mais sobre como acessar dados do SIDRA no R.
Para prosseguir, certifique-se de que tenha os seguintes pacotes disponíveis em sua instalação de R:
Partindo do princípio de que você nunca utilizou o pacote {basedosdados} antes, a seguir explicamos em 4 passos o que deve ser feito para acessar os microdados.
- Passo 1: crie um projeto no Google Cloud
Para criar um projeto no Google Cloud basta ter um e-mail cadastrado no Google. É necessário ter um projeto seu, mesmo que vazio, para você fazer consultas nas tabelas públicas da Base dos Dados.
a) Acesse o Google Cloud. Caso for a sua primeira vez, aceite o Termo de Serviços.
b) Clique em Create Project/Criar Projeto. Digite um nome bacana para o projeto.
c) Clique em Create/Criar.
d) Copie o Project ID/ID do projeto fornecido na página do projeto criado.

Fonte: Base dos Dados
- Passo 2: definir o ID do Projeto
Depois de obter o Project ID/ID do projeto, você deve passar essa informação para o pacote {basedosdados} configurar seu RStudio, através da função set_billing_id(). Note que o ID do Projeto abaixo não funcionará se você tentar utilizá-lo.
Você deve receber, no Console, a mensagem de sucesso acima.
- Passo 3: fazer a conexão com o banco de dados onde a tabela de interesse está armazenada
a) Primeiro precisamos do nome do banco de dados/tabela. Essa informação você encontra no site da Base dos Dados;
b) Para a tabela dos microdados da ANP, nesta página, clique na tabela "microdados";
c) Navegue até a seção "Consulta aos dados" e clique no botão "R";
d) No código exibido, copie o que estiver entre os parênteses da função bdplyr().
Com as informações necessárias em mãos, cole o código de tabela/banco de dados na função bdplyr() para fazer a conexão:
Se estiver tudo certo, você deve receber a última mensagem acima no Console (veja detalhes a seguir).
Se é a primeira vez que você está realizando este procedimento você receberá uma pergunta interativa no Console, como essa:
Fecthing Billing Project Id from enviroment variables defined by user. Is it OK to cache OAuth access credentials in the folder ~/.cache/gargle between R sessions?
1: Yes
2: No
Digite 1 e pressione Enter para confirmar.
Se não é a primeira vez (no caso de você já ter feito essa configuração previamente), aparecerá uma mensagem perguntando qual conta do Google deseja utilizar, informe o dígito correspondente, pressione Enter e pule a próxima seção deste tutorial.
Autenticação no Google
Após isso, você será redirecionado para uma página de login e autenticação do Google.
a) Faça o login com seu e-mail/senha;
b) Confirme a autenticação de acesso para poder utilizar o serviço Google BigQuery no R, marcando todas as caixas de seleção;
c) Será gerado um código de autenticação ao final do processo, copie o código e cole no Console do R, na mensagem dizendo "Enter authorization code".
Após este processo, e a mensagem de confirmação de conexão com a tabela, já podemos trabalhar com os dados no R!
Verificando o resultado
Com a conexão com o banco de dados realizada, já é possível fazer operações com o {tidyverse}:
Tratamento e coleta dados
- Passo 4: criar consulta (filtros, seleções, etc.) para coletar os dados
Nessa etapa iremos manipular os dados brutos no banco de dados obtendo preços médios por mês/ano e produto para, então, fazer a coleta de dados com a função bd_collect():
Uma vez finaliza essa configuração, acesso, tratamentos e coleta de microdados da ANP, direcionamos agora o foco para os dados do SIDRA. O código abaixo irá coletar e tratar o número índice do IPCA mensal, disponibilizado na tabela 1737 do SIDRA, assim como cruzar estes dados com a base de preços nominais da ANP:
Com todos os dados coletados e tratados, podemos prosseguir com o deflacionamento dos preços nominais de preços de combustíveis da ANP, ou seja, aplicar a fórmula1:
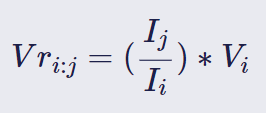
onde:
Vri:j é o valor real, ou deflacionado, no período i na data-base j
Ijé o índice de preços fixado na data-base j
Ii é o índice de preços no período i
Vi é o valor ou preço nominal no período i
O código abaixo deflaciona os preços com a data-base fixada no último mês/ano observado:
Visualização de dados
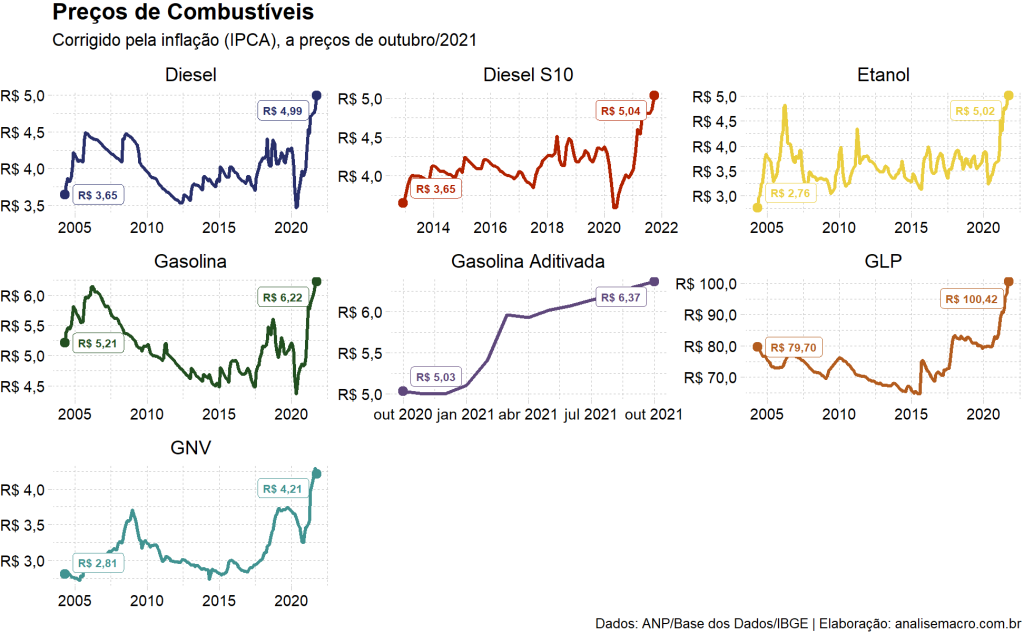
Por fim, vamos gerar uma visualização de dados. O objetivo é gerar um simples gráfico de linha que permita comparar o preço real dos combustíveis ao longo do tempo. Note que para a maioria dos produtos dessa base as séries iniciam em 2004 e terminam em 2021. Para dados mais atualizados é necessário buscar os arquivos direto no site do ANP.
O gráfico fala por si só o que o brasileiro vem sentindo no bolso nos últimos meses:
 Saiba mais
Saiba mais
 Saiba mais
Saiba maisPara se aprofundar mais sobre como lidar e analisar estes e outros microdados, confira o curso Análise de Microdados Brasileiros usando o R.
Outros posts sobre microdados:
- Acessando microdados da PNAD Contínua no R
- Como estimar o índice de Gini no R
- Acessando dados do Bolsa Família no R
- Acessando dados do Censo Demográfico com o R
1 Para entender mais sobre veja este post.

