
Hoje inauguramos uma série de exercícios temáticos sobre as Eleições de 2022, trazendo dados, análises e códigos sobre esse tema polêmico. De início, exploramos os dados disponíveis, verificando formas de acesso e análises que podem ser feitas, utilizando a linguagem R. Como exemplo, hoje analisamos a estratégia de redes sociais dos candidatos/partidos com os dados do TSE.
Aviso: dados e análises aqui apresentadas não refletem apoio político do autor ou da empresa Análise Macro.
Dados
Existem vários conjuntos de dados disponíveis, estruturados ou não, sobre a temática eleição e política aqui no Brasil. Para colocar em números, somente no TSE existem mais de 130 datasets até a data de hoje. Em geral, você encontra estruturas de dados do tipo microdados e séries temporais. Abaixo listamos alguns exemplos de datasets disponíveis, por fonte:
- Portal de Dados Abertos do TSE:
- Candidatos: informações sobre os candidatos nas eleições (desde 1933), como perfil, cargo concorrido, partido, declarações de bens, etc;
- Resultados: informações sobre os resultados das eleições (desde 1933), em termos de votação, boletim da urna, da seção eleitoral, etc;
- Pesquisas eleitorais: informações sobre pesquisas eleitorais (desde 2012), como questionários, notas fiscais, plano amostral, metodologia, etc;
- Eleitorado: informações sobre os eleitores nas eleições (desde 1994), como perfil, domicílio eleitoral, grau de escolaridade, gênero, etc.
- Poder 360: pesquisas eleitorais da empresa Poder360;
- CEPESP Data: dados do TSE tratados e disponibilizados de forma integrada, com indicadores analíticos e aplicativos web para consulta e interação.
Formas de acesso
O acesso aos conjuntos de dados sobre a temática de eleições pode ser feito por diferentes meios, a depender da forma de disponibilização (arquivos de download, API, etc.). Usando as linguagens R ou Python destacam-se algumas opções:
- Base dos Dados: projeto colaborativo que disponibiliza um banco de dados estruturado com tabelas tratadas, podendo ser consultadas através de pacotes/bibliotecas no R, Python, SQL, etc;
- Portal de Dados Abertos do TSE: arquivos brutos (geralmente compactados como .zip), organizados por tema e ano, podendo ser importados e tratados em um ambiente de programação através de links de download;
- Pacote {electionsBR} no R: oferece funções para coleta e tratamento automatizado dos dados do TSE, simplificando e economizando várias linhas de código.
Neste exercício vamos mostrar como "beber diretamente da fonte", ou seja, vamos coletar e tratar os dados brutos do TSE diretamente de seu Portal. Essa opção tem como vantagem a maior flexibilidade de escolha de quais dados serão alvo de análise, assim como quais tratamentos serão aplicados, possibilitando analisar dados novos/recém lançados ou que ainda não estão disponíveis nas outras opções.
Exemplo no R
Como exemplo didático, neste exercício vamos mostrar como acessar os dados eleitorais do TSE limitando o escopo a apenas dois conjuntos de dados:
- Candidatos: traz informações sobre o cargo do candidato, nome, número, partido, coligação, situação do registro de candidatura, gênero, escolaridade, a unidade eleitoral (abrangência territorial), prestação de contas, chave para cruzamento com outras tabelas do TSE e etc;
- Redes sociais dos candidatos: traz informações da chave de identificação do candidato para cruzamento com outras tabelas do TSE e sobre as redes sociais (links) de campanha declaradas pelo candidato.
Conforme mencionado, os conjuntos de dados são organizados por ano da eleição, portanto focaremos na eleição deste ano (2022). Por ser a eleição atual, vale dizer que a maioria dos cadastros dos candidatos ainda está em situação de "cadastro" na data de hoje (10 de agosto de 2022), ainda esperando o julgamento da Justiça Eleitoral para serem alterados para "apto" ou "inapto". Portanto, recomendamos cuidado e atenção ao analisar os dados, além de sempre consultar a documentação das tabelas no arquivo de "LEIA ME" que é disponibilizado em conjunto aos dados.
O Portal de Dados do TSE pode ser acessado pelo link: https://dadosabertos.tse.jus.br/
Agora vamos aos códigos!
O primeiro passo é localizar no Portal do TSE o(s) link(s) para o(s) conjunto(s) de dados de interesse. Em nosso exemplo, as tabelas de Candidatos e de Redes sociais estão organizadas dentro do dataset "Candidatos - 2022", onde encontramos os links abaixo para os arquivos compactados (.zip) que possuem os CSVs para importação. Partindo do princípio de que você não gosta de procedimentos manuais, o segundo passo é utilizar uma função de download apontando os links identificados para automatizar a extração dos dados, conforme abaixo:
Com o código acima nós utilizamos o poder do R para facilmente acessar o Portal do TSE e baixar os arquivos dos conjuntos de dados de interesse para o computador. Note que o código salva tudo em uma pasta "data" no diretório atual de trabalho do R. Em seguida, o terceiro passo é descompactar os arquivos .zip baixados para disponibilizar os arquivos CSV para importação (quarto passo). Para importar os dados é necessário especificar a codificação de caracteres do arquivo, que neste caso é "Latin-1". O código abaixo faz isso de maneira automatizada:
Por fim, cruzamos as duas tabelas utilizando a chave interna do TSE — variável SQ_CANDIDATO, não é o número de campanha do candidato —, de modo a possibilitar a análise dos dados em uma única tabela com as variáveis de interesse:
Análises
A parte (nem tanto) difícil já passou e agora que você tem os dados em mãos fica mais fácil analisá-los, ainda mais ao utilizar os pacotes do {tidyverse} no R. Diversas análises podem ser feitas com estes dados: no exemplo abaixo relacionamos as principais redes sociais cadastradas pelos candidatos, apresentando o quantitativo de candidatos em cada rede (note que um mesmo candidato pode cadastrar mais de uma rede social para campanha política):

Códigos de replicação deste exercício estão disponíveis para membros do Clube AM.
