Segundo a pesquisa “State of Data Science”, profissionais de dados gastam 3 horas/dia (38% do tempo) apenas preparando os dados, antes mesmo de analisá-los. Olhando mais a fundo, muitos destes profissionais utilizam ferramentas fechadas no trabalho (como Excel).
Neste artigo advogamos que este gasto de tempo pode ser drasticamente reduzido ao utilizar ferramentas open source, como Pandas e Python, para automatizar tarefas repetitivas que costumam ser feitas em Excel.
Um exemplo prático
Olhe para esta tabela:
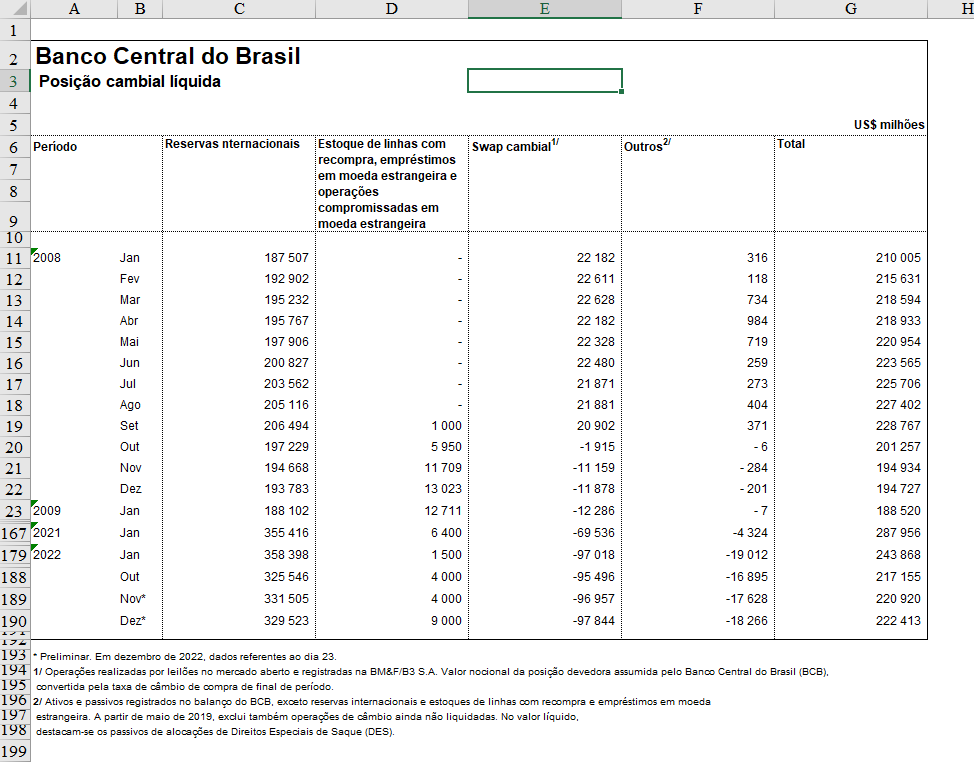
Agora se pergunte: o que há de errado nesta tabela?
Para responder esta pergunta é preciso pensar com a cabeça de um analista ou cientista de dados. No dia a dia, estes profissionais precisam de uma tabela de dados pronta para gerar análises e modelos. A tabela acima está pronta para isso? Não (mesmo que ela “pareça” bonita)!
A tabela acima precisa de tratamentos de dados e o primeiro passo é identificar os problemas. Aqui podemos listar alguns:
- No início da tabela há informações textuais que não são dados;
- Os dados não estão nas primeiras linhas do arquivo;
- Os nomes de colunas estão separados em várias linhas;
- Existem células mescladas;
- Os nomes de colunas são enormes;
- A coluna de datas está separada em duas;
- O formato das datas não segue o padrão internacional;
- No final da tabela há informações textuais que não são dados.
- Há observações preliminares, sujeitas a alteração.
Aprenda a coletar, processar e analisar dados na formação de Do Zero à Análise de Dados com Python.
Em outras palavras, um analista ou cientista de dados que precisar utilizar os dados desta tabela terá um bom trabalho inicial de tratamento de dados.
No mundo ideal, uma tabela de dados deve ser estruturada de forma que:
- Cada variável tem sua própria coluna
- Cada observação tem sua própria linha
- Cada valor tem sua própria célula

Sendo assim, vamos exemplificar agora passo a passo como pegar a tabela acima e tratar os dados para que a tabela fique em um formato mais propício para análise de dados no Python, sem precisar clicar em múltiplos botões ou usar fórmulas obscuras do Excel.
