Quando o objetivo é analisar dados, é necessário utilizar as ferramentas adequadas para tornar os dados brutos em informação que seja útil. Para tal objetivo, uma dashboard pode ser o formato mais conveniente, dado seu poder de customização, compartilhamento e automatização. Nesse contexto, exploramos como exemplo a construção de uma dashboard simples aplicada à análise dos dados de inflação do Brasil, fazendo uso dos principais pacotes do R.
Visão geral
O objetivo geral é construir uma dashboard dinâmica onde seja possível analisar o comportamento histórico dos principais indicadores para acompanhamento de conjuntura do tema inflação, tais como: IPCA, IGP-M, INPC, etc. Além disso, para dar mais autonomia ao usuário final da dashboard, a mesma contará com opções de filtros de datas, indicadores, medidas, etc., tornando possível uma análise mais customizável.
Em resumo, a dashboard terá a seguinte aparência:
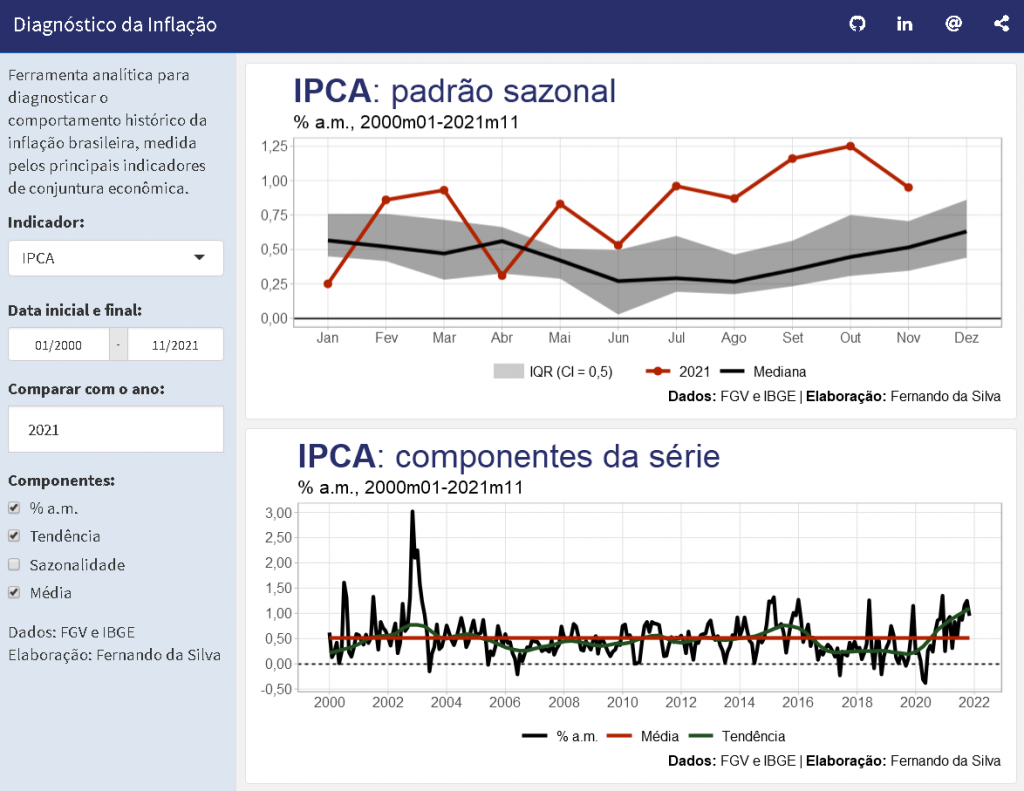
Você também pode conferir o resultado completo neste link.