Podemos notar que a maioria dos candidatos tem como estratégia de campanha o uso de redes sociais "consagradas", como o Facebook e Instagram. Podemos fazer essa mesma análise em termos mais desagregados, olhando no nível estadual:

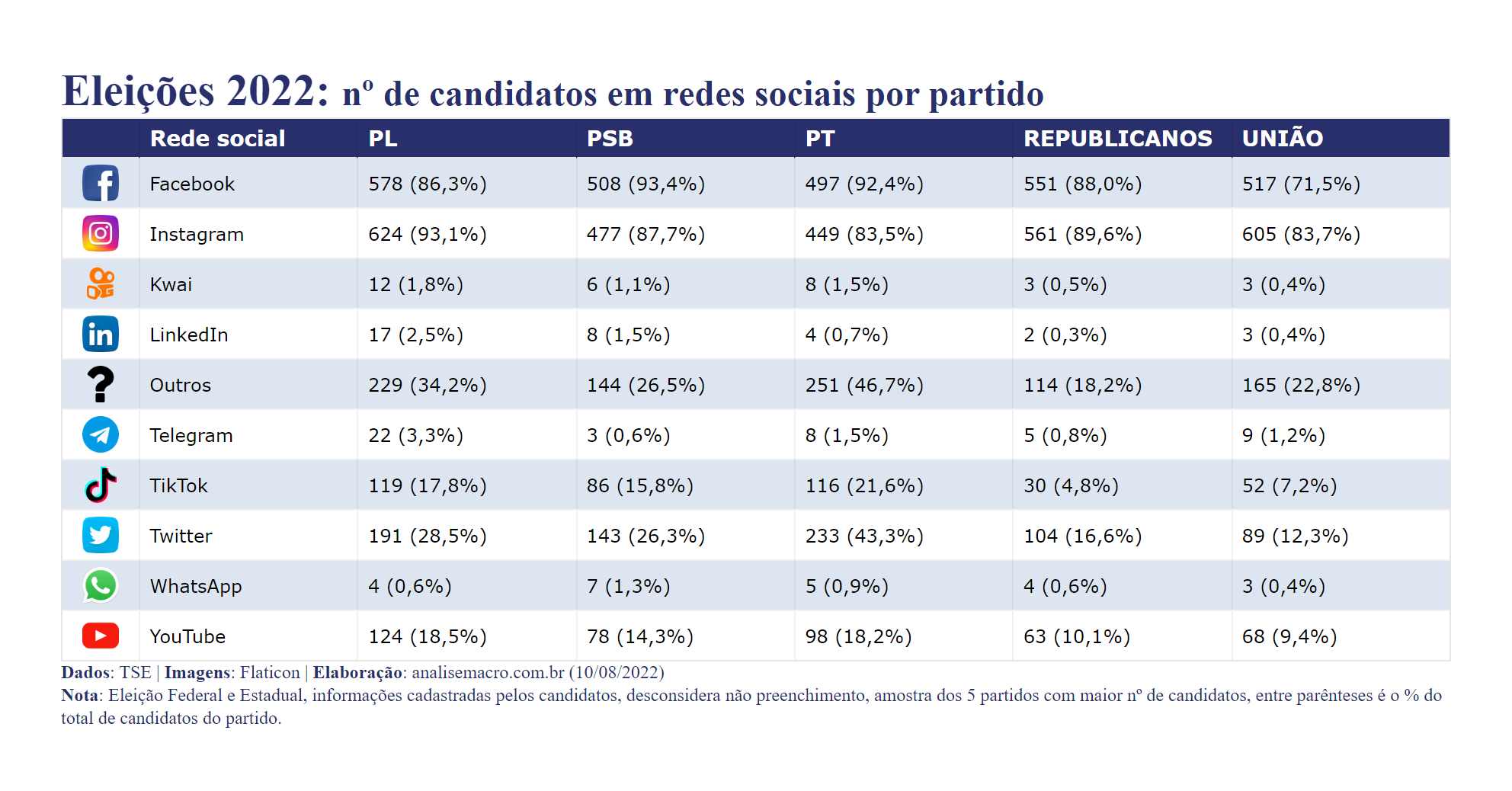
O mapa mostra um padrão interessante e, ao mesmo tempo, curioso: as redes sociais Facebook e Instagram predominam na estratégia de campanha da maioria dos candidatos e "dividem" o país meio a meio. Por fim, apresentamos dados sumarizados sobre as redes sociais dos candidatos a nível de partido na tabela abaixo:
Saiba mais
Para saber mais sobre dados eleitorais, R, programação e análise de dados faça parte do Clube AM e confira o curso de Microdados Brasileiros, onde tratamos de dados eleitorais e vários outros.
Códigos de replicação deste exercício estão disponíveis para membros do Clube AM.
Na próxima semana analisaremos o efeito das eleições sobre os preços de ações de empresas estatais brasileiras, não perca!