Passo 01: bibliotecas de Python
Utilizaremos as bibliotecas abaixo para ter acesso à funções úteis de tratamento e análise de dados:
- pandas: serve para importar, tratar, analisar e visualizar os dados;
- dateparser: serve para tratar dados temporais, como datas, horas, etc;
- plotnine: serve para gerar gráficos.
Para obter o código e o tutorial deste exercício faça parte do Clube AM e receba toda semana os códigos em R/Python, vídeos, tutoriais e suporte completo para dúvidas.
Passo 02: coleta de dados
Utilizaremos os dados da planilha de Excel chamada “Posição cambial líquida do Banco Central” disponível publicamente no site do Banco Central. Trata-se de uma planilha que precisa de alguns tratamentos para possibilitar a análise dos dados.
| ano | mes | Reservas | Estoque | Swaps | Outros | Total | |
|---|---|---|---|---|---|---|---|
| 0 | 2008.0 | Jan | 187507.153378 | 0.0 | 22181.689685 | 316.306128 | 210005.149190 |
| 1 | NaN | Fev | 192901.820218 | 0.0 | 22611.267756 | 117.924210 | 215631.012184 |
| 2 | NaN | Mar | 195231.614870 | 0.0 | 22627.569639 | 734.455027 | 218593.639536 |
| 3 | NaN | Abr | 195766.858581 | 0.0 | 22182.366580 | 983.883236 | 218933.108397 |
| 4 | NaN | Mai | 197906.274052 | 0.0 | 22328.470465 | 718.792263 | 220953.536780 |
Note que ao utilizar as opções corretas de importação dos dados já eliminamos diversos problemas existentes na planilha Excel, obtendo dados mais limpos e quase prontos para análise.
Passo 03: tratamento de dados
Os tratamentos de dados que aplicaremos nesta tabela são dois procedimentos relativamente simples:
- Juntar as colunas “ano” e “mes” em um única coluna chamada “data” com a informação do período no formato internacional ano-mês-dia (YYYY-MM-DD);
- Pivotar a tabela, ou seja, empilhar as colunas numéricas em uma única coluna chamada “valor” e colocar os nomes identificadores destes números em outra coluna chamada “variável”.
Com isso temos uma tabela pronta para gerar um gráfico ou fazer uma análise mais aprofundada:
| data | variavel | valor | |
|---|---|---|---|
| 0 | 2008-01-01 | Reservas | 187507.153378 |
| 1 | 2008-02-01 | Reservas | 192901.820218 |
| 2 | 2008-03-01 | Reservas | 195231.614870 |
| 3 | 2008-04-01 | Reservas | 195766.858581 |
| 4 | 2008-05-01 | Reservas | 197906.274052 |
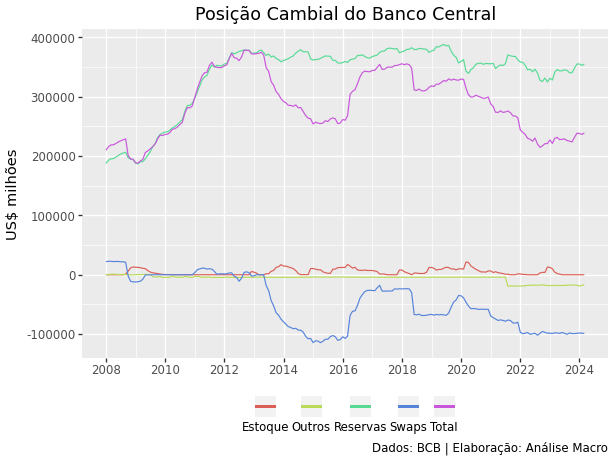
Passo 04: visualização de dados
Com os dados tratados, agora é possível gerar gráficos e fazer análises rapidamente:
Conclusão
Segundo a pesquisa “State of Data Science”, profissionais de dados gastam 3 horas/dia (38% do tempo) apenas preparando os dados, antes mesmo de analisá-los. Neste artigo advogamos que este gasto de tempo pode ser drasticamente reduzido ao utilizar ferramentas open source, como Pandas e Python, para automatizar tarefas repetitivas que costumam ser feitas em Excel.
Quer aprender mais?
Clique aqui para fazer seu cadastro no Boletim AM e baixar o código que produziu este exercício, além de receber novos exercícios com exemplos reais de análise de dados envolvendo as áreas de Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas diretamente em seu e-mail.