Pacotes e framework
Para construir a dashboard você precisará dos seguintes pacotes disponíveis em sua instalação de R:
# Carregar pacotes library(shiny) library(ggplot2) library(readr) library(lubridate) library(dplyr) library(stringr) library(forcats) library(tidyr) library(scales) library(ggtext) library(tsibble) library(fabletools) library(feasts) library(Hmisc) library(rmarkdown) library(flexdashboard)
Optou-se por utilizar o framework dos pacotes shiny e flexdashboard, que oferecem uma sistemática de programação reativa e sintaxe simples e amigável, respectivamente, tornando o processo de criação de dashboards dinâmicas mais fácil. Além disso, a dashboard foi hospedada no serviço shinyapps.io e automatizada usando o GitHub Actions (confira neste link um tutorial de uso).
Para aprofundamento e detalhes confira o Curso de Análise de Conjuntura usando o R.
Criando a dashboard
O primeiro passo é criar um projeto do RStudio, para isso use usethis::create_project("nome_do_projeto").
Em seguida, criamos o arquivo principal da dashboard utilizando o template básico oferecido pelo pacote flexdashboard: basta navegar pelos menus File > New File > R Markdown > From Template > Flex Dashboard {flexdashboard} > OK e salvar o arquivo .Rmd na raiz do projeto.
No arquivo editamos os metadados com as definições desejadas para a dashboard, conforme abaixo:
---
title: "Diagnóstico da Inflação"
output:
flexdashboard::flex_dashboard:
orientation: rows
source_code: NULL
social: menu
navbar:
- { icon: "fa-github", href: "https://ENDEREÇO_DO_SITE/", align: right }
- { icon: "fa-linkedin", href: "https://ENDEREÇO_DO_SITE/", align: right }
- { icon: "fa-at", href: "mailto:MEU@EMAIL.COM", align: right }
runtime: shiny
---
Agora podemos começar a trabalhar nos dados e elementos visuais da dashboard. No primeiro chunk do documento (global) especificamos os pacotes, carregamos os dados e definimos objetos úteis a serem utilizados nos gráficos.
Os dados ficam salvos em uma pasta chamada "data" e são atualizados automaticamente por um script independente, visando diminuir dependências e tempo de carregamento da dashboard. Neste link você pode baixar os dados para poder reproduzir o exemplo.
# Carregar pacotes
library(shiny)
library(ggplot2)
library(readr)
library(lubridate)
library(dplyr)
library(stringr)
library(forcats)
library(tidyr)
library(scales)
library(ggtext)
library(tsibble)
library(fabletools)
library(feasts)
library(Hmisc)
# Carregar dados públicos previamente importados via pacotes
tbl_inflation <- readr::read_rds("data/tbl_inflation.rds")
# Objetos úteis na dashboard
colors <- c(
blue = "#282f6b",
red = "#b22200",
yellow = "#eace3f",
green = "#224f20",
purple = "#5f487c",
black = "black"
)
Em seguida, criamos uma linha usando cabeçalho Markdown de nível dois (------------------) e determinamos que esse elemento seja a sidebar da dashboard. Essa barra lateral é, usualmente, onde são exibidos os filtros e opções de interatividade, além de poder servir de espaço para textos informativos. No nosso exemplo, colocamos um texto breve e definimos, conforme chunk abaixo, os inputs que criamos através do shiny para aplicar filtros e manipulações de dados:
# Cria input do tipo "lista de caixas de seleção" com índices de preços como opções
# Objetivo: usuário pode escolher quaL indicador será exibido no gráfico
shiny::selectInput(
inputId = "variavel",
label = shiny::strong("Indicador:"),
choices = unique(tbl_inflation$variable),
selected = unique(tbl_inflation$variable)[1],
multiple = FALSE
)
# Cria input do tipo "calendário" de seleção de data de início e fim
# Objetivo: usar as datas selecionadas para filtrar amostra de dados utilizada no gráfico/cálculos
shiny::dateRangeInput(
inputId = "data",
label = shiny::strong("Data inicial e final:"),
min = min(tbl_inflation$date),
max = max(tbl_inflation$date),
start = min(tbl_inflation$date),
end = max(tbl_inflation$date),
language = "pt-BR",
separator = " - ",
format = "mm/yyyy"
)
# Cria input do tipo "campo numérico" para entrada de um ano para comparação
# Objetivo: comparar medidas (mediana e IQR) com dados observados referente ao ano
shiny::numericInput(
inputId = "ano",
label = shiny::strong("Comparar com o ano:"),
value = lubridate::year(max(tbl_inflation$date)),
min = lubridate::year(min(tbl_inflation$date)),
max = lubridate::year(max(tbl_inflation$date)),
step = 1
)
# Tratamento para atualizar o ano pré-selecionado no input$ano em resposta a uma
# mudança da amostra de dados definida pelo usuário no input$data:
# o objetivo é que quando o usuário diminui a amostra de dados, o ano de comparação
# selecionado não fique fora dessa nova amostra e seja atualizado para um novo
# valor o mais próximo possível dos valores extremos (anos) da nova amostra
shiny::observeEvent(
eventExpr = input$data, # observa mudanças do usuário na amostra de dados
handlerExpr = { # expressões que serão executadas quando input$data mudar
data_inicial <- lubridate::year(input$data[1])
data_final <- lubridate::year(input$data[2])
shiny::updateNumericInput( # atualiza o valor de input$ano quando a mudança é detectada
inputId = "ano",
value = if(!input$ano %in% data_inicial:data_final & data_inicial > input$ano){
data_inicial
} else
if(!input$ano %in% data_inicial:data_final & data_final < input$ano){
data_final
} else input$ano,
min = data_inicial,
max = data_final,
step = 1
)
}
)
# Cria input do tipo "lista de caixas de seleção" com componentes para filtragem
shiny::checkboxGroupInput(
inputId = "componentes",
label = shiny::strong("Componentes:"),
choices = c("% a.m.", "Tendência", "Sazonalidade", "Média"),
selected = c("% a.m.", "Tendência", "Média")
)
Uma vez definidos os inputs, passamos à construção dos outputs que serão dois gráficos neste caso. Para tal, criamos mais duas linhas: a primeira responsável por criar o gráfico dinâmico que compara a sazonalidade dos dados históricos com um determinado ano, especificado pelo usuário; e a segunda é responsável pelo gráfico dinâmico que mostra alguns componentes da série escolhida.
Veja, por exemplo, que o primeiro gráfico é afetado por mudanças no input referente ao filtro de datas, definição de ano de comparação e o indicador escolhido, sendo assim o script exige essas entradas/definições, utiliza esses valores armazenados para tratamento e cálculos nos dados, e, por fim, gera o gráfico de ggplot2 dinamicamente:
# Gerar gráfico dinâmico (se atualiza conforme o input da sidebar)
shiny::renderPlot({
# Use a função req para exigir que os valores do inputs sejam informados pelo usuário,
# isso evita que o R execute o script "ansiosamente"
shiny::req(
input$data,
input$ano %in% lubridate::year(input$data[1]):lubridate::year(input$data[2]),
input$variavel
)
# Valores dos inputs salvos em objetos auxiliar, por conveniência
data_inicial <- lubridate::floor_date(input$data[1])
data_final <- lubridate::floor_date(input$data[2])
data_compara <- input$ano
indicador <- input$variavel
# Script para calcular padrão sazonal mensal conforme inputs do usuário: mediana e IQR
seas_pattern <- tbl_inflation %>%
dplyr::group_by(
variable,
date_m = lubridate::month(.data$date, label = TRUE, locale = "pt_BR.utf8") %>%
stringr::str_to_sentence(locale = "br") %>%
forcats::as_factor()
) %>%
dplyr::filter(date >= data_inicial & date <= data_final) %>%
dplyr::summarise(
iqr = ggplot2::median_hilow(mom, conf.int = 0.5),
.groups = "drop"
) %>%
tidyr::unnest(cols = iqr) %>%
dplyr::rename("median" = "y", "date" = "date_m") %>%
dplyr::left_join(
tbl_inflation %>%
dplyr::filter(
date >= data_inicial & date <= data_final,
lubridate::year(.data$date) == data_compara
) %>%
dplyr::mutate(
date = lubridate::month(.data$date, label = TRUE, locale = "pt_BR.utf8") %>%
stringr::str_to_sentence(locale = "br") %>%
forcats::as_factor()
),
by = c("variable", "date")
) %>%
tidyr::pivot_longer(
cols = -c(variable, date, ymin, ymax),
names_to = "measure",
values_to = "value"
) %>%
dplyr::mutate(
measure = dplyr::recode(
measure,
"median" = "Mediana",
"mom" = as.character(data_compara)
)
) %>%
dplyr::filter(variable == indicador)
# Gerar gráfico dinâmico
seas_pattern %>%
ggplot2::ggplot() +
ggplot2::aes(x = date, y = value, color = measure, shape = measure, group = measure) +
ggplot2::geom_hline(yintercept = 0) +
ggplot2::geom_ribbon(
ggplot2::aes(
ymin = ymin,
ymax = ymax,
fill = "IQR (CI = 0,5)"
),
alpha = 0.2,
color = NA
) +
ggplot2::geom_line(size = 1.2) +
ggplot2::geom_point(size = 3) +
ggplot2::scale_color_manual(
NULL,
values = c(unname(colors["red"]), unname(colors["black"])),
guide = ggplot2::guide_legend(
override.aes = list(
shape = c(16, NA)
)
)
) +
ggplot2::scale_fill_manual(
NULL,
values = c("IQR (CI = 0,5)" = unname(colors["black"]))
) +
ggplot2::scale_shape_manual(
NULL,
values = c(16, NA)
) +
ggplot2::scale_y_continuous(
breaks = scales::extended_breaks(n = 6),
labels = scales::label_number(decimal.mark = ",", accuracy = 0.01),
minor_breaks = NULL
) +
ggplot2::labs(
title = paste0("**", indicador, "**: padrão sazonal"),
subtitle = paste0(
"% a.m., ",
paste0(
lubridate::year(data_inicial),
"m",
ifelse(
lubridate::month(data_inicial) < 10,
paste0("0", lubridate::month(data_inicial)),
lubridate::month(data_inicial)
),
"-",
lubridate::year(data_final),
"m",
ifelse(
lubridate::month(data_final) < 10,
paste0("0", lubridate::month(data_final)),
lubridate::month(data_final)
)
)
),
x = NULL,
y = NULL,
caption = "**Dados:** FGV e IBGE | **Elaboração:** Fernando da Silva"
) +
ggplot2::theme_light() +
ggplot2::theme(
legend.position = "bottom",
legend.key = ggplot2::element_blank(),
legend.key.width = ggplot2::unit(1, "cm"),
legend.key.height = ggplot2::unit(0.5, "cm"),
legend.text = ggplot2::element_text(size = 12),
plot.title = ggtext::element_markdown(size = 30, colour = colors["blue"]),
plot.subtitle = ggplot2::element_text(size = 16),
plot.caption = ggtext::element_markdown(size = 12),
axis.text = ggplot2::element_text(size = 12),
strip.background = ggplot2::element_blank(),
strip.text = ggplot2::element_text(size = 12, face = "bold", colour = colors["black"])
)
})
Após gerar os elementos visuais, utilize o botão Run Document no RStudio para visualizar o resultado, ou seja, a dashboard propriamente dita.
Os últimos passos envolvem fazer o deploy da dashboard e automatizar a coleta inicial de dados. Consulte as referências inicias para orientação sobre o assunto.
___________________
(*) Para aprofundamento e detalhes confira o Curso de Análise de Conjuntura usando o R.


